This article is contributed. See the original author and article here.
Introduction
When migrating from Oracle to SQL Server, Azure SQL Database or Azure SQL Managed Instance, an application using the Microsoft JDBC Driver for SQL Server is often used to avoid re-writing the application. However, after migration it’s often discovered that performance is not the same as it was when the data was on Oracle. Optimizations are necessary for query tuning due to the distinct behaviors of the two database engines.
An unnoticed yet significant issue arises from implicit conversions due to JDBC driver settings, leading to performance degradation. This blog seeks to highlight this easily overlooked problem, offering solutions to ensure optimal performance with SQL backend while preserving the JDBC application.
How to Detect Implicit Conversion
Obtain execution plans for your most CPU-intensive queries by enabling the query store. Be aware that implicit conversions might be happening in smaller queries with high execution counts, even if they don’t individually consume significant resources. An easy way to identify the type conversion is given in this blog.
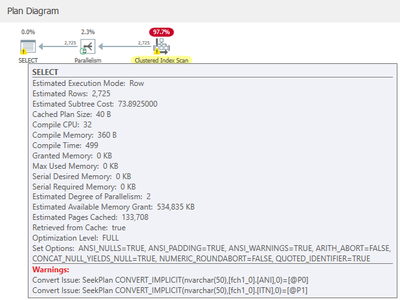
Looking at the execution plan you would see something like this:
While if you look at the statement text, you will see that the JDBC Driver presents the statement like this, which looks innocuous:
(@P0 nvarchar(4000),@P1 nvarchar(4000))select col1, col2 from table1 where col1 = @P0 ….
Nevertheless, implicit conversion will result in queries consuming more CPU resources than anticipated, hindering the scalability of your application. Implicit conversion occurs when the data types of SQL Server columns differ from those presented by the parameter data types of the JDBC driver. Typically, SQL columns are configured with varchar(x) to conserve space compared to Nvarchar(x), while the JDBC driver defaults to transmitting strings as Unicode.
Preventing Implicit Conversion with JDBC Driver
You have two options to choose from based on ease of implementation:
Change the underlying SQL Server column types to align with the parameter datatype. However, this may not be ideal as Nvarchar occupies more space, and altering SQL column types entails significant design changes.
For applications utilizing JDBC, utilize a driver connection property known as “sendStringParametersAsUnicode.” This setting determines whether strings are sent to SQL as Unicode parameters or not. It’s the recommended option. If your SQL column datatypes involved in implicit conversion are varchar, set the value to false.
Once this is implemented, check the query plan again. If the value of the “sendStringParametersAsUnicode” setting is false, the parameters presented by the driver will show up as follows:
(@P0 varchar(4000),@P1 varchar(4000))select col1, col2 from table1 where col1 = @P0 ….
As the underlying SQL column types are also varchar, there is no implicit conversion, leading to improved performance and reduced CPU usage!
You can find a list of all the JDBC driver settings here.
Feedback and suggestions
If you have feedback or suggestions for improving this data migration asset, please send an email to Databases SQL Engineering Team.
Empower your manufacturing journey with Tracked Components: Unveiling the future of precision, compliance, and efficiency in Dynamics 365 Supply Chain Management
Introduction
We’re thrilled to unveil the public preview of our latest feature, Tracked Components, as part of our manufacturing capabilities in Dynamics 365 Supply Chain Management. This feature, released in version 10.0.40 on April 26 2024, streamlines the process of registering batch and serial numbers for components used in manufacturing processes, seamlessly matching them to the batch and serial numbers for the finished products being produced.
Enhanced track and trace capabilities in manufacturing offer a compelling value proposition. They provide real-time visibility into the supply chain, ensuring quality control, regulatory compliance, risk mitigation, enhanced productivity, and improved customer satisfaction. These systems empower manufacturers to optimize operations, reduce errors, and base decisions on data, ultimately leading to increased efficiency and superior products.
