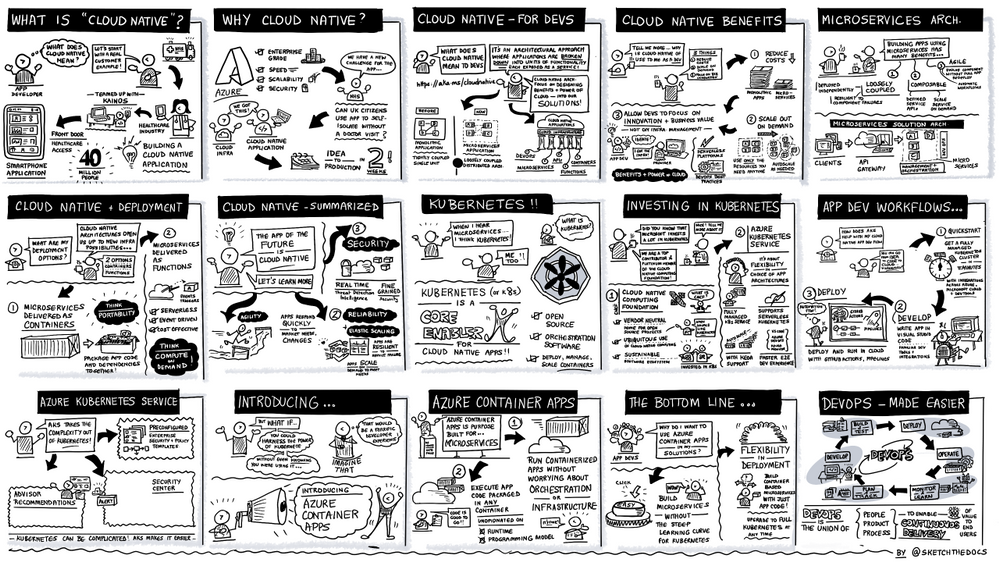
by Contributed | Nov 30, 2021 | Technology
This article is contributed. See the original author and article here.
Microsoft Ignite 2021 took place online November 2-5. This fall edition was full of dev news, and if you don’t want to miss anything related to App development and innovation, keep reading!
Session Highlights
What does it take to build the next innovative app?
During the Digital and App Innovation Into Focus session, Ashmi Chokshi and Developer and IT guests Amanda Silver, Donovan Brown and Rick Claus discussed processes and strategies to help deliver innovative capabilities faster.
Developers are driving innovation everywhere, and Ashmi started the conversation strong sharing how she sees the opportunity to drive impact. Then, Donovan presented his definition of cloud native, the benefits of a microservices architecture, and engaged in a discussion with Rick around DevOps and Chaos Engineering. This session also discussed how to transform and modernize your existing .NET and Java applications. Amanda Silver concluded with a demo showing how tools like GitHub Actions, Codespaces and Playwright can help with development, testing and CI/CD, no matter what language and framework you are using.
The sketch below illustrates the cloud native and DevOps segment showcasing the new public preview of Azure Container apps, a fully managed serverless container service built for microservices that scales dynamically based on HTTP traffic, events or long-running background jobs.
To dive deeper into the latest innovation on containers and serverless to create microservices application on Azure, don’t miss Jeff Hollan and Phil Gibson’s session where they demoed Azure Container apps and the Open Service Mesh (OSM) add-on for Azure Kubernetes Service, a lightweight and extensible cloud native open-source service mesh built on the CNCF Envoy project. Brendan Burns, Microsoft CVP of Azure Compute, also shared his views on how Microsoft empowers developers to innovate with cloud-native and open source on Azure in this blog.
Another highlight of Ignite was the Build secure app with collaborative DevSecOps practice session, followed by the Ask-the-expert, where Jessica Deen and Lavanya Kasarabada introduced a complete development solution that enables development teams to securely deliver cloud-native apps at DevOps speed with deep integrations between GitHub and Azure.
