by Contributed | Apr 13, 2021 | Technology
This article is contributed. See the original author and article here.
Getting started with Video Indexer v2 API
Itai Norman Program Manager, AEDPLS, Video Indexer.
Video Indexer is an Azure service, that enables you to easily extracts business insights from your media files by using around 30 AI models. Using this service, you can enrich your videos with meta-data, transcription, and translation to more the 50 different languages, search in videos for faces, people, topics, spoken words, and much more.
Video Indexer can be leveraged in three ways: via a REST API, via a full flagged portal experience, and via embeddable customizable widgets, that enable customers to leverage the portal experience in their own applications. In this blog we will focus on how to get to know and get started with the Video Indexer REST API easily, using our brand-new developer portal! Via this portal, you can explore and try out all different APIs, find code samples and easily navigate between all Video Indexer’s communities and documentation resources.
In this blog, I will walk you through few basic steps:
First thing first – get a Video Indexer account
Before starting to use Video Indexer’s REST API, you should have a Video Indexer account, you can start with a free trial account; Just sign-in with one of the following: AAD account, Personal Microsoft account, or a Google account and you are good to go!
Alternatively, you can get connected to your own Azure Subscription. If someone to their Video Indexer account, you could use that account as well.

Register to Video Indexer’s API
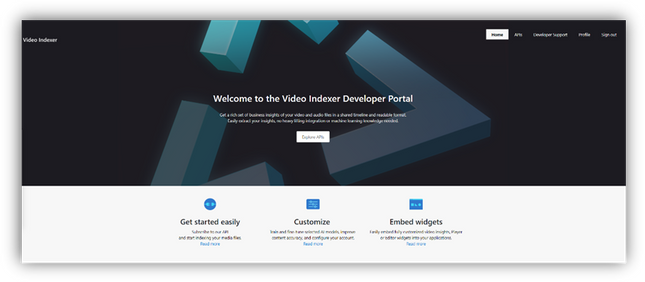
Now we are ready to start using the Video Indexer developer portal. You will be welcomed with the Video Indexer developer portal landing page, just press the ‘Sign-in’ button on the top-right corner of the ‘Get Started’ button, to authenticate. When the authentication process is finished you will be connected to the developer-portal as a signed-in user, and you will see the following tabs in your top-right menu: ‘Home’, ’APIs’, ’Developer Support’, ‘Profile’, ’Sign out’.
Getting familiar with the developer portal
Before moving to an example of using Video Indexer’s API, let’s briefly explore what’s available for you in the portal.
The first tab is the APIs tab. It has a list of all APIs calls in VI’s environment, by choosing an API call you will get a sample of how the request would look like, a documentation table, and an option to try the API call through the portal.
On the ‘try it’ blade you will be able to enter the relevant parameters and get a glance at what would the API call and response look like.

In the Home tab, you can find links to our documentation around main functionalities such as model customization and how to embed widgets. A three easy steps guide, on how to use Video Indexer’s API and a short code sample.
The Developer support page includes everything you need to learn about and get support for: GitHub repository, Stackoverflow page, ‘CodePen’ link with widgets code samples, and Video Indexer’s tech community relevant blog posts. Also available in the developer support, Video Indexer’s FAQ page, a ‘User Voice’, where you can suggest Video indexer capabilities and features that may be helpful for your business needs, and a general documentation link.

Using the API
This is really what we are here for, right? So, let’s see how to start using the VI API…
Getting the account id and access token.
In this section, I’ll walk you through the basic flow that lets you get media insights from Video Indexer, with only three calls: Getting an ‘AccountId’ and ‘Access Token’, uploading a file and retrieving the insight JSON file, and I’ll use the developer portal to do so.
First, open the developer portal, under the ‘APIs’ tab go to the ‘Get Accounts Authorization’.

Enter the query parameters:
- Location – ‘trial’ (or for non-trial account enter the region for your account)
- Generate Access Token: true.
At the bottom of the ‘Try it’ blade hit ‘Send’.

You should receive a 200 ok response with the appropriate data.

Open a Notepad or similar app to keep the different values of the response, you will need it in a minute… form the response save the: ‘Id’ which is the ‘Account Id’, and the ‘Access Token’.
Upload video

Now we have everything we need to upload the first video. Go to ‘Upload video’
enter the query parameters:
- Location: ‘trial’ (For non-trial account enter the region e.g. “eastus”).
- AccountId: GUID you received it in your ‘Get Accounts Authorization’.
- Name: give the video a name.
- VideoUrl: The full path of the video you want to upload, note, that video Indexer support a wide range of video and audio file formats, but it has to be a URL for a file (and not a HTTP link for example)
- Access Token: the ‘Access Token’ we got at the previous step.
, and hit ‘Send’.
Form the ‘upload video’ response fetch the ‘id’ – which is the Video Indexer id for the file you just uploaded. We will need it in the next step.
Getting Insights
Once the indexing completed (which might take a few minutes), we can use the third call, to see what Video Indexer was able to extract. Go to ‘Get Video Index’

enter the query parameters:
- Location – ‘trial’ (For non-trial account enter the region e.g. “eastus”).
- AccountId: GUID you received it in your ‘Get Accounts Authorization’.
- VideoId: we received from the last API call.
- Access Token: the ‘Access Token’ we got at the previous step.
, and hit ‘Send’.
And Walla… all the insights will be returned in a Json format file.

Congratulations! you just got your first set of insights in a readable JSON format.
So, what’s next?
Use these relevant articles to learn more on how to use Video Indexer:
Use these links to read more technical articles around Video Indexer:

by Contributed | Apr 13, 2021 | Technology
This article is contributed. See the original author and article here.
* The blog was first published at December 2019 by Anika Zaman in Azure blogs
We are pleased to introduce the ability to export high-resolution keyframes from Azure Media Service’s Video Indexer. Whereas keyframes were previously exported in reduced resolution compared to the source video, high resolution keyframes extraction gives you original quality images and allows you to make use of the image-based artificial intelligence models provided by the Microsoft Computer Vision and Custom Vision services to gain even more insights from your video. This unlocks a wealth of pre-trained and custom model capabilities. You can use the keyframes extracted from Video Indexer, for example, to identify logos for monetization and brand safety needs, to add scene description for accessibility needs or to accurately identify very specific objects relevant for your organization, like identifying a type of car or a place.
Let’s look at some of the use cases we can enable with this new introduction.
Using keyframes to get image description automatically
You can automate the process of “captioning” different visual shots of your video through the image description model within Computer Vision, in order to make the content more accessible to people with visual impairments. This model provides multiple description suggestions along with confidence values for an image. You can take the descriptions of each high-resolution keyframe and stitch them together to create an audio description track for your video.
Pic 1: An example of using the image description model to create a description of a high resolution key frame.
Using Keyframes to get logo detection
While Video Indexer detects brands in speech and visual text, it does not support brands detection from logos yet. Instead, you can run your keyframes through Computer Vision’s logo-based brands detection model to detect instances of logos in your content.
This can also help you with brand safety as you now know and can control the brands showing up in your content. For example, you might not want to showcase the logo of a company directly competing with yours. Also, you can now monetize on the brands showing up in your content through sponsorship agreements or contextual ads.
Furthermore, you can cross-reference the results of this model for you keyframe with the timestamp of your keyframe to determine when exactly a logo is shown in your video and for how long. For example, if you have a sponsorship agreement with a content creator to show your logo for a certain period of time in their video, this can help determine if the terms of the agreement have been upheld.
Computer Vision’s logo detection model can detect and recognize thousands of different brands out of the box. However, if you are working with logos that are specific to your use case or otherwise might not be a part of the out of the box logos database, you can also use Custom Vision to build a custom object detector and essentially train your own database of logos by uploading and correctly labeling instances of the logos relevant to you.

