
by Contributed | May 4, 2021 | Technology
This article is contributed. See the original author and article here.
What’s Up with Markdown?

Perhaps you’ve noticed a technology called Markdown that’s been showing up in a lot of web sites and apps lately. This article will explain Markdown and help you get started reading and writing it.
Markdown is a simple way to format text using ordinary punctuation marks, and it’s very useful in Microsoft 365. For example, Microsoft Teams supports markdown formatting in chat messages and SharePoint has a Markdown web part. Adaptive Cards support Markdown as well, as do Power Automate approvals. For the bot builders among us, Bot Composer language generation and QnA Maker both support markdown as well. And what’s at the top level of nearly every Github repo? You guessed it, a markdown file called README.md.
Designed to be intuitive
Imagine you’re texting someone and all you have to work with is letters, numbers, and a few punctuation marks. If you want to get their attention, you might use **asterisks**, right? If you’ve ever done that, then you were already using Markdown! Double asterisks make the text bold.
Now imagine you’re replying to an email and want to quote what someone said earlier in the thread. Many people use a little greater-than sign like this:
Parker said,
> Sharing is caring
Guess what, that’s Markdown too! When it’s displayed, it looks like this:
Parker said,
Sharing is caring
Did you ever make a little table with just text characters, like this?
Alpha | Beta | Gamma
——|——|——
1 | 2 | 3
If so, you already know how to make a table in Markdown!
Markdown was designed to be intuitive. Where possible, it uses the formatting clues people type naturally. So you can type something _in italics_ on the screen and it actually appears in italics.
In all cases you’re starting with plain text – the stuff that comes out of your keyboard and is edited with Notepad or Visual Studio Code – into something richer. (Spoiler alert: it’s HTML.)
What about emojis?  Markdown neither helps nor blocks emojis, they’re just characters. If your application can handle emojis, you can certainly include them in your markdown.
Markdown neither helps nor blocks emojis, they’re just characters. If your application can handle emojis, you can certainly include them in your markdown.
Commonly used Markdown
Markdown isn’t a formal standard, and a lot of variations have emerged. It all started at Daring Fireball; most implementations are faithful to the original but many have added their own features. For example, the SharePoint Markdown Web Part uses the “Marked” syntax; if you’re creating a README.md file for use in Github, you’ll want to use Github Flavored Markdown (GFM).
This article will stick to the most commonly used features that are likely to be widely supported. Each section will show an example of some markdown and then the finished rendering (which, again, may vary depending on what application you’re using).
Each of the following sections shows an example of some simple Markdown, followed by the formatted result.
1. Emphasizing Text
Markdown:
You can surround text with *single asterisks* or _single underscores_ to emphasize it a little bit;
this usually formatted using italics.
You can surround text with **double asterisks** or __double underscores__ to emphasize it more strongly;
this is usually formatted using bold text.
Result:
You can surround text with single asterisks or single underscores to emphasize it a little bit; this usually formatted using italics.
You can surround text with double asterisks or double underscores to emphasize it more strongly; this is usually formatted using bold text.
2. Headings
You can make headings using by putting several = (for a level 1 heading) or – signs (for a level 2 heading) in the line below your heading text.
Markdown:
Result:
My Heading
You can also make headings with one or more hash marks in column 1. The number of hash marks controls the level of the heading.
Markdown:
# First level heading
## Second level heading
### Third level heading
etc.
Result:
First level heading
Second level heading
Third level heading
etc.
3. Hyperlinks
Markdown:
To make a hyperlink, surround the text in square brackets
immediately followed by the URL in parenthesis (with no space in
between!) For example:
[Microsoft](https://www.microsoft.com).
Result:
To make a hyperlink, surround the text in square brackets immediately followed by the URL in parenthesis (with no space in between!) For example: Microsoft.
4. Images
Images use almost the same syntax as hyperlinks except they begin with an exclamation point. In this case the “alt” text is in square brackets and the image URL is in parenthesis, with no spaces in between.
Markdown:

Result:
In case you were wondering, you can combine this with the hyperlink like this:
Markdown:
[](http://pnp.github.io)
Result:
5. Paragraphs and line breaks
Markdown:
Markdown will
automatically
remove
single line breaks.
Two line breaks start a new paragraph.
Result:
Markdown will automatically remove single line breaks.
Two line breaks start a new paragraph.
6. Block quotes
Markdown:
Use a greater than sign in column 1 to make block quotes like this:
> Line 1
> Line 2
Result:
Use a greater than sign in column 1 to make block quotes like this:
Line 1 Line 2
7. Bullet lists
Markdown:
Just put a asterisk or dash in front of a line that should be bulleted.
* Here is an item starting with an asterisk
* Here is another item starting with an asterisk
* Indent to make sub-bullets
* Like this
– Here is an item with a dash
– Changing characters makes a new list.
Result:
Just put a asterisk or dash in front of a line that should be bulleted.
- Here is an item starting with an asterisk
- Here is another item starting with an asterisk
- Indent to make sub-bullets
- Here is an item with a dash
- Changing characters makes a new list.
8. Numbered lists
Markdown:
1. Beginning a line with a number makes it a list item.
1. You don’t need to put a specific number; Markdown will renumber for you
8. This is handy if you move items around
1. Don’t forget you can indent to get sub-items
1. Or sub-sub-items
1. Another item
Result:
- Beginning a line with a number makes it a list item.