Announcements recap
In addition to Azure Container apps and Open Service Mesh add-on for AKS, we also announced new functionalities for Azure Communication Services, API management, Logic Apps, Azure Web PubSub, Java on Azure container platforms and DevOps.
- Azure Communication services announced two upcoming improvements designed to enhance customer experiences across multiple platforms: Azure Communication services interoperability into Microsoft Teams for anonymous meeting join, generally available in early December; and short code functionality for SMS in preview later this month.
- Regarding Azure Logic Apps, updated preview capability and general availability to Logic Apps standard features have been made available for SQL as storage provider, Managed identity, Automation tasks, Designer, Consumption to standard export and connectors.
The complete line up of Azure Application development sessions and blogs is listed below:
On-demand sessions:
Innovate anywhere from multicloud to edge with Scott Guthrie
|
Microsoft Into Focus: Digital & App Innovation with Amanda Silver, Donovan Brown, Ashmi Chokshi, Rick Claus, Ben Walters and Adam Yager
|
Innovate with cloud-native apps and open source on Azure with Phil Gibson and Jeff Hollan
|
Build secure apps with collaborative DevSecOps practices with Jessica Deen and Lavanya Kasarabada
And Ask-the Experts session
|
Deep Dive on new container hosting options on Azure App Service and App Service Environment v3 with Stefan Schackow
|
Modernize enterprise Java applications and messaging with Java EE/Jakarta EE on Azure and Azure Service Bus with Edward Burns
|
Updates on Migrating to Azure App Service with Rahul Gupta, Kristina Halfdane, Gaurav Seth
|
Scaling Unreal Engine in Azure with Pixel Streaming and Integrating Azure Digital Twins with Steve Busby, Erik Jansen, Maurizio Sciglio, Aaron Sternberg, David Weir-McCall
|
Enterprise Integration: Success Stories & Best Practices with Derek Li
|
Build a basic cloud-native service using PostgreSQL and Node.js with Scott Coulton, Glaucia Lemos
|
Programming Essentials for Beginners with Cecil Phillip
|
Low Code, No Code, No Problem – A Beginner’s Guide to Power Platform. with Chloe Condon
|
Blog-posts:
Additional learn resources:
- Each session has a curated Microsoft learn collection with learn modules and paths, e-books recommendations, related blog posts etc. Here is the collection for Digital and App Innovation IntoFocus session: https://aka.ms/intofocus-digital-apps
- We also just released the new 2021 edition of the Developer’s Guide to Azure, free for you to download!
We can’t wait to see what you create!

by Priyesh Wagh | Nov 30, 2021 | Dynamics 365, Microsoft, Technology
In this post, I will highlight on how you can enable SharePoint Online Document Integration with Dynamics 365 CRM and how these records are structured in SharePoint as well as Dynamics CRM. Hope this post covers it for you to get started with Dynamics 365 SharePoint Online Integration! ? Pre-requisites Here are the pre-requisites you … Continue reading Enable SharePoint Online integration Dynamics 365 | Power Platform Admin Center
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.
by Contributed | Nov 29, 2021 | Technology
This article is contributed. See the original author and article here.
We hope you enjoyed Ignite 2021! We loved hearing from you and learning how you’re using Azure Active Directory to implement Zero Trust to protect users and applications from threats. Many of you have asked for more empowering and easier to use tools for protection and investigation in your identity environment. So today we’re delighted to offer a closer look at the new Azure AD Conditional Access and Identity Protection capabilities that help you better protect your identities while making your job easier.
New capabilities in Azure AD Conditional Access and Identity Protection
This Ignite, we announced a powerful set of capabilities that make Conditional Access easier to use and empower you with insights that help accelerate your Zero Trust deployments and give you more comprehensive protection for key scenarios. The Conditional Access overview dashboard (in public preview) empowers you to quickly find gaps in your policy coverage, while templates make it much easier to deploy recommended policies. Filters for devices and filters for apps (generally available) unlock new scenarios like restricting admin access to privileged workstations, giving you more comprehensive scenario coverage in key scenarios. Finally, we have made it easier to export risk data (including the new token signals!) and built a really cool new workbook to give you insight on risks (and what to do about it)!
