
by Contributed | Jul 26, 2021 | Technology
This article is contributed. See the original author and article here.
This is the next installment of our blog series highlighting Microsoft Learn Student Ambassadors who achieved the Gold milestone and have recently graduated from university. Each blog in the series features a different student and highlights their accomplishments, their experience with the Student Ambassadors community, and what they’re up to now.
Today we’d like to introduce Khushboo Verma who is from India and graduated in May from the Indira Gandhi Delhi Technical University for Women with a degree in Computer Science Engineering.
Responses have been edited for clarity and length.
When you joined the Student Ambassador community in 2018, did you have specific goals you wanted to reach, such as a particular skill or quality? What were they? Did you achieve them? How has the program impacted you in general?
My aim behind joining was to connect with a community beyond my campus to be able to bring opportunities and resources to my local community. I wanted to learn valuable skills – both technical and interpersonal – so that I can uplift those around me. The Student Ambassador program helped me grow above and beyond my initial goal. It truly empowered me by providing me an opportunity to connect with passionate student developers from all over the world. It helped me understand what an inclusive and diverse community looks like and also helped me discover my true potential.
I vividly remember my first event as a Student Ambassador when I delivered a talk on Azure in a room full of developers, some of them having many years of industry experience. That talk helped me realize my passion for tech communities and for public speaking. It opened a sea of opportunities for me. From that day to the present day, I have grown immensely. I’ve gained confidence and skills; it has been possible because of the support I’ve continuously received from the program. It has helped me build a personal brand for myself, and it also provided inspiration we receive from mentors like Pablo Veramendi, the Microsoft Learn Student Ambassadors Global Program Director, who are so passionate to empower the community and do their best everyday to bring the best out of us. I’ve witnessed the community grow exponentially ever since I’ve joined, and I feel super proud to be a part of a community that is literally transforming lives.
What are the accomplishments that you’re the proudest of and why?
I’ve organized multiple events as a Student Ambassador, and I’ve impacted more than 2000 student developers, but I’m most proud of the “Microsoft Student HackDay” I organized on my campus. The idea behind the hackathon was to introduce the women on my campus to the cloud computing landscape. I’m from an all-women university, and only a handful of my peers were aware about cloud computing and had never tried it hands-on. With the support of Arkodyuti Saha, Developer Relations Program Manager at Microsoft, I organized a 2-day hackathon on campus in which 80 women participated in a beginner workshop on chatbots in Azure. At the end of the hackathon, we were surprised to see that the participants had built amazing projects even though some of them learned about Azure and chatbots for the first time during the workshop. That event made me believe that women can achieve incredible heights if they receive the right guidance.
Another accomplishment I’m really proud of is that as a Gold Ambassador, I was selected to speak at international conferences like Microsoft Build 2020 as part of a panel discussion titled “Learn how to succeed in Hackathons” and Microsoft Ignite 2020 (“Intro to GitHub”). It helped me boost my confidence and provided me the platform to showcase my skills to a much wider audience.
What do you have planned after graduation?
I am really passionate about technology and communities. I did a summer internship at Microsoft India as a software engineering intern. During that internship, I got to learn a lot about software engineering, interacted with senior leaders from Microsoft, and fell in love with Microsoft’s culture. I received a pre-placement offer after my internship, and I’ll be joining Microsoft India full time as a software engineer after graduation. I’m really excited for this upcoming chapter of my life.
If you could redo your time as a Student Ambassador, is there anything you would have done differently?
If I could start all over again, I would network with more people. The Microsoft Student Learn Ambassador program brings together students from varied backgrounds from all over the world and provides us a platform to interact, learn, and lead together. Initially, I was afraid of reaching out to new people because of imposter syndrome but eventually, I realized everyone was really helpful and supportive. Each Student Ambassador has something amazing to teach to the community, and the more I interact with them, the more I learn. So one thing that I would have done differently would be to interact and collaborate with more people.