Boosting Manufacturing Precision with Tracked Components
At Contoso Inc., Jody, responsible for assembling loudspeakers, must register the serial numbers of the components used and match them to the speaker’s serial number during assembly.
Jody selects the assembly job she is working on in the Production Floor Execution interface and open the Tracked components page. First, Jody scans the serial number of the speaker, and then the serial numbers of the two tracked components used in the assembly. The association between the serial numbers of the components and the serial number of the speaker is now complete. As Jody completes the assembly job, all the serial numbers Jody registered are automatically deducted from inventory and consumed.
During quality inspection, an issue is discovered with on one of the speakers Jody assembled early that day. Peter, the quality supervisor, opens the Item tracing report and scans the serial number of the affected speaker to trace the component serial numbers used for further inspection.
Additional information
Batch and serial numbers can be registered as tracked components in both production and batch orders.
This feature is accessible in both the web client and the production floor execution interface. Within the web client, the interface for registering tracked components is accessible from various points such as routes, jobs, picking list journals, start and report as finished dialogs, and the current operations page.
Batch and serial numbers can be registered using either the keyboard or barcode scanning operations. The feature supports GS1 barcodes, enhancing efficiency by reducing the number of scans required during the registration process.
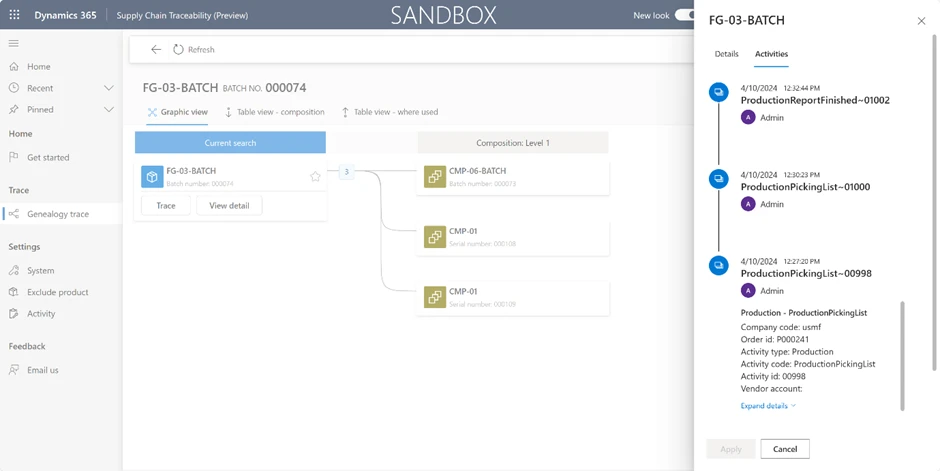
This feature is prepared for integration to the Traceability add-in for Dynamics 365 Supply Chain Management. The Traceability feature (coming in 2024) seamlessly integrates with the tracked components feature, offering visibility into the genealogy tree, also known as the As-Built BOM structure. This integration enables tracking of the assembly process throughout manufacturing. Furthermore, the feature includes forward and backward search capabilities against the genealogy tree. This empowers manufacturers to not only trace product histories but also manage component associations with greater precision.
Image: Preview – Traceability Feature – coming in 2024
Key Business benefits to utilizing Tracked Components
Benefits of Introducing Tracked Components in Manufacturing for Dynamics 365 Supply Chain Management:
Enhanced Efficiency: Tracked Components streamline the process of registering batch and serial numbers for components used in manufacturing processes. This efficiency boost translates into time savings and smoother operations on the production floor.
Improved Quality Control: With real-time visibility into the supply chain, manufacturers can ensure that components meet quality standards before they are used in production. This proactive approach minimizes the risk of defects and rework, ultimately improving the overall quality of the finished products.
Regulatory Compliance: Tracked Components help manufacturers stay compliant with regulations by providing accurate documentation of component usage and traceability throughout the production process. This ensures that products meet regulatory requirements, reducing the risk of fines or penalties.