Conditional Access overview dashboard
Let’s dive into the Conditional Access overview dashboard first. As organizations deploy an increasing number of policies, one of the biggest challenges admins face is understanding whether their policies are truly protecting their entire organization. The new Conditional Access overview dashboard makes it easier than ever to deploy comprehensive policies by summarizing users, apps, and devices in scope of your policies and highlighting gaps in your policy coverage.
The dashboard is comprised of four main tabs:
- Getting started: If you are new to Conditional Access, learn about policy components and create a new policy.
- Overview: Get a quick summary of your users, devices, and applications protected by Conditional Access. You can also view policy recommendations based on sign-in activity data in your tenant and quickly deploy policies from policy templates.
- Coverage: Ensure the most commonly accessed applications in your tenant are protected by Conditional Access.
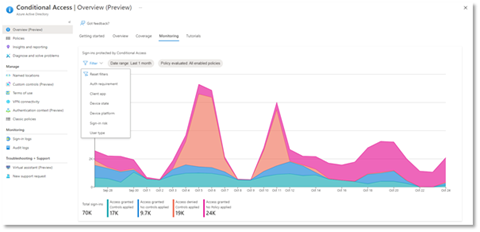
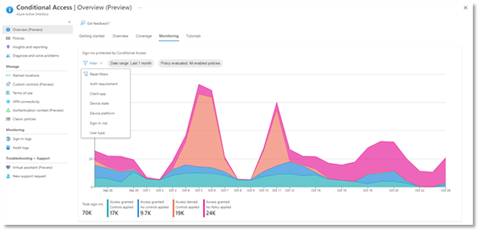
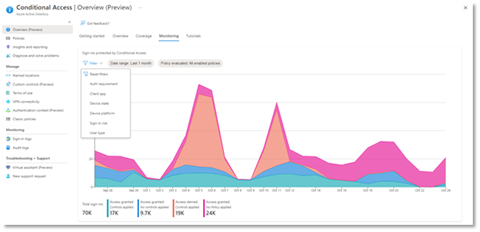
- Monitoring: Visualize the impact of each policy in your tenant and add filters to see trends like guest access, legacy authentication, risky sign-ins and unmanaged devices.
- Tutorials: Learn about commonly deployed Conditional Access policies and best practices.
Conditional Access Templates
Additionally, to provide a simple and sample method for deploying new policies that align with Microsoft recommended best practices and help you respond to evolving threats, we also announced Conditional Access templates. These templates help you provide maximum protection for your users and devices and align with the commonly used policies across many different customer types and locations.
You can quickly create a new policy from any of the 14 built-in templates (we’ll add to these based on your input, new capabilities and in response to new attack types). Deploying your policies from templates is simple. It may be all you need to do, but you can also start from a template and custom tune it to meet your business needs.
 Figure 1: Admin experience for Conditional Access templates
Figure 1: Admin experience for Conditional Access templates
Conditional Access Filters for Devices
With filters for devices, security admins can target Conditional Access policies to a set of devices based on device attributes. This capability unlocks many new scenarios you have asked for, such as requiring privileged access workstations to access key resources. You can also use the device filters condition to secure the use of IoT devices (including Teams meeting rooms). Surface Hubs, Teams phones, Teams meeting rooms, and all sorts of IoT devices. We designed filters for devices to match the existing rule authoring experiences in Azure AD dynamic groups and Microsoft Endpoint Manager.