Pic 2: An example of log detection using Computer Vision’s logo-based brands detection
Using keyframes with other Computer Vision and Custom Vision offerings
The Computer Vision APIs provide different insights in addition to image description and logo detection, such as object detection, image categorization, and more. The possibilities are endless when you use high-resolution keyframes in conjunction with these offerings.
For example, the object detection model in Computer Vision gives bounding boxes for common out of the box objects that are already detected as part of Video Indexer today. You can use these bounding boxes to blur out certain objects that don’t meet your standards.

Pic 3: An example of object detection model in Computer Vision applied on a high resolution key frame
High-resolution keyframes in conjunction with Custom Vision can be leveraged to achieve many different custom use cases. For example, you can train a model to determine what type of car (or even what breed of cat) is showing in a shot. Maybe you want to identify the location or the set where a scene was filmed for editing purposes. If you have objects of interest that may be unique to your use case, use Custom Vision to build a custom classifier to tag visuals or a custom object detector to tag and provide bounding boxes for visual objects.
Try it for yourself
These are just a few of the new opportunities enabled by the availability of high-resolution keyframes in Video Indexer. Now, it is up to you to get additional insights from your video by taking the keyframes from Video Indexer and running additional image processing using any of the Vision models we have just discussed. You can start doing this by first uploading your video to Video Indexer and taking the high-resolution keyframes after the indexing job is complete and second creating an account and getting started with the Computer Vision API and Custom Vision.
Have questions or feedback? We would love to hear from you. Use our UserVoice page to help us prioritize features, leave a comment below or email VISupport@Microsoft.com for any questions.
by Contributed | Apr 13, 2021 | Technology
This article is contributed. See the original author and article here.
Welcome back to the Security Controls in Azure Security Center blog series! This time we are here to talk about the security control: Implement security best practices.
Keeping your resources safe is a joint effort between your cloud provider, Azure, and you, the customer. You have to make sure your workloads are secure as you move to the cloud, and at the same time, when you move to IaaS (infrastructure as a service) there is more customer responsibility than there was in PaaS (platform as a service), and SaaS (software as a service). Azure Security Center provides you the tools needed to harden your network, secure your services and make sure you’re on top of your security posture.
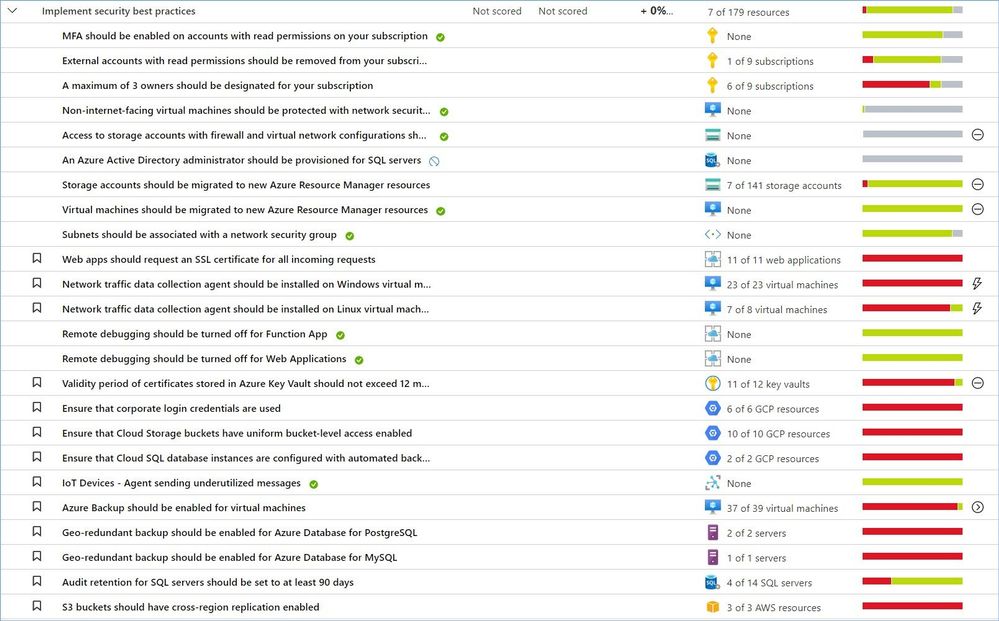
“Implement security best practices” is the largest control that includes more than 50 recommendations covering resources in Azure, AWS, GCP and on-premises. This list constantly gets updated as our teams add new resources and discover new attack technics, vulnerabilities, and risky misconfigurations.
As of this writing (April 2021) this control does not affect your Secure Score, but this does not mean that you want to ignore or shelve these recommendations.
Just a reminder, recommendations flagged as “Preview” are not included in the calculation of your Secure Score. However, they should still be remediated wherever possible, so that when the preview period ends, they will contribute towards your score.
Azure Security Center provides a comprehensive description, manual remediation steps, additional helpful information, and a list of affected resources for all recommendations.
Some of the recommendations might have a “Quick Fix!” option that allows you to quickly remediate the issue. In such cases we also provide “View remediation logic” option so that you can review what happens behind the scenes when you click the “Remediate” button, for instance:

In addition, you may use the remediation scripts for your own automations/templates to avoid similar issues in the future. You can also find some remediation scripts in our GitHub Repository.
Let’s now review the most common recommendations from this security control that can be grouped into the following categories:
Category #1: App Services recommendations.
Keep your software up to date.
Keeping software up to date is one of the top security practices you need to implement to make sure your systems are not vulnerable to known threats. Out of date or not regularly updated operating systems and applications put you at risk because they have a lot of vulnerabilities. Many of these vulnerabilities can be easily detected and exploited by threat actors.
Periodically, newer versions are released for software either due to security flaws or to include additional functionality. Using the latest version of PHP/Java/Python/.NET/Node/Ruby for web/function/api apps is recommended to benefit from security fixes, if any, and/or new functionalities of the latest version.
The following recommendations are part of this sub-category:
- Java should be updated to the latest version for your web app
- Java should be updated to the latest version for your API app
- Java should be updated to the latest version for your function app
- Python should be updated to the latest version for your web app
- Python should be updated to the latest version for your API app
- Python should be updated to the latest version for your function app
- PHP should be updated to the latest version for your web app
- Python should be updated to the latest version for your API app
- Python should be updated to the latest version for your function app
The manual remediation steps for these recommendations are:
- Navigate to Azure App Service
- Go to Configuration/General settings
- Select the latest stack version in the drop-down menu.