- You don’t need to put a specific number; Markdown will renumber for you
- This is handy if you move items around
- Don’t forget you can indent to get sub-items
- Or sub-sub-items
- Another item
9. Code samples
Many markdown implementations know how to format code by language. (This article was written in Markdown and made extensive use of this feature using “markdown” as the language!) For example to show some HTML:
Markdown:
~~~html
<button type=“button“>Do not push this button</button>
~~~
Result:
<button type=“button”>Do not push this button</button>
10. Tables
Tables are not universally supported but they’re so useful they had to be part of this article. Here is a simple table. Separate columns with pipe characters, and don’t worry about making things line up; Markdown will handle that part for you.
Markdown:
Column 1 | Column 2 | Column 3
—|—|—
Value 1a | Value 2a | Value 3a
Value 1b | Value 2b | Value 3b
Result:
Column 1 |
Column 2 |
Column 3 |
|---|
Value 1a |
Value 2a |
Value 3a |
Value 1b |
Value 2b |
Value 3b |
HTML and Markdown
Markdown doesn’t create any old formatted text – it specifically creates HTML. In fact, it was designed as a shorthand for HTML that is easier for humans to read and write.
Many Markdown implementations allow you to insert HTML directly into the middle of your Markdown; this may be limited to certain HTML tags depending on the application. So if you know HTML and you’re not sure how to format something in Markdown, try including the HTML directly!
Editing Markdown
If you’d like to play with Markdown right now, you might like to try the Markdown Previewer where you can type and preview Markdown using any web browser.
For more serious editing, Visual Studio Code does a great job, and has a built-in preview facility. Check the VS Code Markdown documentation for details.
There’s a whole ecosystem of tools around Markdown including converters for Microsoft Word and stand-alone editing apps; these are really too numerous to list but are easy to find by searching the web.
Legacy
From vinyl records to 8-bit games and static web sites, there’s a trend these days to rediscover simpler technologies from the past. Markdown definitely falls into this category.
Back before “WYSIWYG” (What You See Is What You Get) word processors were cheap and pervasive, there were “runoff” utilities that were very much like Markdown. They turned text files into nicely formatted printed documents (usually Postscript). Markdown harkens back to these legacy tools, but adds HTML compatibility and an intuitive syntax.
Conclusion
While it may seem unfamiliar at first, Markdown is intended to make it easy for people to read and write HTML. Whether you’re a power user, IT admin, or developer, you’re bound to run into Markdown sooner or later. Here’s hoping this article makes it a little easier to get started!
by Contributed | May 4, 2021 | Technology
This article is contributed. See the original author and article here.
Performance tuning is often harder than it should be. To help make this task a little easier, the Azure Cognitive Search team recently released new benchmarks, documentation, and a solution that you can use to bootstrap your own performance tests. Together, these additions will give you a deeper understanding of performance factors, how you can meet your scalability and latency requirements, and help set you up for success in the long term.
The goal of this blog post is to give you an overview of performance in Azure Cognitive Search and to point you to resources so you can explore the concept more deeply. We’ll walk through some of the key factors that determine performance in Azure Cognitive Search, show you some performance benchmarks and how you can run your own performance tests, and ultimately provide some tips on how you can diagnose and fix performance issues you might be experiencing.
Key Performance Factors in Azure Cognitive Search
First, it’s important to understand the factors that impact performance. We outline these factors in more depth in this article but at a high level, these factors can be broken down into three categories:
It’s also important to know that both queries and indexing operations compete for the same resources on your search service. Search services are heavily read-optimized to enable fast retrieval of documents. The bias towards query workloads makes indexing more computationally expensive. As a result, a high indexing load will limit the query capacity of your service.
Performance benchmarks
While every scenario is different and we always recommend running your own performance tests (see the next section), it’s helpful to have a benchmark for the performance you can expect. We have created two sets of performance benchmarks that represent realistic workloads that can help you understand how Cognitive Search might work in your scenario.
These benchmarks cover two common scenarios we see from our customers:
- E-commerce search – this benchmark is based on a real customer, CDON, the Nordic region’s largest online marketplace
- Document search – this benchmark is based on queries against the Semantic Scholar dataset
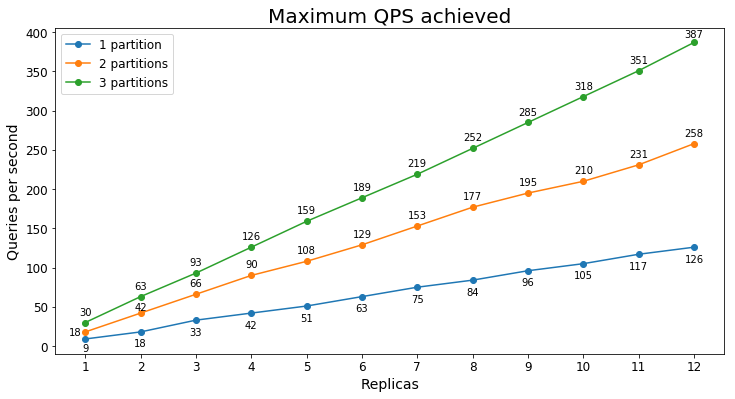
The benchmarks will show you the range of performance you might expect based on your scenario, search service tier, and the number of replicas/partitions you have. For example, in the document search scenario which included 22 GB of documents, the maximum queries per second (QPS) we saw for different configurations of an S1 can be seen in the graph below:
As you can see, the maximum QPS achieved tends to scale linearly with the number of replicas. In this case, there was enough data that adding an additional partition significantly improved the maximum QPS as well.