In addition to the built-in device properties such as device ID, display name, model, Mobile Device Management (MDM) app ID, and more, we’ve provided support for up to 15 additional extension attributes. Using the rule builder, admins can easily build device matching rules using Boolean logic, or they can edit the rule syntax directly to unlock even more sophisticated matching rules. We’re excited to see what scenarios this new condition unlocks for your organization!
 Figure 2: Admin experience for filters for devices
Figure 2: Admin experience for filters for devices
Filters for apps
In addition to filters for devices, you can also use filters for applications in Conditional Access. We’ve heard from customers that with the explosion of apps in their tenants, they need an easier way to apply policies to their apps at scale. Filters for apps will allow improved Conditional Access app targeting based on custom security attributes. Simply tag groups of apps with a custom security attribute and then apply policy directly to apps with the attribute, rather than individually selecting all the apps. When new apps are onboarded, you only need to add the attribute to the app, rather than updating your policy.
Filters for apps use the new Azure AD custom security attributes. These are created and managed by each organization, so you can define attributes that work for you and use them in Conditional Access policy. Custom security attributes also support a rich delegation model, allowing you to select which users have permission to add specific attributes to apps and preventing app owners from making changes to these attributes. This makes it easy to have a set of admins manage app onboarding to Conditional Access policy without requiring them modify the policy and risk accidental changes. Conditional Access filters for apps will be available soon in public preview.

New export options in Diagnostic Settings
With our rich detections and signals in identity protection, we are now making it easier for you to leverage this risk data to understand trends in your environment with two major improvements.
The first improvement is expanded Diagnostic Settings, where we added new ways for you to export your risk data. Now with just one click, you can send your risky users and risk detections data to Log Analytics or your third party SIEM of choice. To address your need to retain this data beyond our built-in retention periods, we have enabled another simple click for you to send months of data to a storage account.
 Figure 3: Admin experience for identity protection diagnostic settings
Figure 3: Admin experience for identity protection diagnostic settings
Risk Analysis Workbook
We also heard your requests for deeper, easily configurable insights into risk trends in your organization. Built upon Log Analytics and the expanded Diagnostic Settings, we released a new Risk Analysis Workbook for Identity Protection. This workbook shows the types of risks that are most prevalent and where you are seeing them in the world. Additionally, you now have visibility into how effectively you are responding to risk detected in your environment and the workbook highlights opportunities for improved policy configuration.
 Figure 4. Admin experience for identity protection risk analysis workbook
Figure 4. Admin experience for identity protection risk analysis workbook
To use the new workbook
- Sign in to the Azure portal.
- Navigate to Azure Active Directory > Monitoring > Workbooks.
- Click on “Identity Protection Risk Analysis”
We hope these new capabilities in Conditional Access make it even easier for you to deploy Zero Trust and unlock a new wave of scenarios for your organization. And the two Identity Protection capabilities help you understand your environment with simplicity yet come with powerful insights. As always, we are actively listening to your feedback. Join the conversation in the Microsoft Tech Community and share your feedback and suggestions with us.
Learn more about Microsoft identity:
by Contributed | Nov 29, 2021 | Technology
This article is contributed. See the original author and article here.
We hope you enjoyed Ignite 2021! We loved hearing from you and learning how you’re using Azure Active Directory to implement Zero Trust to protect users and applications from threats. Many of you have asked for more empowering and easier to use tools for protection and investigation in your identity environment. So today we’re delighted to offer a closer look at the new Azure AD Conditional Access and Identity Protection capabilities that help you better protect your identities while making your job easier.
New capabilities in Azure AD Conditional Access and Identity Protection
This Ignite, we announced a powerful set of capabilities that make Conditional Access easier to use and empower you with insights that help accelerate your Zero Trust deployments and give you more comprehensive protection for key scenarios. The Conditional Access overview dashboard (in public preview) empowers you to quickly find gaps in your policy coverage, while templates make it much easier to deploy recommended policies. Filters for devices and filters for apps (generally available) unlock new scenarios like restricting admin access to privileged workstations, giving you more comprehensive scenario coverage in key scenarios. Finally, we have made it easier to export risk data (including the new token signals!) and built a really cool new workbook to give you insight on risks (and what to do about it)!