Implement Azure App Service best practices.
The following recommendations are part of this sub-category:
- Remote debugging should be turned off for API App
- Remote debugging should be turned off for Function App
- Remote debugging should be turned off for Web Applications
- Web apps should request an SSL certificate for all incoming requests
The manual remediation steps for these recommendations are:
- Navigate to Azure App Service
- Go to Configuration/General settings
- Make recommended changes.
Learn more about best practices for securing Azure App Services here.
Category #2: Identity and access recommendations.
Secure your Azure Key Vaults.
You use Azure Key Vault to protect encryption keys and secrets like certificates, connection strings, and passwords in the cloud. When storing sensitive and business critical data, you need to take steps to maximize the security of your vaults and the data stored in them.
The following recommendations are part of this sub-category:
- Key Vault keys should have an expiration date.
- Key Vault secrets should have an expiration date.
- Key vaults should have purge protection enabled.
- Key vaults should have soft delete enabled.
- Validity period of certificates stored in Azure Key Vault should not exceed 12 months.
Learn more about Azure Key Vault security here.
Protect your Azure Subscriptions.
To reduce the potential for breaches by compromised owner accounts, it is recommended to limit the number of owner accounts to as few as necessary and require two-step verification for all users.
The following recommendations are part of this sub-category:
- A maximum of 3 owners should be designated for your subscription.
- External accounts with read permissions should be removed from your subscription.
- MFA should be enabled on accounts with read permissions on your subscription
Configure notification settings.
To ensure the relevant people in your organization are notified when there is a potential security breach in one of your subscriptions, enable email notifications for high severity alerts in Security Center.
The following recommendations are part of this sub-category:
- Email notification to subscription owner for high severity alerts should be enabled.
- Email notification for high severity alerts should be enabled.
- Subscriptions should have a contact email address for security issues.
The manual remediation steps for these recommendations are:
- From Security Center’s menu, select Pricing & settings.
- Select the relevant subscription.
- Select ‘Email notifications’.
- Enter the email recipients to receive notifications from Security Center.
- In the ‘Notification type’ area, ensure mails are sent regarding security alerts from severity ‘high’.
- Select ‘Save’.

Learn more about Azure Identity Management and Access Control security best practices here.
Category #3: Compute recommendations.
In most infrastructure as a service (IaaS) scenarios, Azure virtual machines (VMs) are the main workload for organizations that use cloud computing. This fact is evident in hybrid scenarios where organizations want to slowly migrate workloads to the cloud. In such scenarios, follow the general security considerations for IaaS, and apply security best practices to all your VMs.
The following recommendations are part of this category:
- Azure Backup should be enabled for virtual machines.
- Auto provisioning of the Log Analytics agent should be enabled on your subscription.
Azure Security Center provides description, manual remediation steps and additional information for every recommendation in this category, e.g.:

Auto provisioning reduces management overhead by installing all required agents and extensions on existing – and new – machines to ensure faster security coverage for all supported resources. We recommend enabling auto provisioning, but it’s disabled by default.
Learn more about securing IaaS workloads in Azure here.
Category #4: Data recommendations.
To help protect data in the cloud, you need to account for the possible states in which your data can occur, and what controls are available for that state. Best practices for Azure data security and encryption relate to the following data states:
- At rest: This includes all information storage objects, containers, and types that exist statically on physical media, whether magnetic or optical disk.
- In transit: When data is being transferred between components, locations, or programs, it’s in transit. Examples are transfer over the network, across a service bus (from on-premises to cloud and vice-versa, including hybrid connections such as ExpressRoute), or during an input/output process.
The following recommendations are part of this category:
- All advanced threat protection types should be enabled in SQL managed instance advanced data security settings.
- All advanced threat protection types should be enabled in SQL server advanced data security settings.
- An Azure Active Directory administrator should be provisioned for SQL servers.
- Audit retention for SQL servers should be set to at least 90 days.
- Azure Cosmos DB accounts should have firewall rules.
- Cognitive Services accounts should enable data encryption.
- Cognitive Services accounts should restrict network access.
- Cognitive Services accounts should use customer owned storage or enable data encryption.
- Geo-redundant backup should be enabled for Azure Database for MariaDB.
- Geo-redundant backup should be enabled for Azure Database for MySQL.
- Geo-redundant backup should be enabled for Azure Database for PostgreSQL.
- Public network access on Azure SQL Database should be disabled.
- Private endpoint connections on Azure SQL Database should be enabled.
Azure Security Center provides description, manual remediation steps and additional information for every recommendation in this category, e.g.:

Learn more about:
- Azure data security here.
- Securing Azure SQL Database and SQL Managed Instances here.
- Cognitive Services security here.
Category #5: IoT recommendations.
Securing an Internet of Things (IoT) infrastructure requires a rigorous security-in-depth strategy. This strategy requires you to secure data in the cloud, protect data integrity while in transit over the public internet, and securely provision devices. Each layer builds greater security assurance in the overall infrastructure.
The following recommendations are part of this category:
- IoT Devices – Auditd process stopped sending events.
- IoT Devices – Operating system baseline validation failure.
- IoT Devices – TLS cipher suite upgrade needed.
- IoT Devices – Open Ports on Device.
- IoT Devices – Permissive firewall policy in one of the chains was found.
- IoT Devices – Permissive firewall rule in the input chain was found.
- IoT Devices – Permissive firewall rule in the output chain was found.
- IoT Devices – Agent sending underutilized messages.
- IoT Devices – Default IP Filter Policy should be Deny.
- IoT Devices – IP Filter rule large IP range.
- IoT Devices – Agent message intervals and size should be adjusted.
- IoT Devices – Identical Authentication Credentials.
- IoT Devices – Audited process stopped sending events.
- IoT Devices – Operating system (OS) baseline configuration should be fixed.
- Diagnostic logs in IoT Hub should be enabled.
Learn more about securing an Internet of Things (IoT) infrastructure here.
Category #6: Networking recommendations.
Network security could be defined as the process of protecting resources from unauthorized access or attack by applying controls to network traffic. The goal is to ensure that only legitimate traffic is allowed. Azure includes a robust networking infrastructure to support your application and service connectivity requirements. Network connectivity is possible between resources located in Azure, between on-premises and Azure hosted resources, and to and from the internet and Azure.
The following recommendations are part of this category:
- Network traffic data collection agent should be installed on Linux virtual machines.
- Network traffic data collection agent should be installed on Windows virtual machines.
- Network Watcher should be enabled.
- Non-internet-facing virtual machines should be protected with network security groups.
- Subnets should be associated with a network security group.
- Access to storage accounts with firewall and virtual network configurations should be restricted.
Azure Security Center provides description, manual remediation steps and additional information for every recommendation in this category, e.g.:

Learn more about Azure best practices for network security here.
Category #7: AWS and GCP recommendations.
Azure Security Center protects workloads in Azure, Amazon Web Services (AWS), and Google Cloud Platform (GCP).
Onboarding your AWS and/or GCP accounts into Security Center, integrates AWS Security Hub or GCP Security Command Center with Azure Security Center. Security Center thus provides visibility and protection across these cloud environments:
- Detection of security misconfigurations.
- A single view showing Security Center recommendations and AWS/GCP security findings.
- Incorporation of your AWS/GCP resources into Security Center’s secure score calculations.
- Regulatory compliance assessments of your AWS/GCP resources.
Azure Security Center provides description, manual remediation steps and additional information for every recommendation, e.g.:

Note: Microsoft is actively partnering with other cloud providers to expand ASC coverage and provide its customers with comprehensive visibility across and protection for their multi-cloud environments. A list of supported providers and security insights ASC pulling from those cloud continues to grow, so please expect to see the number of recommendations in this category to increase as we progress.
Worth mentioning that some recommendation might have the “Deny” or “Enforce” option that allows you to prevent creation of potentially insecure or incompliant resources, for instance:

Reference:
Microsoft Security Best Practices
Azure security best practices and patterns
Top 10 Best Practices for Azure Security
Security controls and their recommendations
Security recommendations – a reference guide
Recommendations with deny/enforce options
P.S. Consider joining our Tech Community where you can be one of the first to hear the latest Azure Security Center news, announcements and get your questions answered by Azure Security experts.
Reviewers:
@Yuri Diogenes, Principal Program Manager, ASC CxE
@Tom_Janetscheck, Senior Program Manager, ASC CxE