Risk Mitigation: By enabling quick and accurate tracing of component serial numbers, manufacturers can promptly identify and address any issues that arise during production. This proactive approach minimizes the impact of potential disruptions and reduces the risk of product recalls or warranty claims.
Enhanced Productivity: The seamless integration of Tracked Components into existing workflows allows manufacturers to optimize operations and minimize errors. This increased productivity translates into faster production cycles and higher output levels, ultimately improving overall efficiency.
Improved Customer Satisfaction: With better quality control and more efficient production processes, manufacturers can deliver products that meet or exceed customer expectations. This leads to higher levels of customer satisfaction and strengthens relationships with clients.
Conclusion
In conclusion, Tracked Components for Dynamics 365 Supply Chain Management offer a significant boost to manufacturing efficiency and transparency. This feature enables seamless batch and serial number registration and tracing, ensuring quality control and enhancing productivity. With real-time visibility and barcode scanning support, it streamlines operations and integrates seamlessly into existing workflows. The integration with the Traceability add-in further enhances functionality, promising improved efficiency and compliance. Overall, Tracked Components revolutionize manufacturing processes, optimizing operations and customer satisfaction.
Learn more about Dynamics 365 Supply Chain Management
Dynamics 365 increases agility and resilience through supply chain modernization. Plan with confidence, maximize asset uptime and streamline fulfilment to improve overall profitability learn more here with our Supply Chain Modernization Guided Tour
Learn more about how to register and track batch/serial numbers for finished products and their components (preview) – Documentation
Empower your manufacturing journey with Tracked Components: Unveiling the future of precision, compliance, and efficiency in Dynamics 365 Supply Chain Management
Introduction
We’re thrilled to unveil the public preview of our latest feature, Tracked Components, as part of our manufacturing capabilities in Dynamics 365 Supply Chain Management. This feature, released in version 10.0.40 on April 26 2024, streamlines the process of registering batch and serial numbers for components used in manufacturing processes, seamlessly matching them to the batch and serial numbers for the finished products being produced.
Enhanced track and trace capabilities in manufacturing offer a compelling value proposition. They provide real-time visibility into the supply chain, ensuring quality control, regulatory compliance, risk mitigation, enhanced productivity, and improved customer satisfaction. These systems empower manufacturers to optimize operations, reduce errors, and base decisions on data, ultimately leading to increased efficiency and superior products.
Boosting Manufacturing Precision with Tracked Components
At Contoso Inc., Jody, responsible for assembling loudspeakers, must register the serial numbers of the components used and match them to the speaker’s serial number during assembly.
Jody selects the assembly job she is working on in the Production Floor Execution interface and open the Tracked components page. First, Jody scans the serial number of the speaker, and then the serial numbers of the two tracked components used in the assembly. The association between the serial numbers of the components and the serial number of the speaker is now complete. As Jody completes the assembly job, all the serial numbers Jody registered are automatically deducted from inventory and consumed.
During quality inspection, an issue is discovered with on one of the speakers Jody assembled early that day. Peter, the quality supervisor, opens the Item tracing report and scans the serial number of the affected speaker to trace the component serial numbers used for further inspection.
Additional information
Batch and serial numbers can be registered as tracked components in both production and batch orders.
This feature is accessible in both the web client and the production floor execution interface. Within the web client, the interface for registering tracked components is accessible from various points such as routes, jobs, picking list journals, start and report as finished dialogs, and the current operations page.
Batch and serial numbers can be registered using either the keyboard or barcode scanning operations. The feature supports GS1 barcodes, enhancing efficiency by reducing the number of scans required during the registration process.
This feature is prepared for integration to the Traceability add-in for Dynamics 365 Supply Chain Management. The Traceability feature (coming in 2024) seamlessly integrates with the tracked components feature, offering visibility into the genealogy tree, also known as the As-Built BOM structure. This integration enables tracking of the assembly process throughout manufacturing. Furthermore, the feature includes forward and backward search capabilities against the genealogy tree. This empowers manufacturers to not only trace product histories but also manage component associations with greater precision.