Conditional Access overview dashboard
Let’s dive into the Conditional Access overview dashboard first. As organizations deploy an increasing number of policies, one of the biggest challenges admins face is understanding whether their policies are truly protecting their entire organization. The new Conditional Access overview dashboard makes it easier than ever to deploy comprehensive policies by summarizing users, apps, and devices in scope of your policies and highlighting gaps in your policy coverage.
The dashboard is comprised of four main tabs:
- Getting started: If you are new to Conditional Access, learn about policy components and create a new policy.
- Overview: Get a quick summary of your users, devices, and applications protected by Conditional Access. You can also view policy recommendations based on sign-in activity data in your tenant and quickly deploy policies from policy templates.
- Coverage: Ensure the most commonly accessed applications in your tenant are protected by Conditional Access.
- Monitoring: Visualize the impact of each policy in your tenant and add filters to see trends like guest access, legacy authentication, risky sign-ins and unmanaged devices.
- Tutorials: Learn about commonly deployed Conditional Access policies and best practices.
Conditional Access Templates
Additionally, to provide a simple and sample method for deploying new policies that align with Microsoft recommended best practices and help you respond to evolving threats, we also announced Conditional Access templates. These templates help you provide maximum protection for your users and devices and align with the commonly used policies across many different customer types and locations.
You can quickly create a new policy from any of the 14 built-in templates (we’ll add to these based on your input, new capabilities and in response to new attack types). Deploying your policies from templates is simple. It may be all you need to do, but you can also start from a template and custom tune it to meet your business needs.
 Figure 1: Admin experience for Conditional Access templates
Figure 1: Admin experience for Conditional Access templates
Conditional Access Filters for Devices
With filters for devices, security admins can target Conditional Access policies to a set of devices based on device attributes. This capability unlocks many new scenarios you have asked for, such as requiring privileged access workstations to access key resources. You can also use the device filters condition to secure the use of IoT devices (including Teams meeting rooms). Surface Hubs, Teams phones, Teams meeting rooms, and all sorts of IoT devices. We designed filters for devices to match the existing rule authoring experiences in Azure AD dynamic groups and Microsoft Endpoint Manager.
In addition to the built-in device properties such as device ID, display name, model, Mobile Device Management (MDM) app ID, and more, we’ve provided support for up to 15 additional extension attributes. Using the rule builder, admins can easily build device matching rules using Boolean logic, or they can edit the rule syntax directly to unlock even more sophisticated matching rules. We’re excited to see what scenarios this new condition unlocks for your organization!
 Figure 2: Admin experience for filters for devices
Figure 2: Admin experience for filters for devices
Filters for apps
In addition to filters for devices, you can also use filters for applications in Conditional Access. We’ve heard from customers that with the explosion of apps in their tenants, they need an easier way to apply policies to their apps at scale. Filters for apps will allow improved Conditional Access app targeting based on custom security attributes. Simply tag groups of apps with a custom security attribute and then apply policy directly to apps with the attribute, rather than individually selecting all the apps. When new apps are onboarded, you only need to add the attribute to the app, rather than updating your policy.
Filters for apps use the new Azure AD custom security attributes. These are created and managed by each organization, so you can define attributes that work for you and use them in Conditional Access policy. Custom security attributes also support a rich delegation model, allowing you to select which users have permission to add specific attributes to apps and preventing app owners from making changes to these attributes. This makes it easy to have a set of admins manage app onboarding to Conditional Access policy without requiring them modify the policy and risk accidental changes. Conditional Access filters for apps will be available soon in public preview.

New export options in Diagnostic Settings
With our rich detections and signals in identity protection, we are now making it easier for you to leverage this risk data to understand trends in your environment with two major improvements.