You can see more details on this and other tests in the performance benchmarks document.
Running your own performance tests
Above all, it’s important to run your own performance tests to validate that your current setup meets your performance requirements. To make it easier to run your own tests, we created a solution containing all the assets needed for you to run scalable load tests. You can find those assets here: Azure-Samples/azure-search-performance-testing.
The solution assumes you have a search service with data already loaded into the search index. We provide a couple of default test strategies that you can use to run the performance test as well as instructions to help you tailor the test to your needs. The test will send a variety of queries to your search service based on a CSV file containing sample queries and you can tune the query volume based on your production requirements.
Apache JMeter is used to run the tests giving you access to industry standard tooling and a rich ecosystem of plugins. The solution also leverages Azure DevOps build pipelines and Terraform to run the tests and deploy the necessary infrastructure on demand. With this, you can scale to as many worker nodes as you need so you won’t be limited by the throughput of the performance testing solution.

After running the tests, you’ll have access to rich telemetry on the results. The test results are integrated with Azure DevOps and you can also download a dashboard from JMeter that allows you to see a range of statistics and graphs on the test results:

Improving performance
If you find your current levels of performance aren’t meeting your needs, there are several different ways to improve performance. The first step to improve performance is understanding why your service isn’t performing as you expect. By turning on diagnostic logging, you can gain access to a rich set of telemetry about your search service—this is the same telemetry that Microsoft Azure engineers use to diagnose performance issues. Once you have diagnostic logs available, there’s step by step documentation on how to analyze your performance.
Finally, you can check out the tips for better performance to see if there are any areas you can improve on.
If you’re still not seeing the performance you expect, feel free to reach out to us at azuresearch_contact@microsoft.com.
by Contributed | May 4, 2021 | Technology
This article is contributed. See the original author and article here.
How to build a fast, scalable data system on Azure SQL Database Hyperscale. Hyperscale’s flexible architecture scales with the pace of your business to process large amounts of data with a small amount of compute in just minutes, and allows you to back up data almost instantaneously.
Zach Fransen, VP of data and AI at Xplor, joins Jeremy Chapman to share how credit card processing firm, Clearent by Xplor, built a fast, scalable merchant transaction reporting system on Azure SQL Database Hyperscale. Take a deep dive on their Hyperscale implementation, from their approach with micro-batching to continuously bring in billions of rows of transactional data, from their on-premises payment fulfillment system at scale, as well as their optimizations for near real-time query performance using clustered column store indexing for data aggregation.
QUICK LINKS:
00:35 — Intro to Clearent
01:33 — Starting point and challenges
03:12 — Clearant’s shift to Hyperscale
04:53 — Near real-time reporting/micro-batching
06:25 — See it in action
08:28 — Processing large amounts of data
09:42 — Namd replicas
10:34 — Query speed ups — clustered column store indexing
11:45 — What’s next for Clearent by Xplor?
12:26 — Wrap up
Link References:
Learn more about Clearent by Xplor and what they’re doing with Hyperscale at https://aka.ms/ClearentMechanics
For more guidance on implementing Azure SQL Database Hyperscale, check out https://aka.ms/MechanicsHyperscale
Unfamiliar with Microsoft Mechanics?
We are Microsoft’s official video series for IT. You can watch and share valuable content and demos of current and upcoming tech from the people who build it at #Microsoft.
Keep getting this insider knowledge, join us on social:
Video Transcript:
– Up next, we meet with credit card processing firm Clearent by Xplor to see how they built a fast, scalable merchant transaction reporting system on Azure SQL Database Hyperscale. From their approach with micro-batching to continuously bring in billions of rows of transactional data from their on-premises payment fulfillment system at scale, as well as their optimizations for near real-time query performance using clustered columnstore indexing for data aggregation and much more. So today, I’m joined by Zach Fransen, who’s the VP of data and AI at Xplor. So welcome to Microsoft Mechanics.
– Thanks. It’s great to be on the show.
– Thanks so much for joining us today. It’s really great to have you on. So if you’re new to Clearent by Xplor, they’re a US-based payment solution provider that enables merchants and retailers to accept credit card payments from anywhere. They process over 500 million transactions per year. And since their inception in 2005, they’ve built several intelligent solutions to reduce credit card processing fees and significantly speed up the fulfillment of credit card payments with next day funding. Now key to this has been connecting their back-end payment fulfillment system with their transaction reporting system. In fact, they’ve recently completed an app and data modernization effort using Azure SQL Database Hyperscale. Their new Compass Online Reporting Suite gives their customers unprecedented and concurrent access to sales transaction data stored on Azure SQL Hyperscale for near real-time views of revenue, sales trends, and much more. So Zach, to put this effort into context, can you help us understand where you were coming from?