If you were to describe the community to a student who is interested in joining, what would you say about it to convince him or her to join?
This is a program for every student out there who has a passion to learn, share, and connect with others. If you’re passionate about technology and have a desire to create an exponential impact in the world, then come and join our amazing community. You’ll not only get wonderful opportunities, but you’ll also learn great technical and interpersonal skills, you’ll build long lasting connections, and you’ll become a better leader and a better individual. The community is welcoming, honors diversity and inclusion, and values your ideas.
What advice would you give to new Student Ambassadors?
My advice to all the new Student Ambassadors would be to take initiatives and push yourself to transform your ideas into reality. Network and collaborate with as many people as you can – you’ll get to learn a lot. Help and uplift your community. And lastly, don’t doubt your own capabilities, and don’t be afraid to ask questions, as no question is ever stupid.
What is your motto in life, your guiding principle?
I’d like to share one of my favorite quotes that acts as a guiding principle for me: “As long as you’ve got passion, faith, and are willing to work hard, you can do anything you want in this life.” At the end of the day, I want to be happy with whatever I do, and I want my life to be meaningful, impactful and fulfilling.
What is one random fact about you that few people are aware of?
One random fact about me is that I can’t go without listening to music even for a single day. Music runs in my veins, haha.
Good luck to you in your journey, Khushboo!
by Contributed | Jul 23, 2021 | Technology
This article is contributed. See the original author and article here.
Both tools below – ProcDump and DebugDiag – work similarly: they can attach themselves as debuggers to a process, then, when the machine is on high-CPU, collect one or more memory dump(s) from that specific process.
Note that the tools won’t “know” what process is consuming the CPU unless we dig deeper in the performance counters. If using ProcDump, it easier if we are sure ahead of time what’s the culprit – the process that is “eating” much CPU.
Both tools need administrative rights to be run.
DebugDiag is the preferred tool, since it automates some steps, adds more explicit context, and includes automated memory dump analysis capabilities too.
Using the command-line ProcDump
ProcDump does not require installation. But one needs to be specific about the PID to which it is attaching. That PID needs to be determined prior to starting ProcDump. Debug Diag is able to determine the PID itself, if the Application Pool is specified.
- Download the tool and copy it on a disk folder, for example D:Temp-Dumps
https://docs.microsoft.com/en-us/sysinternals/downloads/procdump
- Open an administrative console, from where to run commands.
Navigate to where the ProcDump tool was placed (D:Temp-Dumps).
- Find the process ID, the PID, of the IIS w3wp.exe worker process executing your application.
From the administrative console, you can use AppCmd IIS tool to list processes for application pools:
C:WindowsSystem32InetSrvappcmd.exe list wp
- In the administrative console, start the following command to collect dumps (but don’t hit enter yet).
D:Temp-Dumps> procdump.exe -accepteula -ma -c 85 -n 3 -s 7 [PID]
You may want to redirect the console output of ProcDump to a file, to persist the recording of the encountered exceptions:
D:Temp-Dumps> procdump.exe -accepteula -ma -c 85 -n 3 -s 7 [PID] > Monitoring-log.txt
Replace [PID] with the actual Process ID integer number identified at the step 2.
Please make sure that there is enough disk space on the drive where dumps are collected. Each process dump will take space in the disk approximately the same size the process uses in memory (column Commit Size in Task Manager). For example, if the w3wp.exe process memory usage is ~1 GB, then the size of a dump file will be around 1 GB.
- Start reproducing the problem: issue requests that would render the process to consume CPU; or leave the command running until the high-CPU occurs.
- Please wait until all the dumps are written and then compress the files before uploading the dumps to the workspace.
Using the UI tool DebugDiag, Debug Diagnostics Collection
DebugDiag requires installation, but it is able to determine itself the whatever process instance – PID – happens to execute for an application pool at some point in time; even when that process may occasionally crash or be recycled, hence restarted with different PID.
#1.
Download Debug Diagnostic and install it on IIS machine:
https://www.microsoft.com/en-us/download/details.aspx?id=49924 v2.2 (if 32-bit system)
https://www.microsoft.com/en-us/download/details.aspx?id=102635 v2.3.1 (only supports 64-bit OS)
#2.
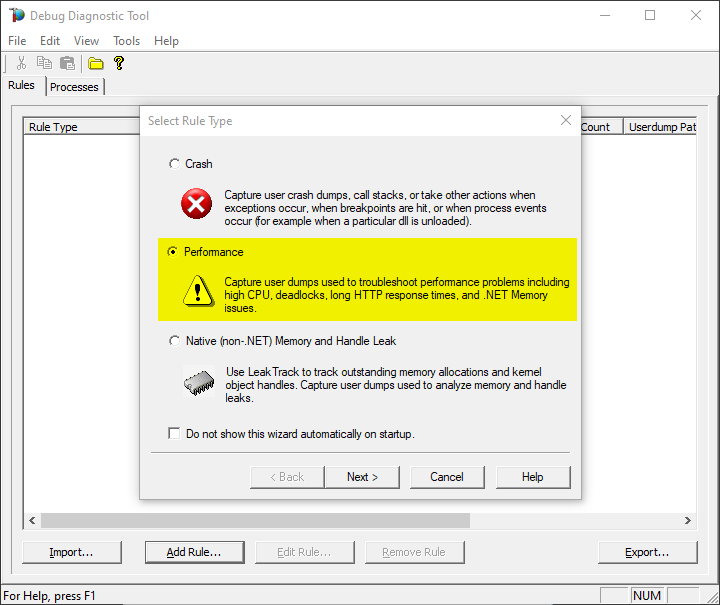
Create a new rule selecting Performance and then clicking on “Next” next button.
You also can create the rule by right-click and selecting “Add rule”, or clicking the “Add rule” button at the bottom.
#3.
Select the second option “Performance Counters” and then “Next”.