The first improvement is expanded Diagnostic Settings, where we added new ways for you to export your risk data. Now with just one click, you can send your risky users and risk detections data to Log Analytics or your third party SIEM of choice. To address your need to retain this data beyond our built-in retention periods, we have enabled another simple click for you to send months of data to a storage account.
Figure 3: Admin experience for identity protection diagnostic settings
Risk Analysis Workbook
We also heard your requests for deeper, easily configurable insights into risk trends in your organization. Built upon Log Analytics and the expanded Diagnostic Settings, we released a new Risk Analysis Workbook for Identity Protection. This workbook shows the types of risks that are most prevalent and where you are seeing them in the world. Additionally, you now have visibility into how effectively you are responding to risk detected in your environment and the workbook highlights opportunities for improved policy configuration.
 Figure 4. Admin experience for identity protection risk analysis workbook
Figure 4. Admin experience for identity protection risk analysis workbook
To use the new workbook
- Sign in to the Azure portal.
- Navigate to Azure Active Directory > Monitoring > Workbooks.
- Click on “Identity Protection Risk Analysis”
We hope these new capabilities in Conditional Access make it even easier for you to deploy Zero Trust and unlock a new wave of scenarios for your organization. And the two Identity Protection capabilities help you understand your environment with simplicity yet come with powerful insights. As always, we are actively listening to your feedback. Join the conversation in the Microsoft Tech Community and share your feedback and suggestions with us.
Learn more about Microsoft identity:
by Contributed | Nov 29, 2021 | Technology
This article is contributed. See the original author and article here.
We hope you enjoyed Ignite 2021! We loved hearing from you and learning how you’re using Azure Active Directory to implement Zero Trust to protect users and applications from threats. Many of you have asked for more empowering and easier to use tools for protection and investigation in your identity environment. So today we’re delighted to offer a closer look at the new Azure AD Conditional Access and Identity Protection capabilities that help you better protect your identities while making your job easier.
New capabilities in Azure AD Conditional Access and Identity Protection
This Ignite, we announced a powerful set of capabilities that make Conditional Access easier to use and empower you with insights that help accelerate your Zero Trust deployments and give you more comprehensive protection for key scenarios. The Conditional Access overview dashboard (in public preview) empowers you to quickly find gaps in your policy coverage, while templates make it much easier to deploy recommended policies. Filters for devices and filters for apps (generally available) unlock new scenarios like restricting admin access to privileged workstations, giving you more comprehensive scenario coverage in key scenarios. Finally, we have made it easier to export risk data (including the new token signals!) and built a really cool new workbook to give you insight on risks (and what to do about it)!
Conditional Access overview dashboard
Let’s dive into the Conditional Access overview dashboard first. As organizations deploy an increasing number of policies, one of the biggest challenges admins face is understanding whether their policies are truly protecting their entire organization. The new Conditional Access overview dashboard makes it easier than ever to deploy comprehensive policies by summarizing users, apps, and devices in scope of your policies and highlighting gaps in your policy coverage.
The dashboard is comprised of four main tabs:
- Getting started: If you are new to Conditional Access, learn about policy components and create a new policy.
- Overview: Get a quick summary of your users, devices, and applications protected by Conditional Access. You can also view policy recommendations based on sign-in activity data in your tenant and quickly deploy policies from policy templates.
- Coverage: Ensure the most commonly accessed applications in your tenant are protected by Conditional Access.
- Monitoring: Visualize the impact of each policy in your tenant and add filters to see trends like guest access, legacy authentication, risky sign-ins and unmanaged devices.
- Tutorials: Learn about commonly deployed Conditional Access policies and best practices.
Conditional Access Templates
Additionally, to provide a simple and sample method for deploying new policies that align with Microsoft recommended best practices and help you respond to evolving threats, we also announced Conditional Access templates. These templates help you provide maximum protection for your users and devices and align with the commonly used policies across many different customer types and locations.