by Contributed | Apr 13, 2021 | Technology
This article is contributed. See the original author and article here.
We are excited to announce Azure Storage Day, a free digital event on April 29, 2021, where you can explore cloud storage solutions for all your enterprise workloads. Join us to:
- Understand cloud storage trends and innovations—and plan for the future.
- Map Azure Storage solutions to your different enterprise workloads.
- See demos of Azure disk, object, and file storage services.
- Learn how to optimize your migration with best practices.
- Find out how real customers are accelerating their cloud adoption with Azure Storage.
- Get answers to your storage questions from product experts.
This digital event is your opportunity to engage with the cloud storage community, see Azure Storage solutions in action, and discover how to build a foundation for all of your enterprise workloads at every stage of your digital transformation.
The need for reliable cloud storage has never been greater. More companies are investing in digital transformation to become more resilient and agile in order to better serve their customers. The rapid pace of digital transformation has resulted in exponential data growth, driving up demand for dependable and scalable cloud data storage services.
Register here.
Hope to see you there!
– Azure Storage Marketing Team
by Scott Muniz | Apr 13, 2021 | Security, Technology
This article is contributed. See the original author and article here.
SAP has released security updates to address vulnerabilities affecting multiple products. An attacker could exploit some of these vulnerabilities to take control of an affected system.
CISA encourages users and administrators to review the SAP Security Notes for April 2021 and apply the necessary updates.
by Contributed | Apr 13, 2021 | Technology
This article is contributed. See the original author and article here.
Initial Update: Tuesday, 13 April 2021 20:59 UTC
We are aware of issues within Log Analytics and are actively investigating.
Customers ingesting telemetry in their Log Analytics Workspace in West Europe geographical region may have experienced intermittent data latency and incorrect alert activation.
- Work Around: None
- Next Update: Before 04/13 23:00 UTC
We are working hard to resolve this issue and apologize for any inconvenience.
-Eric Singleton
by Contributed | Apr 13, 2021 | Technology
This article is contributed. See the original author and article here.
Since our announcements for Microsoft Viva and SharePoint Syntex over the past months, we’ve seen great energy and enthusiasm from our partners to help support our vision to reimagine employee experience in Microsoft 365.
To help all partners succeed, we’ve created the Employee Experience Partner Resource Center. It provides you with one place to go to find out about events and trainings and access self-service demos, learning paths, sales assets, and additional resources related to Microsoft Viva and SharePoint Syntex.
These resources are being shared broadly so you can accelerate development of your employee experience practice. Visit the Employee Experience Partner Resource Center or read on to learn more about how you can:
- Register for the Microsoft Viva: Fundamentals for Partners training
- Join us at the AIIM Conference 2021
- Create a new on-demand demo tenant for Microsoft Viva
- Start on the new Microsoft Viva Topics learning paths
- Check out available self-service resources, including pitch decks, white papers, workshops, and more
Microsoft Viva: Fundamentals for Partners (Training)
Join us for the Microsoft Viva: Fundamentals for Partners training event to learn about the value of Microsoft Viva, an Employee Experience Platform (EXP), and the opportunities for partners.
From customer experience – to business opportunity – to technical solutions, this three-part training offers an essential introduction. Register now for any or all the sessions in your preferred time zone.
- April 26 – 28, 2021, 8:30-11:30 am PT (Americas)
- May 10 – 12, 2021, 8:30-11:30 pm PT (APAC)
- May 11 – 13, 2021, 2:00-5:00 am PT (EMEA)
AIIM Conference 2021
Join Microsoft 365 and the global information management community at the AIIM Conference 2021: A Galactic Digital Experience, April 27-29. Enjoy $50 off your registration with code: MICROSOFT.
We’re over the moon to be an Elite Sponsor of the conference. Connect with us at our keynote, sessions, and booth.
New CDX on-demand tenants for demo
Now available – CDX (Customer Digital Experiences) on-demand demo tenants for Microsoft Viva and SharePoint Syntex! The Microsoft Viva tenant type (at the bottom of the tenant type list) is based on the Microsoft 365 E5 Enterprise demo, and contains licensing and content for Viva Connections, Viva Topics, and SharePoint Syntex.
Also available are Microsoft Viva Topics demo card and SharePoint Syntex demo card, with guidance and additional content. The Viva Connections demo card will be available next week.
Demand for the demo tenants has been extremely high and we’re working to add more tenant inventory. If you get a “running low due to high demand” error, please be patient and check back on another day.
New Microsoft Viva Topics learning paths
We’re excited to release our first learning paths for Microsoft Viva Topics, which helps you put knowledge to work. Going live in late April 2021, these learning paths help solutions architects and administrators get their organizations started with Viva Topics and provide them with an overview of IT skills planning and learning for Viva Topics.
Self-service resources
Below is a selection of the self-service resources that you can use today to start adding Microsoft Viva & SharePoint Syntex to your offerings. You can use the sales assets freely to frame initial customer conversations, hold in-depth workshops, and provide more detailed thought leadership to customers.
Pitch decks
Microsoft Viva pitch deck
Knowledge customer pitch deck
SharePoint Syntex pitch deck
White papers
Forrester New Technology: The Projected Total Economic Impact of Microsoft 365 Knowledge & Content Services
Spiceworks/ZD Knowledge Sharing in a Changing World
Growing organizational intelligence with knowledge and content in Microsoft 365
Workshops
Knowledge Discovery Workshop (download .zip)
Insights Discovery Workshop on the Insights practice page on Transform
Intelligent Intranet envisioning workshop page
Partner practice pages
Employee Experience practice page on Transform (Microsoft Viva pitch deck, demos, and other partner resources)
Knowledge practice page on Transform (Microsoft Viva Topics pitch deck, SharePoint Syntex pitch deck)
Insights practice page on Transform (Microsoft Viva Insights partner resources, including the Insights Discovery Workshop)
Additional resources
Employee Experience practice page (Partners)
Microsoft Viva product page (Customers)
Viva Topics Resource Center (Customers)
SharePoint Syntex Resource Center (Customers)
Microsoft Content Services Partner Program
Visit the Microsoft Viva page and Microsoft Viva blog to learn more.
by Contributed | Apr 13, 2021 | Technology
This article is contributed. See the original author and article here.
Automatic Paper Analysis
Automatic scientific paper analysis is fast growing area of studies, and due to recent improvements in NLP techniques is has been greatly improved in the recent years. In this post, we will show you how to derive specific insights from COVID papers, such as changes in medical treatment over time, or joint treatment strategies using several medications:
The main idea the approach I will describe in this post is to extract as much semi-structured information from text as possible, and then store it into some NoSQL database for further processing. Storing information in the database would allow us to make some very specific queries to answer some of the questions, as well as to provide visual exploration tool for medical expert for structured search and insight generation. The overall architecture of the proposed system is shown below:
We will use different Azure technologies to gain insights into the paper corpus, such as Text Analytics for Health, CosmosDB and PowerBI. Now let’s focus on individual parts of this diagram and discuss them in detail.
If you want to experiment with text analytics yourself – you will need an Azure Account. You can always get free trial if you do not have one. And you may also want to check out other AI technologies for developers
COVID Scientific Papers and CORD Dataset
The idea to apply NLP methods to scientific literature seems quite natural. First of all, scientific texts are already well-structured, they contain things like keywords, abstract, as well as well-defined terms. Thus, at the very beginning of COVID pandemic, a research challenge has been launched on Kaggle to analyze scientific papers on the subject. The dataset behind this competition is called CORD (publication), and it contains constantly updated corpus of everything that is published on topics related to COVID. Currently, it contains more than 400000 scientific papers, about half of them – with full text.
This dataset consists of the following parts:
- Metadata file Metadata.csv contains most important information for all publications in one place. Each paper in this table has unique identifier
cord_uid (which in fact does not happen to be completely unique, once you actually start working with the dataset). The information includes:
- Title of publication
- Journal
- Authors
- Abstract
- Data of publication
- doi
- Full-text papers in
document_parses directory, than contain structured text in JSON format, which greatly simplifies the analysis.
- Pre-built Document Embeddings that maps
cord_uids to float vectors that reflect some overall semantics of the paper.
In this post, we will focus on paper abstracts, because they contain the most important information from the paper. However, for full analysis of the dataset, it definitely makes sense to use the same approach on full texts as well.
What AI Can Do with Text?
In the recent years, there has been a huge progress in the field of Natural Language Processing, and very powerful neural network language models have been trained. In the area of NLP, the following tasks are typically considered:
- Text classification / intent recognition
- In this task, we need to classify a piece of text into a number of categories. This is a typical classification task. Sentiment Analysis
- We need to return a number that shows how positive or negative the text is. This is a typical regression task. Named Entity Recognition (NER)
- In NER, we need to extract named entities from text, and determine their type. For example, we may be looking for names of medicines, or diagnoses. Another task similar to NER is keyword extraction.
- Text summarization
- Here we want to be able to produce a short version of the original text, or to select the most important pieces of text.
- Question Answering
- In this task, we are given a piece of text and a question, and our goal is to find the exact answer to this question from text.
- Open-Domain Question Answering (ODQA)
- The main difference from previous task is that we are given a large corpus of text, and we need to find the answer to our question somewhere in the whole corpus.
In one of my previous posts, I have described how we can use ODQA approach to automatically find answers to specific COVID questions. However, this approach is not suitable for serious research.
To make some insights from text, NER seems to be the most prominent technique to use. If we can understand specific entities that are present in text, we could then perform semantically rich search in text that answers specific questions, as well as obtain data on co-occurrence of different entities, figuring out specific scenarios that interest us.
To train NER model, as well as any other neural language model, we need a reasonably large dataset that is properly marked up. Finding those datasets is often not an easy task, and producing them for new problem domain often requires initial human effort to mark up the data.
Pre-Trained Language Models
Luckily, modern transformer language models can be trained in semi-supervised manner using transfer learning. First, the base language model (for example, BERT) is trained on a large corpus of text first, and then can be specialized to a specific task such as classification or NER on a smaller dataset.
This transfer learning process can also contain additional step – further training of generic pre-trained model on a domain-specific dataset. For example, in the area of medical science Microsoft Research has pre-trained a model called PubMedBERT (publication), using texts from PubMed repository. This model can then be further adopted to different specific tasks, provided we have some specialized datasets available.
Text Analytics Cognitive Services
However, training a model requires a lot of skills and computational power, in addition to a dataset. Microsoft (as well as some other large cloud vendors) also makes some pre-trained models available through the REST API. Those services are called Cognitive Services, and one of those services for working with text is called Text Analytics. It can do the following:
- Keyword extraction and NER for some common entity types, such as people, organizations, dates/times, etc.
- Sentiment analysis
- Language Detection
- Entity Linking, by automatically adding internet links to some most common entities. This also performs disambiguation, for example Mars can refer to both the planet or a chocolate bar, and correct link would be used depending on the context.
For example, let’s have a look at one medical paper abstract analyzed by Text Analytics:

As you can see, some specific entities (for example, HCQ, which is short for hydroxychloroquine) are not recognized at all, while others are poorly categorized. Luckily, Microsoft provides special version of Text Analytics for Health.
Text Analytics for Health
Text Analytics for Health is a cognitive service that exposes pre-trained PubMedBert model with some additional capabilities. Here is the result of extracting entities from the same piece of text using Text Analytics for Health:

Currently, Text Analytics for Health is available as gated preview, meaning that you need to request access to use it in your specific scenario. This is done according to Ethical AI principles, to avoid irresponsible usage of this service for cases where human health depends on the result of this service. You can request access here.
To perform analysis, we can use recent version Text Analytics Python SDK, which we need to pip-install first:
pip install azure.ai.textanalytics==5.1.0b5
Note: We need to specify a version of SDK, because otherwise we can have current non-beta version installed, which lacks Text Analytics for Health functionality.
The service can analyze a bunch of text documents, up to 10 at a time. You can pass either a list of documents, or dictionary. Provided we have a text of abstract in txt variable, we can use the following code to analyze it:
poller = text_analytics_client.begin_analyze_healthcare_entities([txt])
res = list(poller.result())
print(res)
This results in the following object:
[AnalyzeHealthcareEntitiesResultItem(
id=0, entities=[
HealthcareEntity(text=2019, category=Time, subcategory=None, length=4, offset=20, confidence_score=0.85, data_sources=None,
related_entities={HealthcareEntity(text=coronavirus disease pandemic, category=Diagnosis, subcategory=None, length=28, offset=25, confidence_score=0.98, data_sources=None, related_entities={}): ‘TimeOfCondition’}),
HealthcareEntity(text=coronavirus disease pandemic, category=Diagnosis, subcategory=None, length=28, offset=25, confidence_score=0.98, data_sources=None, related_entities={}),
HealthcareEntity(text=COVID-19, category=Diagnosis, subcategory=None, length=8, offset=55, confidence_score=1.0,
data_sources=[HealthcareEntityDataSource(entity_id=C5203670, name=UMLS), HealthcareEntityDataSource(entity_id=U07.1, name=ICD10CM), HealthcareEntityDataSource(entity_id=10084268, name=MDR), …
As you can see, in addition to just the list of entities, we also get the following:
- Enity Mapping of entities to standard medical ontologies, such as UMLS.
- Relations between entities inside the text, such as
TimeOfCondition, etc.
- Negation, which indicated that an entity was used in negative context, for example COVID-19 diagnosis did not occur.