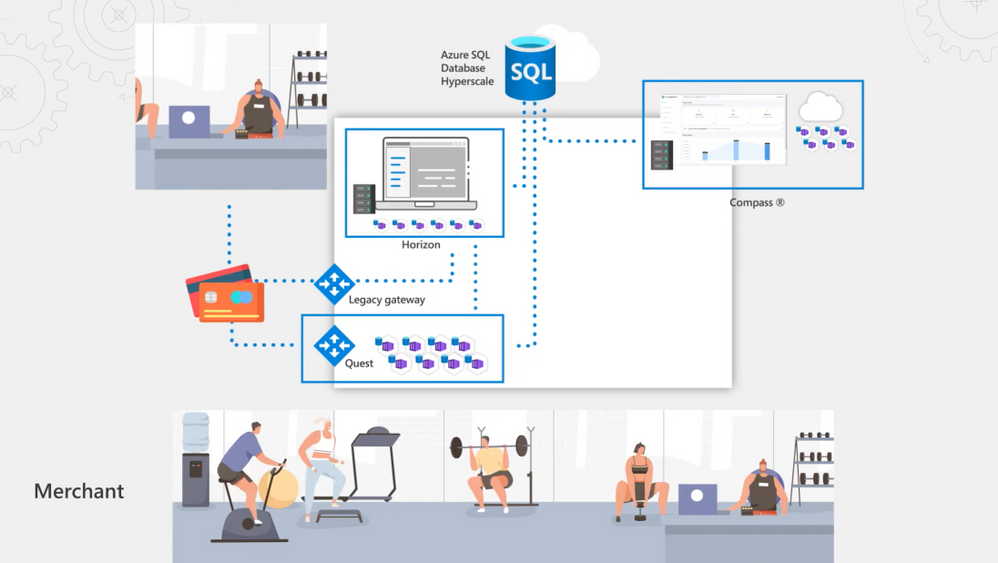
– Sure. So when we started this effort, we were fully on-premises. We had two monolithic legacy apps, Horizon and Compass, running off the same Clearent database. Payments from merchants came in from a legacy third-party mainframe payment gateway and landed in Horizon as flat files. Horizon takes care of qualification, billing, and settling merchant payments. Part of our value add is to pay our merchant customers ahead of the credit agencies. When merchants batch in their sales at the end of the day, the system qualifies the nature of the transaction by checking things like if the transaction was made online or from a card reader via a chip, magnetic strip, or a rewards card. These are all things that determine the cost of the transaction and the fees charged by Visa, Mastercard, Amex and other credit agencies. We also charge a derivative fee based on that, so this is an intricate process to get right. In parallel, our Compass reporting system running on IIS had a SQL Server always on cluster on the same Clearent database back-end that would pull data from Horizon using a stored procedure to transform the data into reporting schemas for merchants to get visibility into their transactions.
– Okay, so how often were you able to pull the data for reporting?
– Well, we did a two-day lookback once a day, so we were having to process two full days of data every day for reporting and we were always a day behind. There was also contention because we were using the same database for processing transactions and reporting. And as our data and customers grew, our run times for processing the data coming into Horizon took longer. Also, concurrent customer queries in Compass would sometimes fail.
– That’s not too surprising. Large database operations like these are prone to performance issues and storage limitations. Plus, you had to find a better way to aggregate the data and make it more available for reporting as well. So what approach then did you take to remediate some of these issues?
– Well, we adopted a hybrid approach which allowed us to keep our data on-premises but migrate the data that we needed for reporting into the Cloud. As our foundation was SQL Server, we wanted to continue to use that skill set and choose an option where we didn’t have to worry about storage limits or syntax changes. We went with the Azure SQL Database Hyperscale service tier that scales to up to 100TB of storage as the reporting back-end for our new Compass Online Reporting Suite. We also modernized the Compass App, taking an extensible microservices-based approach. We built an angular app that calls dozens of services that sit both on-prem and in the Cloud, depending on what it’s trying to do. And we also fragmented our data model to match our service topology. Then, to more consistency bring data in, we built our own payment gateway called Quest, which comprises a consistent set of APIs to pull in merchant data from physical credit card terminals, e-commerce, or integrated payment systems in use by our merchant customers. In fact, as we made it easier to bring data in and broke the Compass app and data monolith apart, Hyperscale’s role in providing a single hub pulling all the data together became even more important. Additionally, we only keep active data on premises, so Hyperscale is critical in keeping a persistent record of all our historical data and to maintaining a lower data footprint on-prem in those transactional systems.
– Okay, so now you’ve got a more scalable and agile app and data layer, but with so many transactions that are happening at any one time, how would you solve for getting the data then into Hyperscale fast enough to support near real-time reporting for your merchants?
– So the game changer for us was adopting low-latency, intraday batch processing, and data streaming. We’ve split our Hyperscale instance into two logical layers, comprising an Operational Data Store and an Enterprise Data Warehouse. And we shifted from once-a-day batch processing to micro-batch processing where we use SQL Server’s Change Data Capture feature to poll our disparate systems for the latest change in data every two minutes. We have data extractors running on our on-premises databases reading our change capture tables, and we have a set of configuration tables sitting in our operational data store that tells it what columns to read. The raw data along with the change history for every table is then loaded into Hyperscale over Express Route into our ODS. And we only extract and load the delta tables in our Enterprise Data Warehouse for reporting and analytics. At the same time, as a credit card transaction is made, Quest immediately places it on a queue, and we use the SQL Server JSON parsing capability to extract out the pieces of information from the message that we are interested in, such as the date, time, and amount of the transaction, and then stream it directly into our star schemas in Hyperscale for reporting so that the data is available to merchants right away.