You can quickly create a new policy from any of the 14 built-in templates (we’ll add to these based on your input, new capabilities and in response to new attack types). Deploying your policies from templates is simple. It may be all you need to do, but you can also start from a template and custom tune it to meet your business needs.
 Figure 1: Admin experience for Conditional Access templates
Figure 1: Admin experience for Conditional Access templates
Conditional Access Filters for Devices
With filters for devices, security admins can target Conditional Access policies to a set of devices based on device attributes. This capability unlocks many new scenarios you have asked for, such as requiring privileged access workstations to access key resources. You can also use the device filters condition to secure the use of IoT devices (including Teams meeting rooms). Surface Hubs, Teams phones, Teams meeting rooms, and all sorts of IoT devices. We designed filters for devices to match the existing rule authoring experiences in Azure AD dynamic groups and Microsoft Endpoint Manager.
In addition to the built-in device properties such as device ID, display name, model, Mobile Device Management (MDM) app ID, and more, we’ve provided support for up to 15 additional extension attributes. Using the rule builder, admins can easily build device matching rules using Boolean logic, or they can edit the rule syntax directly to unlock even more sophisticated matching rules. We’re excited to see what scenarios this new condition unlocks for your organization!
Figure 2: Admin experience for filters for devices
Filters for apps
In addition to filters for devices, you can also use filters for applications in Conditional Access. We’ve heard from customers that with the explosion of apps in their tenants, they need an easier way to apply policies to their apps at scale. Filters for apps will allow improved Conditional Access app targeting based on custom security attributes. Simply tag groups of apps with a custom security attribute and then apply policy directly to apps with the attribute, rather than individually selecting all the apps. When new apps are onboarded, you only need to add the attribute to the app, rather than updating your policy.
Filters for apps use the new Azure AD custom security attributes. These are created and managed by each organization, so you can define attributes that work for you and use them in Conditional Access policy. Custom security attributes also support a rich delegation model, allowing you to select which users have permission to add specific attributes to apps and preventing app owners from making changes to these attributes. This makes it easy to have a set of admins manage app onboarding to Conditional Access policy without requiring them modify the policy and risk accidental changes. Conditional Access filters for apps will be available soon in public preview.

New export options in Diagnostic Settings
With our rich detections and signals in identity protection, we are now making it easier for you to leverage this risk data to understand trends in your environment with two major improvements.
The first improvement is expanded Diagnostic Settings, where we added new ways for you to export your risk data. Now with just one click, you can send your risky users and risk detections data to Log Analytics or your third party SIEM of choice. To address your need to retain this data beyond our built-in retention periods, we have enabled another simple click for you to send months of data to a storage account.
Figure 3: Admin experience for identity protection diagnostic settings
Risk Analysis Workbook
We also heard your requests for deeper, easily configurable insights into risk trends in your organization. Built upon Log Analytics and the expanded Diagnostic Settings, we released a new Risk Analysis Workbook for Identity Protection. This workbook shows the types of risks that are most prevalent and where you are seeing them in the world. Additionally, you now have visibility into how effectively you are responding to risk detected in your environment and the workbook highlights opportunities for improved policy configuration.
 Figure 4. Admin experience for identity protection risk analysis workbook
Figure 4. Admin experience for identity protection risk analysis workbook
To use the new workbook
- Sign in to the Azure portal.
- Navigate to Azure Active Directory > Monitoring > Workbooks.
- Click on “Identity Protection Risk Analysis”
We hope these new capabilities in Conditional Access make it even easier for you to deploy Zero Trust and unlock a new wave of scenarios for your organization. And the two Identity Protection capabilities help you understand your environment with simplicity yet come with powerful insights. As always, we are actively listening to your feedback. Join the conversation in the Microsoft Tech Community and share your feedback and suggestions with us.
Learn more about Microsoft identity:

Recent Comments