In addition to using Python SDK, you can also call Text Analytics using REST API directly. This is useful if you are using a programming language that does not have a corresponding SDK, or if you prefer to receive Text Analytics result in the JSON format for further storage or processing. In Python, this can be easily done using requests library:
uri = f"{endpoint}/text/analytics/v3.1-preview.3/entities/
health/jobs?model-version=v3.1-preview.4"
headers = { "Ocp-Apim-Subscription-Key" : key }
resp = requests.post(uri,headers=headers,data=doc)
res = resp.json()
if res['status'] == 'succeeded':
result = t['results']
else:
result = None
(We need to make sure to use the preview endpoint to have access to text analytics for health)
Resulting JSON file will look like this:
{"id": "jk62qn0z",
"entities": [
{"offset": 24, "length": 28, "text": "coronavirus disease pandemic",
"category": "Diagnosis", "confidenceScore": 0.98,
"isNegated": false},
{"offset": 54, "length": 8, "text": "COVID-19",
"category": "Diagnosis", "confidenceScore": 1.0, "isNegated": false,
"links": [
{"dataSource": "UMLS", "id": "C5203670"},
{"dataSource": "ICD10CM", "id": "U07.1"}, ... ]},
"relations": [
{"relationType": "Abbreviation", "bidirectional": true,
"source": "#/results/documents/2/entities/6",
"target": "#/results/documents/2/entities/7"}, ...],
}
Note: In production, you may want to incorporate some code that will retry the operation when an error is returned by the service. For more guidance on proper implementation of cognitive services REST clients, you can check source code of Azure Python SDK, or use Swagger to generate client code.
Using Cosmos DB to Store Analysis Result
Using Python code similar to the one above we can extract JSON entity/relation metadata for each paper abstract. This process takes quite some time for 400K papers, and to speed it up it can be parallelized using technologies such as Azure Batch or Azure Machine Learning. However, in my first experiment I just run the script on one VM in the cloud, and the data was ready in around 11 hours.

Having done this, we have now obtained a collection of papers, each having a number of entities and corresponding relations. This structure is inherently hierarchical, and the best way to store and process it would be to use NoSQL approach for data storage. In Azure, Cosmos DB is a universal database that can store and query semi-structured data like our JSON collection, thus it would make sense to upload all JSON files to Cosmos DB collection. This can be done using the following code:
coscli = azure.cosmos.CosmosClient(cosmos_uri, credential=cosmos_key)
cosdb = coscli.get_database_client("CORD")
cospapers = cosdb.get_container_client("Papers")
for x in all_papers_json:
cospapers.upsert_item(x)
Here, all_papers_json is a variable (or generator function) containing individual JSON documents for each paper. We also assume that you have created a Cosmos DB database called ‘CORD’, and obtained required credentials into cosmos_uri and cosmos_key variables.
After running this code, we will end up with the container Papers will all metadata. We can now work with this container in Azure Portal by going to Data Explorer:

Now we can use Cosmos DB SQL in order to query our collection. For example, here is how we can obtain the list of all medications found in the corpus:
-- unique medication names
SELECT DISTINCT e.text
FROM papers p
JOIN e IN p.entities
WHERE e.category='MedicationName'
Using SQL, we can formulate some very specific queries. Suppose, a medical specialist wants to find out all proposed dosages of a specific medication (say, hydroxychloroquine), and see all papers that mention those dosages. This can be done using the following query:
-- dosage of specific drug with paper titles
SELECT p.title, r.source.text
FROM papers p JOIN r IN p.relations
WHERE r.relationType='DosageOfMedication'
AND CONTAINS(r.target.text,'hydro')
You can execute this query interactively in Azure Portal, inside Cosmos DB Data Explorer. The result of the query looks like this:
[
{
"title": "In Vitro Antiviral Activity and Projection of Optimized Dosing Design of Hydroxychloroquine for the Treatment of Severe Acute Respiratory Syndrome Coronavirus 2 (SARS-CoV-2)",
"text": "400 mg"
},{
"title": "In Vitro Antiviral Activity and Projection of Optimized Dosing Design of Hydroxychloroquine for the Treatment of Severe Acute Respiratory Syndrome Coronavirus 2 (SARS-CoV-2)",
"text": "maintenance dose"
},...]
A more difficult task would be to select all entities together with their corresponding ontology ID. This would be extremely useful, because eventually we want to be able to refer to a specific entity (hydroxychloroquine) regardless or the way it was mentioned in the paper (for example, HCQ also refers to the same medication). We will use UMLS as our main ontology.
--- get entities with UMLS IDs
SELECT e.category, e.text,
ARRAY (SELECT VALUE l.id
FROM l IN e.links
WHERE l.dataSource='UMLS')[0] AS umls_id
FROM papers p JOIN e IN p.entities
Creating Interactive Dashboards
While being able to use SQL query to obtain an answer to some specific question, like medication dosages, seems like a very useful tool – it is not convenient for non-IT professionals, who do not have high level of SQL mastery. To make the collection of metadata accessible to medical professionals, we can use PowerBI tool to create an interactive dashboard for entity/relation exploration.

In the example above, you can see a dashboard of different entities. One can select desired entity type on the left (eg. Medication Name in our case), and observe all entities of this type on the right, together with their count. You can also see associated UMLS IDs in the table, and from the example above once can notice that several entities can refer to the same ontology ID (hydroxychloroquine and HCQ).
To make this dashboard, we need to use PowerBI Desktop. First we need to import Cosmos DB data – the tools support direct import of data from Azure.