Image: Preview – Traceability Feature – coming in 2024
Key Business benefits to utilizing Tracked Components
Benefits of Introducing Tracked Components in Manufacturing for Dynamics 365 Supply Chain Management:
Enhanced Efficiency: Tracked Components streamline the process of registering batch and serial numbers for components used in manufacturing processes. This efficiency boost translates into time savings and smoother operations on the production floor.
Improved Quality Control: With real-time visibility into the supply chain, manufacturers can ensure that components meet quality standards before they are used in production. This proactive approach minimizes the risk of defects and rework, ultimately improving the overall quality of the finished products.
Regulatory Compliance: Tracked Components help manufacturers stay compliant with regulations by providing accurate documentation of component usage and traceability throughout the production process. This ensures that products meet regulatory requirements, reducing the risk of fines or penalties.
Risk Mitigation: By enabling quick and accurate tracing of component serial numbers, manufacturers can promptly identify and address any issues that arise during production. This proactive approach minimizes the impact of potential disruptions and reduces the risk of product recalls or warranty claims.
Enhanced Productivity: The seamless integration of Tracked Components into existing workflows allows manufacturers to optimize operations and minimize errors. This increased productivity translates into faster production cycles and higher output levels, ultimately improving overall efficiency.
Improved Customer Satisfaction: With better quality control and more efficient production processes, manufacturers can deliver products that meet or exceed customer expectations. This leads to higher levels of customer satisfaction and strengthens relationships with clients.
Conclusion
In conclusion, Tracked Components for Dynamics 365 Supply Chain Management offer a significant boost to manufacturing efficiency and transparency. This feature enables seamless batch and serial number registration and tracing, ensuring quality control and enhancing productivity. With real-time visibility and barcode scanning support, it streamlines operations and integrates seamlessly into existing workflows. The integration with the Traceability add-in further enhances functionality, promising improved efficiency and compliance. Overall, Tracked Components revolutionize manufacturing processes, optimizing operations and customer satisfaction.
Learn more about Dynamics 365 Supply Chain Management
Dynamics 365 increases agility and resilience through supply chain modernization. Plan with confidence, maximize asset uptime and streamline fulfilment to improve overall profitability learn more here with our Supply Chain Modernization Guided Tour
Learn more about how to register and track batch/serial numbers for finished products and their components (preview) – Documentation
This article is contributed. See the original author and article here.
The release of Dynamics 365 Customer Service wave 1 2024 in April introduces several compelling features available for early access. This blog post discusses how to enable the agent call quality survey so agents can provide feedback on improvements.
This functionality enables contact center managers (or their IT counterparts) to swiftly identify and respond to any issues impacting the agent experience that might go unnoticed by conventional service metrics. By promptly addressing potential pain points, you can enhance call quality, strengthen customer satisfaction, and improve overall business performance. This eliminates the necessity of implementing agent satisfaction CSAT through custom development.
Get early access features
To try the call quality survey feature, you must opt in to get early access updates in your environment.
Enable the call quality survey
Once you opt in to early access, you can locate these settings in the Customer Service admin center. Go to Search admin settings and enter the keyword “Survey”. Look for the Workspaces section on the sitemap to access these settings. Alternatively, you can access these settings directly within the Agent Experience under the Workspaces section on the sitemap.
Select Agent call quality survey (preview) and you’ll gain access to the settings provided for this feature, such as the option to opt-in or opt-out, the frequency of survey display expressed as the number of calls before it appears, and the duration for which the survey remains active.
The administrator can set up a general opt-in for the agent survey and determine how frequently the survey appears per a certain number of calls. Additionally, if there’s a need to monitor agent experience for a specific duration, such as after significant changes in voice or telephony settings, the administrator can specify the survey duration with start and end dates.
Another option to access the agent survey configuration is also provided through the Voice workstream configuration settings pane.