– This really sounds like a great solution. Can we see it in action?
– Sure. So here is the Compass Online Reporting Suite. On the homepage, you get a quick summary of all of your activity from the last recent deposit through to trends in sales volume. From there, you can drill in to see the detail. I’ll click into one of my deposits. For example, one thing that is useful for merchants is being able to deconstruct a deposit that may just show up as one line item on their bank account statement. In Compass, they can drill in to see the detail behind the deposit whether that’s multiple terminals or multiple batches because Hyperscale is bringing all that data together. Now let me show you what happens as soon as the transaction is made. We’re in the transaction view within a batch. I can see all my recent transactions in this batch. Now I’ll show the process of running a transaction along with where we can view it. I’m in the virtual terminal built on Quest, but this could be a physical terminal or another integrated payment system. I’ll make a credit card transaction. And you’ll see it succeeds in the virtual terminal in under a second. Now I’ll hop over to Compass into our batch view, hit refresh, and you’ll see the payment is pending right away. That’s made possible by Hyperscale instantaneously consuming the data from our messaging queue. Finally, I’ll hop over to my query in SQL Server Management Studio and I’ll query this batch in our Hyperscale database, and you’ll see the results are also instantly available. Next, if we look into our list of settled transactions, you’ll see that once the merchant batches in at the end of the day if they click into a deposit, it shows the amounts and fees along with the net deposit amount and when payment will be posted. I’ll click in to see transactions in this batch. Transaction data is also enriched by the data from our micro-batch processing, as you can see here by optional column views available. I’ll select Product and POS Entry Mode. You’ll see that information show up in our view and these are critical elements that determine the fees for the transaction.
– Okay, so this is an example then of just one transaction, but what if you have maybe 50,000 or more merchants that are running millions of transactions a day?
– Yeah. We process around 1 billion rows of data per month on our Hyperscale implementation right now. As you can see here in the portal, this has amounted to over 28TB. And a big advantage of Hyperscale is that the compute is independent to the size of your data. Let me give you another view from our monitoring tool. Here, the green chart represents Hyperscale. It’s processing a large quantity of billing information as the micro-batch comes in at intervals. It’s actually spiking up to almost 100% utilization, which is around 200,000 IOPS, and incidentally this is only using 8 cores right now which is a relatively small amount of compute. We can elastically scale compute when we need to process a large amount of data or build an index on a giant table with all the history and to scale it up. It only takes a few minutes. Also in Hyperscale, backups are near instantaneous. It’s constantly taking snapshots of your data, which helps significantly with data restore. Through PowerShell, we’ve automated restore when we do full-scale load testing, and that only takes like an hour, even though it’s a 28TB database.
– Okay, so how else then have you configured your Hyperscale implementation?
– Secondary replicas. Not just read-only replicas, but named replicas have been game changing for us. This allowed us to keep our primary instance for our compute intensive ETL and data processing. We can then assign name replicas for specific purposes like analytics and reporting. These tap into a copy of the same data, but have their own dedicated compute. If you recall, when I showed you the slider screen, we had a secondary replica configured for customer traffic, which is part of a scalable pool of replicas for load balancing. If I switch tabs, you can see that we also have a named replica configured to handle analytics traffic. Routing traffic to these replicas is as simple as changing the connection string. This means that critical customer workloads are not interrupted by our compute intensive analytic operations.
– So with such massive amounts of data that are coming in, beyond assigning the right amount of compute, are you doing anything special then to speed up query operations?
– Yes, we do a few things. For example, one of the things we’ve really taken advantage of is clustered columnstore index for data aggregation. A big advantage of Azure SQL Hyperscale is that it’s very flexible. It can handle a variety of different types of traffic and does really rapid aggregation. Here, we have an example of an analytical workload where we are going to take a very large number of records and produce some aggregates. In this particular table, we have a little over 3 billion rows of data. To see some trending, I have a query that will produce a time series by collecting data from different months, which in this case, are in different partitions in a clustered columnstore index. When I run it, you can see it is able to aggregate records across three months in 2021, and it’s almost instantaneous. Another way to look at the data is to look at a cross-section using dimensional slices, like a state. And here, we see the total number of transactions in New York and Washington. So we’re able to look across billions of rows of data and pull these aggregates together in fractions of a second.
– That’s super impressive. And now you’ve transformed then your app and data stack for reporting with Azure SQL Database Hyperscale, but what’s next then for Clearent by Xplor?
– So given our recent merger with the transaction services group to form Xplor, we are taking our Clearent platform international to deliver a service called Xplor Pay with Azure SQL Database Hyperscale as our reporting back-end. And now that we’ve got our data infrastructure to this level of maturity, the next logical step is to leverage Azure Machine Learning. This will help offer additional value-added services to our customers, such as helping them to understand when to run specific promotions based on existing sales.