#4.
Click on Add Perf Triggers…

#5.
The select %Processor Time from the Processor category and select the _Total instance


Note:
You might need to determine the w3wp.exe#N instance by looking into the Task Manager, sorting by w3wp.exe PID.
Or use one of the following commands in an administrative command-line console, to find out the PIDs:
> C:WindowsSystem32InetSrvappcmd.exe list wp
> TaskList.exe | find “w3wp.exe” /i
> TaskList.exe /FI “IMAGENAME eq w3wp.exe”
#6.
Select the action click on Edit Thresholds

#7.
Select Above, set 80 as this threshold and 5 in for this number of seconds
You might need to adjust the threshold value to what you’re seeing on your system. You should know better how you define “High-CPU” (maybe, in your case, High-CPU means anything above 60%; your experience or expectations matter here).


#8.
Click on Next

#9.
Click on Add Dump Target

#10.
Select Web application pool as Target type and select the application pool

#11.
Click on Next

#12.
Set 10 seconds at Generate a UserDump every…
Set 3 at Stop after Generating…
Select Collect Full UserDumps.

#13.
Type down a descriptive name, i.e. “My App eats a lot of CPU” and select the dump files path.
Keep in mind you’re collecting 4 dumps. Please make sure that there is enough disk space on the drive where dumps are collected. Each process dump will take space in the disk approximately the same size the process uses in memory (column Commit Size in Task Manager). For example, if the w3wp.exe process memory usage is ~2 GB, then the size of each dump file will be around 2 GB.
Do not choose a disk in network/UNC; choose a local disk.

#14.
Select “Activate rule now” option and click on “Finish”

#15.
Watch the rule in DebugDiag; it should tell you how many dumps are collected (present in the selected dumps folder).