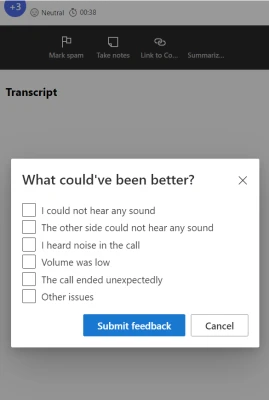
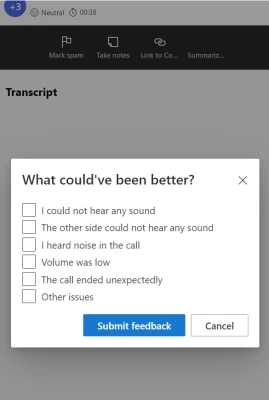
Now, let’s explore the agent experience with this functionality. Following each call, the agent receives a prompt to rate the overall quality of the call. If the agent response is less than 5 stars, the agent sees a new survey page with more detailed depth-in questions.
Following the submission of the survey form, the agent will have the opportunity to view the acknowledgment of their registered feedback and close the survey form.
Query call quality survey results
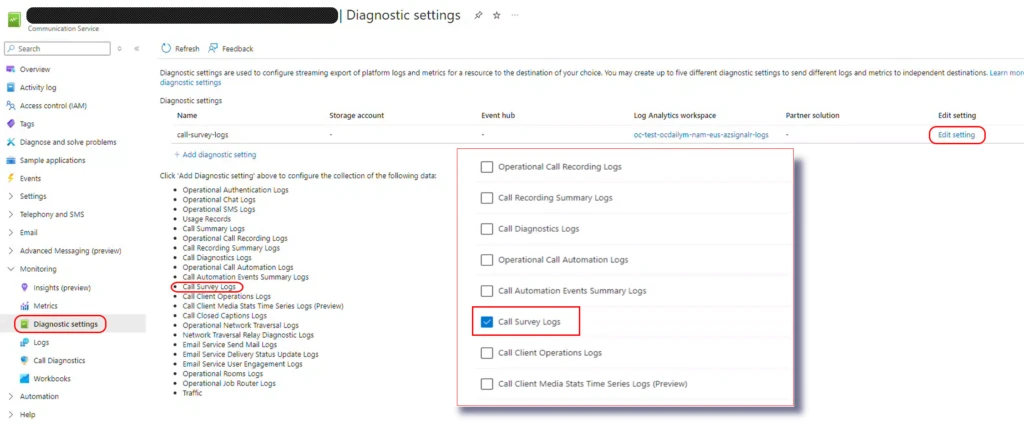
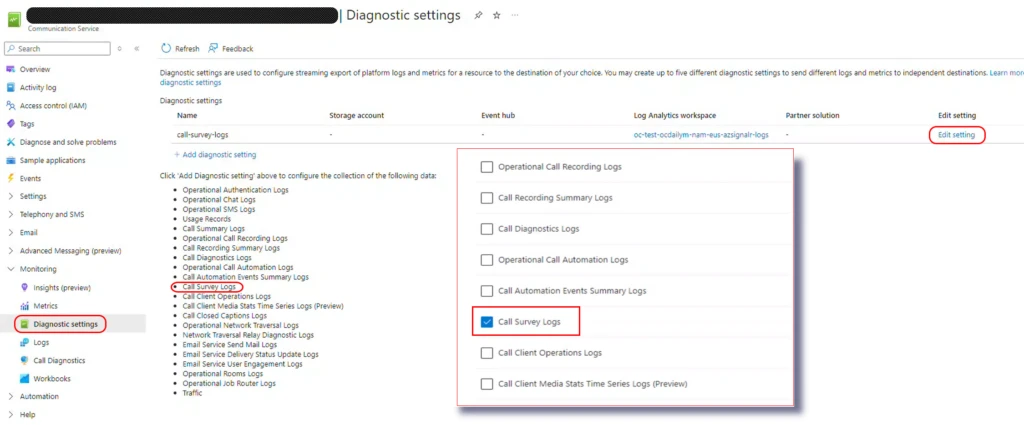
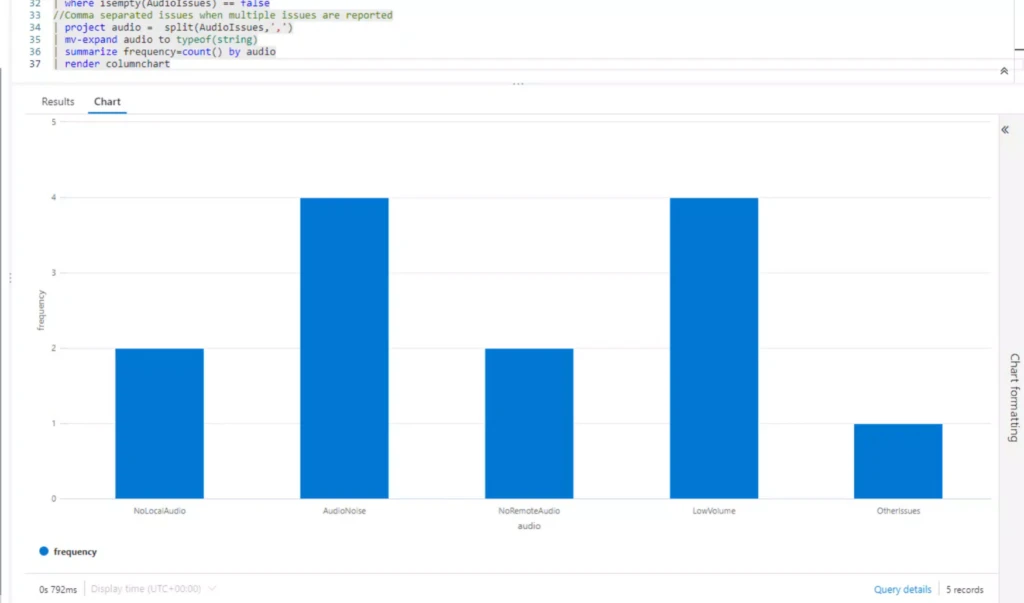
Once the agent’s feedback is saved (stored in Azure logs analytics), you can utilize statistics by querying the aggregated data in