– Thanks so much, Zach, for joining us today and also giving us the deep dive on your Hyperscale implementation. In fact, to learn more about Clearent by Xplor and what they’re doing with Hyperscale, check out, aka.ms/ClearentMechanics. And for more guidance on implementing Azure SQL Database Hyperscale, check out aka.ms/MechanicsHyperscale. Of course, don’t forget to subscribe to our channel if you haven’t already. Thanks so much for watching. We’ll see you next time.
by Contributed | May 4, 2021 | Technology
This article is contributed. See the original author and article here.
Modernize your existing data at scale, and solve for operational efficiency with Azure SQL Managed Instance. Azure SQL MI is an intelligent, scalable, cloud database service and fully managed SQL server.
Nipun Sharma, lead data architect, joins Jeremy Chapman to share how the Australian subsidiary of large equipment manufacturer, Komatsu, built a scalable and proactive sales and inventory management and customer servicing model on top of Azure SQL Managed Instance to consolidate their legacy data estate on-premises. See what they did to expand their operational visibility and time to insights, including self-service reporting through integration with Power BI.
QUICK LINKS:
00:30 — Komatsu’s background
03:28 — Komatsu’s modernization path
04:12 — Consolidating data to one source
05:50 — Data migration and consolidation of 3 core systems
08:20 — Example reports
09:49 — Self-service reporting
11:17 — Built-in auto tuning
12:45 — What’s next for Komatsu?
13:45 — Wrap up
Unfamiliar with Microsoft Mechanics?
We are Microsoft’s official video series for IT. You can watch and share valuable content and demos of current and upcoming tech from the people who build it at Microsoft.
Keep getting this insider knowledge, join us on social:
Video Transcript:
– Up next, we’re joined by Lead Data Architect Nipun Sharma, to learn how the Australian subsidiary of large equipment manufacturer, Komatsu, built its scalable and proactive sales and inventory management and customer servicing model on top of Azure SQL Managed Instance to consolidate their legacy data estate on premises and drive more self-service reporting with Power BI. So Nipun, welcome to Microsoft Mechanics.
– Thanks for having me here. It’s a pleasure to be on the show.
– And thanks so much for joining us all the way from Australia today. So before we get into this, if you’re new to Komatsu, they’re a leading manufacturer of mining and earth moving equipment for construction around the world. In Australia alone, Komatsu has more than 30,000 machines in daily operation. And as a company, they’re at the forefront of several leading edge solutions in their industry, including smart and autonomous self-driving machinery. Incidentally, the Australian subsidiary spans three different countries in seven regions. So Nipun, with all the expansive area of coverage, what were you trying to solve for?
– So the short answer is operational efficiency. When we started down a modernization path, we were struggling with getting an accurate and timely view of parts, demand, and inventory requirements to meet a customer’s specific needs. Our customers are mainly in mining and construction industries. The uptime of their machines is of critical importance for them and for us. So having the right part at the right place at the right time is vital for operations. From an aftermarket care perspective, to get ahead of inventory requirements we needed more perspective and insight into the drivers behind what customers are requesting. Secondly, on the resource planning side, machine servicing is based on usage. Heavy usage, for example, will accelerate service milestones. At the same time, beyond sourcing the parts needed for servicing, we need to make sure the right skilled technicians are also available. So we wanted to be able to plan those needs more proactively.
– And Komatsu has been around for a long time, but can you tell us what were some of the established systems that were already in play?
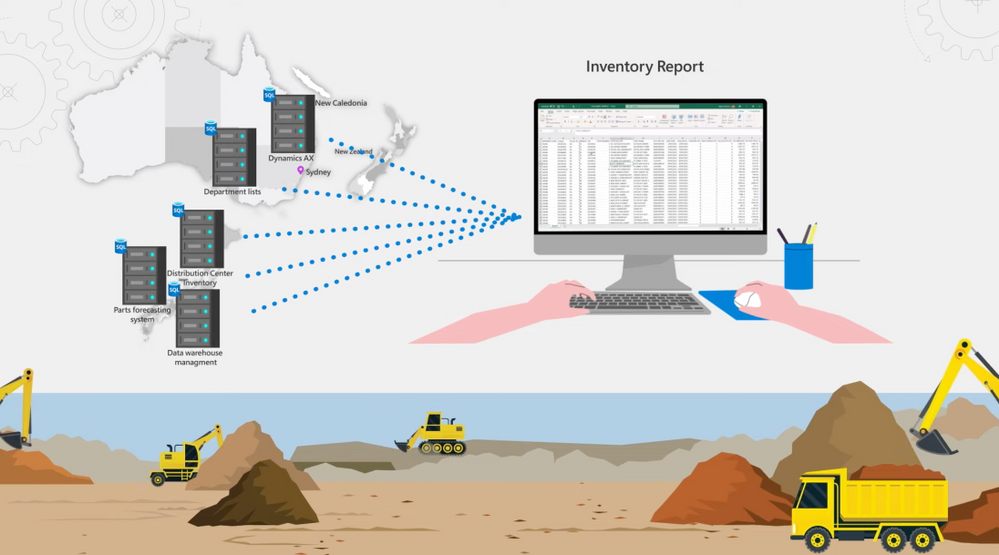
– So yes, this year in fact marks our hundredth anniversary. As you can imagine, we had a blend of legacy and modern applications in our environment used by the business. All systems are fully on-premises. There are around two dozen different source business systems that spans across our Australian subsidiary and our headquarters in Japan. In Japan, we manufacture our machinery. We have systems hosting our satellite telemetry data for our customer machines and other source systems that has component and equipment information, machine contracts, distribution center inventory, and parts ordering systems. Our warehouse management system, including one for stock forecasting and other for planning and logistics is also in Japan. In our Australian subsidiary, we have various ERP systems and customer relationship management systems in use for aftermarket sales and operations. And we have various source systems for field servicing to deploy technicians, local on-board machine systems for diagnostics, branch stock, service meter reading, and more. We maintain a global equipment master system and keep our financial data in SAP. Additionally, when we started there were several dozen Access and SQL server databases in use for file-based source systems. This was managed by our business teams to collate spreadsheets and query volumes of data for weekly snapshot and KPIs.