Then we provide SQL query to get all entities with the corresponding UMLS IDs – the one we have shown above – and one more query to display all unique categories. Then we drag those two tables to the PowerBI canvas to get the dashboard shown above. The tool automatically understands that two tables are linked by one field named category, and supports the functionality to filter second table based on the selection in the first one.
Similarly, we can create a tool to view relations:

From this tool, we can make queries similar to the one we have made above in SQL, to determine dosages of a specific medications. To do it, we need to select DosageOfMedication relation type in the left table, and then filter the right table by the medication we want. It is also possible to create further drill-down tables to display specific papers that mention selected dosages of medication, making this tool a useful research instrument for medical scientist.
Getting Automatic Insights
The most interesting part of the story, however, is to draw some automatic insights from the text, such as the change in medical treatment strategy over time. To do this, we need to write some more code in Python to do proper data analysis. The most convenient way to do that is to use Notebooks embedded into Cosmos DB:

Those notebooks support embedded SQL queries, thus we are able to execute SQL query, and then get the results into Pandas DataFrame, which is Python-native way to explore data:
%%sql --database CORD --container Papers --output meds
SELECT e.text, e.isNegated, p.title, p.publish_time,
ARRAY (SELECT VALUE l.id FROM l
IN e.links
WHERE l.dataSource='UMLS')[0] AS umls_id
FROM papers p
JOIN e IN p.entities
WHERE e.category = 'MedicationName'
Here we end up with meds DataFrame, containing names of medicines, together with corresponding paper titles and publishing date. We can further group by ontology ID to get frequencies of mentions for different medications:
unimeds = meds.groupby('umls_id')
.agg({'text' : lambda x : ','.join(x),
'title' : 'count',
'isNegated' : 'sum'})
unimeds['negativity'] = unimeds['isNegated'] / unimeds['title']
unimeds['name'] = unimeds['text']
.apply(lambda x: x if ',' not in x
else x[:x.find(',')])
unimeds.sort_values('title',ascending=False).drop('text',axis=1)
This gives us the following table:
umls_id |
title |
isNegated |
negativity |
name |
|---|
C0020336 |
4846 |
191 |
0.039414 |
hydroxychloroquine |
C0008269 |
1870 |
38 |
0.020321 |
chloroquine |
C1609165 |
1793 |
94 |
0.052426 |
Tocilizumab |
C4726677 |
1625 |
24 |
0.014769 |
remdesivir |
C0052796 |
1201 |
84 |
0.069942 |
azithromycin |
… |
… |
… |
… |
… |
C0067874 |
1 |
0 |
0.000000 |
1-butanethiol |
From this table, we can select the top-15 most frequently mentioned medications:
top = {
x[0] : x[1]['name'] for i,x in zip(range(15),
unimeds.sort_values('title',ascending=False).iterrows())
}
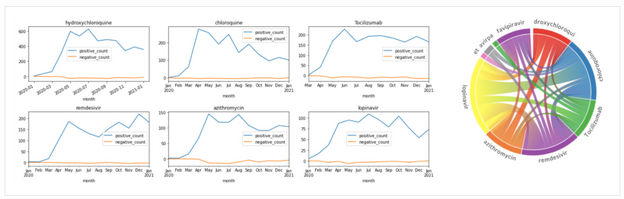
To see how frequency of mentions for medications changed over time, we can average out the number of mentions for each month:
# First, get table with only top medications
imeds = meds[meds['umls_id'].apply(lambda x: x in top.keys())].copy()
imeds['name'] = imeds['umls_id'].apply(lambda x: top[x])
# Create a computable field with month
imeds['month'] = imeds['publish_time'].astype('datetime64[M]')
# Group by month
medhist = imeds.groupby(['month','name'])
.agg({'text' : 'count',
'isNegated' : [positive_count,negative_count] })
This gives us the DataFrame that contains number of positive and negative mentions of medications for each month. From there, we can plot corresponding graphs using matplotlib:
medh = medhist.reset_index()
fig,ax = plt.subplots(5,3)
for i,n in enumerate(top.keys()):
medh[medh['name']==top[n]]
.set_index('month')['isNegated']
.plot(title=top[n],ax=ax[i//3,i%3])
fig.tight_layout()

Visualizing Terms Co-Occurrence
Another interesting insight is to observe which terms occur frequently together. To visualize such dependencies, there are two types of diagrams:
- Sankey diagram allows us to investigate relations between two types of terms, eg. diagnosis and treatment
- Chord diagram helps to visualize co-occurrence of terms of the same type (eg. which medications are mentioned together)
To plot both diagrams, we need to compute co-occurrence matrix, which in the row i and column j contains number of co-occurrences of terms i and j in the same abstract (one can notice that this matrix is symmetric). The way we compute it is to manually select relatively small number of terms for our ontology, grouping some terms together if needed:
treatment_ontology = {
'C0042196': ('vaccination',1),
'C0199176': ('prevention',2),
'C0042210': ('vaccines',1), ... }
diagnosis_ontology = {
'C5203670': ('COVID-19',0),
'C3714514': ('infection',1),
'C0011065': ('death',2),
'C0042769': ('viral infections',1),
'C1175175': ('SARS',3),
'C0009450': ('infectious disease',1), ...}
Then we define a function to compute co-occurrence matrix for two categories specified by those ontology dictionaries:
def get_matrix(cat1, cat2):
d1 = {i:j[1] for i,j in cat1.items()}
d2 = {i:j[1] for i,j in cat2.items()}
s1 = set(cat1.keys())
s2 = set(cat2.keys())
a = np.zeros((len(cat1),len(cat2)))
for i in all_papers:
ent = get_entities(i)
for j in ent & s1:
for k in ent & s2 :
a[d1[j],d2[k]] += 1
return a
Here get_entities function returns the list of UMLS IDs for all entities mentioned in the paper, and all_papers is the generator that returns the complete list of paper abstracts metadata.
To actually plot the Sankey diagram, we can use Plotly graphics library. This process is well described here, so I will not go into further details. Here are the results:


Plotting a chord diagram cannot be easily done with Plotly, but can be done with a different library – Chord. The main idea remains the same – we build co-occurrence matrix using the same function described above, passing the same ontology twice, and then pass this matrix to Chord:
def chord(cat):
matrix = get_matrix(cat,cat)
np.fill_diagonal(matrix,0)
names = cat.keys()
Chord(matrix.tolist(), names, font_size = "11px").to_html()
The results of chord diagrams for treatment types and medications are below:

|

|
Treatment types |
Medications |
Diagram on the right shows which medications are mentioned together (in the same abstract). We can see that well-known combinations, such as hydroxychloroquine + azitromycin, are clearly visible.
Conclusion
In this post, we have described the architecture of a proof-of-concept system for knowledge extraction from large corpora of medical texts. We use Text Analytics for Health to perform the main task of extracting entities and relations from text, and then a number of Azure services together to build a query took for medical scientist and to extract some visual insights. This post is quite conceptual at the moment, and the system can be further improved by providing more detailed drill-down functionality in PowerBI module, as well as doing more data exploration on extracted entity/relation collection. It would also be interesting to switch to processing full-text articles as well, in which case we need to think about slightly different criteria for co-occurrence of terms (eg. in the same paragraph vs. the same paper).
The same approach can be applied in other scientific areas, but we would need to be prepared to train a custom neural network model to perform entity extraction. This task has been briefly outlined above (when we talked about the use of BERT), and I will try to focus on it in one of my next posts. Meanwhile, feel free to reach out to me if you are doing similar research, or have any specific questions on the code and/or methodology.
by Contributed | Apr 13, 2021 | Technology
This article is contributed. See the original author and article here.
Customer expectations continue to increase, looking for immediate response and rapid issue resolution, across multiple channels 24/7. Nowhere is this more apparent than the contact center, with this landscape is driving the need for efficiencies, such as reducing call handling times and increasing call deflection rates – all whilst aiming to deliver a personalized and tailored customer experience.
To help respond to this need, we announced the public preview of the telephony channel for Azure Bot Service in February 2021, expanding the already significant number of touch points offered by the service, to include this increasingly critical method of communication.
Built on state-of-the-art speech services
The new telephony channel, combined with our Bot Framework developer platform, makes it easy to rapidly build always-available virtual assistants, or IVR assistants, that provide natural language intent-based call handling and the ability to handle advanced conversation flows, such as context switching and responding to follow up questions and still meeting the goal of reducing operational costs for enterprises.
This new capability combines several of our Azure and AI services, including our state-of-the-art Cognitive Speech Service, enabling fluid, natural-sounding speech that matches the patterns and intonation of human voices through Azure Text-to-Speech neural voices, with Azure Communications Services powering various calling capabilities. The channel also provides support for full duplex conversations and streaming audio over PSTN, support for DTMF, barge-in (allowing a caller to interrupt the virtual assistant) and more. Follow our roadmap and try out one of our samples on the Telephony channel GitHub repository.
Improving our Conversational AI SDK and tools for speech experiences
To compliment the introduction of the telephony channel and ensure our customers can create industry leading experiences, we have added new features to Bot Framework Composer, an open-source conversational authoring tool, featuring a visual canvas, built on top of the Bot Framework SDK, allowing you to extend and customize the conversation with code and pre-built components. Updates to Composer to support speech experiences include,
- The ability to add tailored speech responses in seconds, either for a voice only or multi-modal (text and speech) agent.
- Addition of global application settings for your bot, allowing you to set a consistent voice font to be used on speech enabled channels, including taking care of setting the required base SSML tags.
- Authoring UI helpers that allow you to add additional common SSML (Speech Synthesis Markup Language) tags to control the intonation, speed and even the style of the voice used, including new styles available for our neural voice fonts, such as a dedicated Customer Service style.
Comprehensive Contact Center solution through Dynamics 365
Microsoft announced the expansion of Microsoft Dynamics 365 Customer Service omnichannel capabilities to include a new voice channel, that is built on this telephony channel infrastructure. With native voice, businesses receive seamless, end-to-end experiences within a single solution, ensuring consistent, personalized, and connected support across all channels of engagement. This new voice channel for Customer Service enables an all-in-one customer service solution without fragmentation or manual data integration required, and enables a faster time to value. Learn more here.
Get started building for telephony!

by Contributed | Apr 13, 2021 | Dynamics 365, Microsoft 365, Technology
This article is contributed. See the original author and article here.
Navigating the past year has been a challenge as organizations have had to predict the unpredictablehow their business will adapt, how to retain and even grow customer relationships, and how to think long-term when circumstances can change daily. As we continue through 2021, the path is still uncharted, but what’s clear is the importance of knowing your customer. Microsoft Dynamics 365 Customer Insights, a powerful, real-time customer data platform (CDP) can help you bring together transactional, behavioral, and demographic data to create a 360-degree view of your customers. With the 2021 release wave 1 updates for engagement insights (preview) and audience insights in Dynamics 365 Customer Insights, we are elevating our Microsoft customer data platform with even more capabilities to help businesses: Get a holistic view of customers Predict customer needs Drive meaningful actions Rely on a trusted platform to optimize security Get a holistic view of customers To know how your customers are behaving, you need to see the data, whether that be how customers navigate your webpages, what they purchase and when, or why they are contacting customer service. But if this data is scattered across disparate IT systems, it’s hard to see a clear picture. With the addition of engagement insights, you can connect digital analytics with customer profile data to see your customers across touchpoints like web, mobile, transaction, and customer service. By pulling fragmented data together, you can rely on a single source of truth to inform your strategy. We believe you should be empowered to integrate your dataregardless of where it sits. Whether it is in the Microsoft ecosystem or any other system, you can ingest data into Dynamics 365 Customer Insights with prebuilt connectors. In this release, we are providing even more prebuilt connectors such as Experian for you to easily use. In this 2021 release wave 1, we are also introducing the seamless experience between Dynamics 365 Customer Insights and customer journey orchestration capabilities in Microsoft Dynamics 365 Marketing. With this new feature, you can build segments in Dynamics 365 Customer Insights to orchestrate real-time customer journeys in Dynamics 365 Marketing. Predict customer needs Data, even unified data, can mean little for your business without insights. But waiting for data insights can often take weeks or months, which can slow down the speed of your business. We offer out-of-the-box AI models, which are ready to apply as-is, and what would normally take weeks or months takes mere hours with Dynamics 365 Customer Insights. We know that your time is valuable and AI-driven insights can help you get value fast. We’ve added AI-powered suggestions to help segment your customers for more personalized messaging. In this 2021 release wave 1, we’ve also added predicted customer lifetime value as well as transaction and subscription churn to make it easier to identify high-value and at-risk customers. With the addition of the next best action and recommended product features, you can pinpoint which product to recommend a customer next and why. Drive meaningful actions Now that you know what your customers are doing and how you want to foster these relationships, it’s time to take action. Share your data insights with any application, whether through Microsoft or third-party platforms. Our vendor-neutral approach enables you to activate insights through apps like AutopilotHQ, Bing Ads, dotdigital, Facebook, Google Ads, HubSpot, LiveRamp, Marketo, Mailchimp, SendGrid, and more. Rely on a trusted platform to optimize your security Data privacy has become all the more important in recent years and we help you keep your data safe by letting you maintain full control of it. By replacing internal data storage with your own data lake, you can manage your data without relying on third-party data integration tools and APIs. In this 2021 release wave 1, we’ve added incremental data ingestion so that Dynamics 365 Customer Insights will only look for new and updated records since its last run, saving your business valuable time. And because Dynamics 365 Customer Insights is built on the trusted cloud platform Microsoft Azure, you can power your custom machine learning scenarios with the latest version of Azure Machine Learning web services. UNICEF Netherlands turn donors into lifetime supporters Private donors and volunteers are crucial to supporting UNICEF’s mission to help every child thrive, all over the world. With Dynamics 365 Customer Insights and customer journey orchestration in Dynamics 365 Marketing, UNICEF Netherlands can better engage donors and build lifetime loyalty by delivering real-time, personalized messages through the right platforms at the right time. “Dynamics 365 Customer Insights really helps us to segment the right audiences, to focus on them, to engage them in a very relevant way, and to retain them.”Astrid van Vonderen, Director of Fundraising and Private Individuals Learn more about Dynamics 365 Customer Insights and customer journey orchestration in our blog post, “Drive personalized interactions with real-time customer journey orchestration.”
The post Get real-time digital analytics with Dynamics 365 Customer Insights appeared first on Microsoft Dynamics 365 Blog.
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.


Recent Comments