Azure. Before querying, make sure to enable the Call Survey Logs option in Diagnostics.
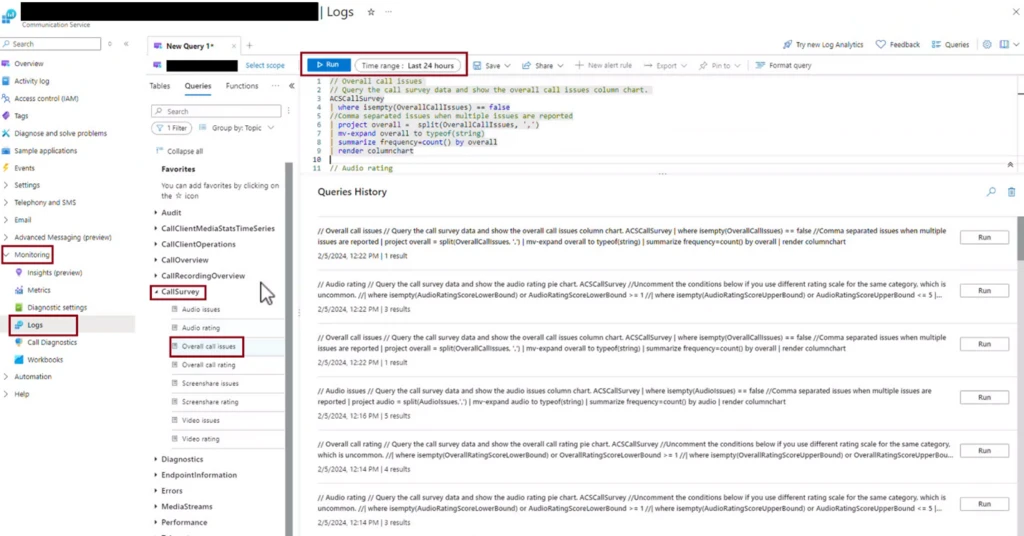
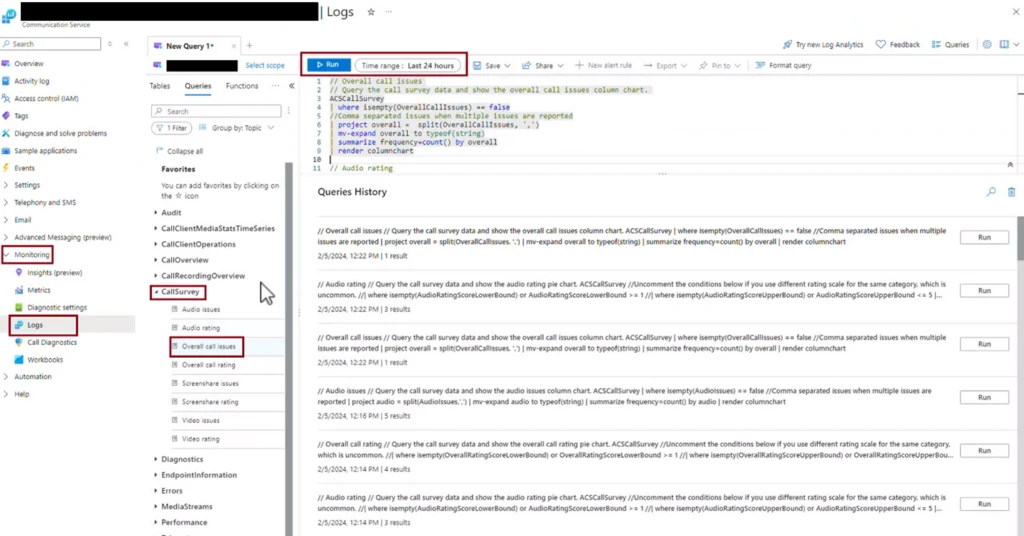
Then Administrator can go to “Logs” -> “Queries” and choose Call survey query to execute.
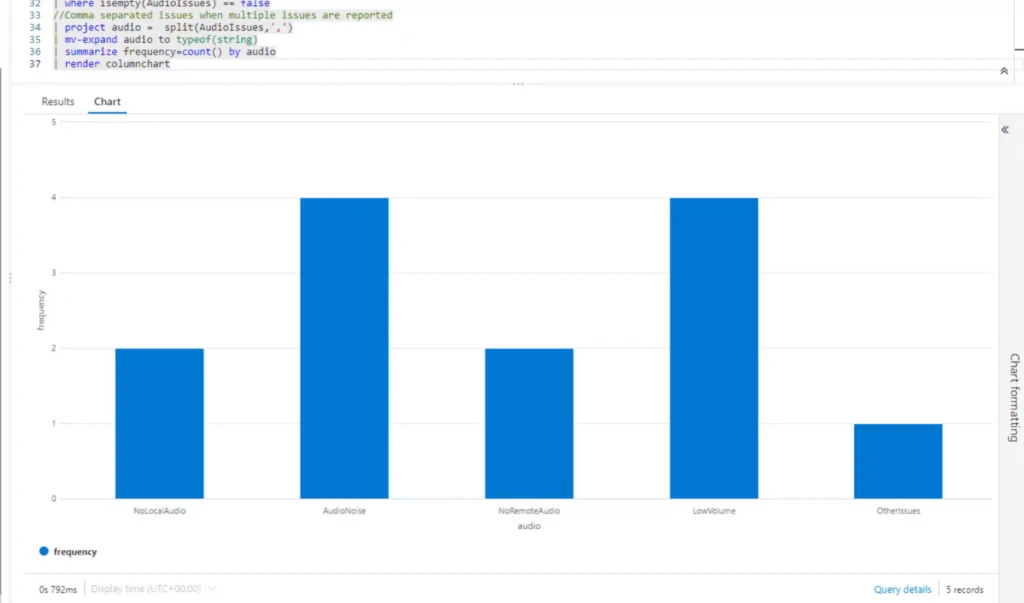
You can delve deeper into the answered questions regarding call quality and respond to any issues more quickly.