– Right, that’s a huge amount of data spread across oceans and multiple distributed systems that you were managing.
– Right, we had terabytes of data distributed everywhere, but nothing was connected or available in a consistent manner. People were connecting to data sources through Excel, loading data and files manually for reporting. Pulling a report to get an accurate view of our parts inventory, for example, would require connecting to five different source systems across Japan and our Australian subsidiary, with different schema and different tooling. And the hard part was out-of-date reporting. We were limited to running a batch process once a week. It took 8 to 10 hours. So we ran it on Saturday to avoid impacting our business transactions during the week.
– And these systems were baked into your everyday operations, but what was your approach then that you took for modernizing all of this?
– To move fast, we took a hybrid approach to consolidate our data to a single source of truth across our data estate. We wanted to move to Azure for its data and AI platform capabilities. And we chose Azure SQL Managed Instance for two reasons. The first was compatibility with our SQL implementations. There was almost no code changes, and we were able to leverage the existing skills within the team. We also took advantage of SQL MI VNet support to access the environment from an on-prem network. The second was performance, cost, and dynamic scale. So we could comfortably scale to our needs without any concerns. For example, you can see here, scaling is very easy. We can independently scale, compute and storage. So during our normal business hours, we allocate 16 cores and we can manually scale up for ad hoc needs like data refreshes without interrupting our daily operations. We have also built custom event-based automation in PowerShell. This adds more compute as we load the data for overnight refreshes. It is a simple scripted procedure that we can use on schedule. See, if I do a Get-Command, you’ll see I’m at eight cores. And if I do a set command, you will see it takes a moment to scale up to 24 cores. In our case, we scale up to 24 cores at 9:00 PM each day, so we don’t interfere with business traffic. The data from our source systems is refreshed before the start of the workday, and we scale down in morning at 4:30 AM.
– Okay, so now you had a lot of systems that were in use, but where did you focus then your data migration and consolidation efforts?
– We started by identifying three core systems and we brought this data into Azure SQL MI.
– Okay, so how did these systems then provide an initial foundation for your reporting needs?
– They were instrumental. Our Dynamics AX system holds the key insights for understanding our customer demands for parts. Then our ICT telemetry systems contains satellite data on machine usage, as well as data from onboard systems for specific alerts, events, and warning codes. And it also brings basic time-series data. So based on the hours of usage for a specific machine, we can determine how close it is for specific recommended service milestone. And the actual machine usage shows up in our reports as a Service Meter Reading. Specific events on the machine helps us identify potential failures and proactively support our customers. To add to that, our CMS system, which collects lab data on our oil samples, also provide valuable information about machine health. All this data feeds into our Power BI service via the Power BI gateway, which we set up to provide self-service dashboards, analytics and reporting. And we also use a logic app to refresh our data models once the data is loaded into SQL MI.
– Okay, so how quickly then were you able to expand beyond this kind of core set of services?
– It was radical. Within six to seven months, we started to expand further. We were able to go from almost a working day to pull reports to just 20 minutes with our first iteration. And now by caching the data in Power BI, we can do this in seconds. Since the initial implementation, we have added 17 more business systems without worrying about scaling or performance. We were also able to bring in data from various file sources available only within departments. And we went from 300 gigs to 6 terabytes of data quickly, and from a hundred users to over a thousand consumers of information. In fact, you can see the types of reports the users are generating here. All of these reports were not even possible before. We are streamlining data sets, sources and models so that everyone is working from one source of the truth. We now have around 70 Power BI citizen developers sitting across business teams, building reports around the same data. And we can refresh and pull reports in just a few seconds now.
– Nice, so can we see some of the reports then that you’re now able to build?
– Sure, let me pull up a few for you. Here’s an example. I can see upcoming service milestones by equipment type and location and required parts for the same. If I want to know how many excavators are due for their thousand hour service, I can click here in the excavator bar. Here I can see the regions where the machines are running and the parts required for them. This is something that was not possible before, because the data was either locked into our system or just not available.
– How does this now help with your inventory reporting?
– Oh, we have completely transformed the visibility we had. So let me show you. Here’s an inventory report that our business team were able to create to track parts on hand for customer service requests. The data from this report is sitting across multiple sources and all put together in SQL MI. We can see part stock levels per region represented by DC, Distribution Center values. I can drill into parts available for specific machine type, like excavator, and see quickly the status of this machine. Now the teal color means we’re covered, but doesn’t tell the entire story because some of the parts categories don’t need inventory on hand. If I filter the national demand ranking here to look at the top ranked parts indicated by A, you see we have nothing to worry about, we have a healthy supply.
– And of course, the dashboard is only half the story. So what are you doing then to support this type of self-service reporting?
– Right, the amazing thing for us is having the data in one source. And depending on the question our business is trying to answer, we obviously prep the data and connect the dots at the backend. For example, here’s the backend data model behind these fields that our business users have created linking various tables. Even if you knew where to find the data as a business analyst, most of these tables and the underlying data fields don’t exist. My team implements the business logic to map the data into business semantic layer, to make it more consumable and consistent across the business. Let me give you an example of what goes into this. Here’s SQL Server Management Studio, we build custom views correlating data from different sources. In the first query and tab, we are pulling all the different sources where our inventory currently sits. Main indicates our primary inventory system. Then as I scroll down, you will see we are connecting related data from distribution center and also from branch locations. This paints an accurate picture of inventory across all our repos. Next, in the second tab, this query is all about calculating minimum inventory levels to ensure we have enough stock on hand. You can see here, we are also including incoming deliveries as you see with the items marked on order. This helps ensure that we keep the inventory in line with demand.
– So then, with so much growth then in your data, how were you able to maintain consistency in performance?
– So Azure SQL MI has built-in auto tuning. It will automatically index your main updates and your queries. But there’s also optimizations that you can do to help auto tuning to work better for you. When indexes are created, tables need to be republished. Otherwise the ordering of data on the disk becomes fragmented, impacting your IOPS. To solve this, we update the statistics by prioritizing which tables are most required at the semantic layer for querying. The nice thing with SQL MI is that management is very consistent compared to SQL server running on a physical or a virtual machine. We have a diagnostic script that we can run and list out all big tables and look at the percentage of fragmentation and page counts. If fragmentation is over 80%, we can run another script to fix the fragmentation. To automate this process, we run a stored procedure to defragment the index tables weekly. This is a standard script from Microsoft, and we’ve just added a filter for our biggest schema called DSA for our semantic querying layer. This re-indexes and reformats the table and updates the stats to keep everything under 70% fragmentation. These procedures run every Saturday morning and it takes few hours, but afterwards, all the big tables are tuned for best performance.
– I’m going to say great work from you and the team to really modernize data and the operations at Komatsu. So where do the things then go from here?
– The great thing about being in the cloud is that our implementation grows with us. As you saw, our data has grown 20x and our users 10x, and we have added additional managed instances to support the demand. We also have a great option to grow as we need in Azure. And the next journey is more ad hoc exploration and predictive analytics. We are looking at Azure Synapse Analytics to take advantage of data warehousing as our data footprint grows, especially with our increased investment in IoT and connected machinery at the Edge. Here, you’re seeing the data we have pulled in, and these are the linked services that we are using with Synapse. We have already started experimenting with bringing in our source system data, like SAP HANA, to integrate across data sets and even better insights and data exploration. And we’ll continue to use Azure SQL MI for new apps that we build on Azure.
– Thanks so much Nipun, for joining us today and also sharing Komatsu’s story and implementation for Azure SQL Managed Instance. And also for more hands-on deep dives like this, keep checking back to Microsoft Mechanics. Subscribe to our channel if you haven’t yet, and we’ll see you soon.
by Contributed | May 4, 2021 | Technology
This article is contributed. See the original author and article here.
The .NET Azure IoT Hub SDK team released the latest LTS (Long-Term Support) of the device and service SDKs for .NET. This LTS version, tagged lts_2021-2-18, adds bug fixes, some improvements, and new features over the previous LTS (lts_2020-9-23), such as:
– Handle twin failures using AMQP.
– Make the DeviceClient and ModuleClient extensible.
– Install the device chain certificates using the SDK.
– Make DPS class ClientWebSocketChannel disposable.
– Use CultureInvariant for validating device connection string values.
– Reduce memory footprint of CertificateInstaller.
– Add an API to set a callback for receiving C2D.
– Make set desired property update method thread safe.
– Add support for disabling callbacks for properties and methods.
– Expose DTDL model Id property for pnp devices.
– Make payload in the invoke command API optional.
– Add APIs to get attestation mechanism.
– Improved logging for noting when the no-retry policy is enabled, in the MQTT/AMQP/HTTP transport layers, in the HttpRegistryManager, and in the AmqpServiceClient.
For detailed list of feature and bug fixes please consult the comparing changes with previous LTS: Comparing lts_2020-9-23…lts_2021-3-18 · Azure/azure-iot-sdk-csharp (github.com)
The following NuGet versions have been marked as LTS.
- Microsoft.Azure.Devices: 1.31.0
- Microsoft.Azure.Devices.Client: 1.36.0
- Microsoft.Azure.Devices.Shared: 1.27.0
- Microsoft.Azure.Devices.Provisioning.Client: 1.16.3
- Microsoft.Azure.Devices.Provisioning.Transport.Amqp: 1.13.4
- Microsoft.Azure.Devices.Provisioning.Transport.Http: 1.12.3
- Microsoft.Azure.Devices.Provisioning.Transport.Mqtt: 1.14.0
- Microsoft.Azure.Devices.Provisioning.Security.Tpm: 1.12.3
- Microsoft.Azure.Devices.Provisioning.Service: 1.16.3
More detail on the LTS 2021-03-18 version can be found here.
Enjoy this new LTS version.
Eric for the Azure IoT .NET Managed SDK team

Recent Comments