In conclusion, the call quality survey provides an easy way for agents to provide feedback. These surveys serve as invaluable tools for gathering immediate feedback from customers regarding their interaction experiences. By analyzing the results of these surveys, agents can identify areas for improvement and ultimately elevate customer satisfaction levels. Moreover, the data collected from these surveys can inform training programs and strategic decision-making within the organization, leading to continuous improvement in service delivery. Ultimately, prioritizing end-of-call quality surveys empowers agents to deliver exceptional customer service, fosters a culture of continuous improvement, and strengthens overall customer relationships.
This article is contributed. See the original author and article here.
The release of Dynamics 365 Customer Service wave 1 2024 in April introduces several compelling features available for early access. This blog post discusses how to enable the agent call quality survey so agents can provide feedback on improvements.
This functionality enables contact center managers (or their IT counterparts) to swiftly identify and respond to any issues impacting the agent experience that might go unnoticed by conventional service metrics. By promptly addressing potential pain points, you can enhance call quality, strengthen customer satisfaction, and improve overall business performance. This eliminates the necessity of implementing agent satisfaction CSAT through custom development.
Get early access features
To try the call quality survey feature, you must opt in to get early access updates in your environment.
Enable the call quality survey
Once you opt in to early access, you can locate these settings in the Customer Service admin center. Go to Search admin settings and enter the keyword “Survey”. Look for the Workspaces section on the sitemap to access these settings. Alternatively, you can access these settings directly within the Agent Experience under the Workspaces section on the sitemap.
Select Agent call quality survey (preview) and you’ll gain access to the settings provided for this feature, such as the option to opt-in or opt-out, the frequency of survey display expressed as the number of calls before it appears, and the duration for which the survey remains active.
The administrator can set up a general opt-in for the agent survey and determine how frequently the survey appears per a certain number of calls. Additionally, if there’s a need to monitor agent experience for a specific duration, such as after significant changes in voice or telephony settings, the administrator can specify the survey duration with start and end dates.
Another option to access the agent survey configuration is also provided through the Voice workstream configuration settings pane.
Now, let’s explore the agent experience with this functionality. Following each call, the agent receives a prompt to rate the overall quality of the call. If the agent response is less than 5 stars, the agent sees a new survey page with more detailed depth-in questions.
Following the submission of the survey form, the agent will have the opportunity to view the acknowledgment of their registered feedback and close the survey form.
Query call quality survey results
Once the agent’s feedback is saved (stored in Azure logs analytics), you can utilize statistics by querying the aggregated data in Azure. Before querying, make sure to enable the Call Survey Logs option in Diagnostics.
Then Administrator can go to “Logs” -> “Queries” and choose Call survey query to execute.
You can delve deeper into the answered questions regarding call quality and respond to any issues more quickly.
In conclusion, the call quality survey provides an easy way for agents to provide feedback. These surveys serve as invaluable tools for gathering immediate feedback from customers regarding their interaction experiences. By analyzing the results of these surveys, agents can identify areas for improvement and ultimately elevate customer satisfaction levels. Moreover, the data collected from these surveys can inform training programs and strategic decision-making within the organization, leading to continuous improvement in service delivery. Ultimately, prioritizing end-of-call quality surveys empowers agents to deliver exceptional customer service, fosters a culture of continuous improvement, and strengthens overall customer relationships.

Recent Comments