#16.
Once the memory dumps are collected and fully written on disk…
Archive each dump file in its own ZIP and prepare to hand over to the support engineer; upload in a secure file transfer space.
Remember my article about how exceptions are handled and how to collect memory dumps to study them. We can double check if a crash occurred or not: read about w3wp.exe crashes.
Aside: Just in case you are wondering what I use to capture screenshots for illustrating my articles, check out this little ShareX application in Windows Store.
by Contributed | Jul 23, 2021 | Technology
This article is contributed. See the original author and article here.
Collect series of memory dumps for memory leak analysis of a process using the steps below.
With such series of memory dumps we can later analyze the consumption trends:
- Objects accumulating in the .NET heaps and not being removed by Garbage Collection;
- Managed modules that are being created and taking up space.
- Too many threads with rather large call stacks, etc.
#1: Have tool installed
Download Debug Diagnostic and install it on IIS machine:
https://www.microsoft.com/en-us/download/details.aspx?id=49924 v2.2 (if 32-bit system)
https://www.microsoft.com/en-us/download/details.aspx?id=102635 v2.3.1 (only supports 64-bit OS)
#2: Start collection rule
Run Debug Diagnostics Collection. Open the tool with admin rights.
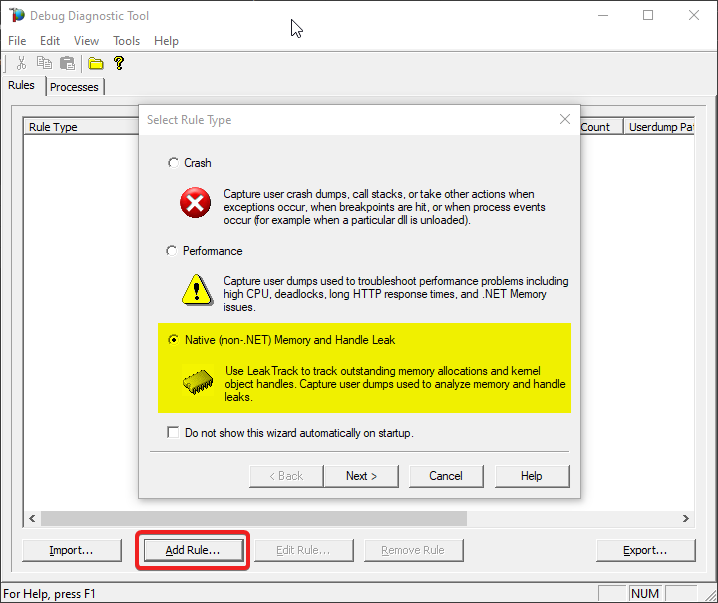
And a pop-up will come, to create a rule for dump collection. Select Memory and Handle Leak, then Next.
#3: Select process by PID
You should see the list of processes now: please select the worker process from the list which you’re having the memory problem. Press Next.
If you have multiple worker processes, you can use command-line utility appcmd.exe from an administrative console to see the list of worker processes with associated application pools.
> C:WindowsSystem32inetsrvappcmd.exe list wp

#4: Configure
On the next window:
Select the maximum number of dumps you would collect (you’ll have the chance to set it later too). A minimum of 3 dumps would be needed for an analysis.
Then press Configure on Userdump generation section.

#5: First dump in series
Select Generate userdump when private bytes reach option and set the value to whatever you know it should be the normal consumption – let’s say 900 MB.
#6: Next dumps in series
Set the and each additional … MB threafter option to – let’s say – 300 MB and finally Save & Close.
This will collect dump when memory consumption goes up to 900 Megs and will continue to take dump for each additional 300 Megs
(until the maximum number of dumps is reached, set in the previous/parent window).

#7: Cleanup investigated process
Select Auto-unload Leak Track when rule is completed or deactivated on Rule completion section.
(DebugDiag injects a module in worker process to do its job; we shouldn’t leave the module there.)
#8: Place cap on dumps count
Set Maximum number of userdumps created by this rule to at least 3 (10 is the default).
The more, the better; but mind the space on disk.

#9: Dumps location
After selecting Next, you will set the location where the dumps will be written.
Please make sure that there is enough disk space on the drive where dumps are collected. Each process dump will take space in the disk approximately the same size the process uses in memory (column Commit Size in Task Manager). For example, if the w3wp.exe process memory usage is ~2 GB, then the size of each dump file will be around 2 GB.
Please do not choose a disk in network/UNC; choose a local disk.

#10: Go!
Finally activate the rule

#11: Make sure we do get dumps
After that observe the dump count in the main DebugDiag window.
You need to re-create the leak definition if the PID/Process ID changes in the Task Manager for the worker process.
You can tweak the memory tracking values differently based on your observations.
Eg. Start from 1.5 GB and take additional dump for every additional 500 MB etc.
#12: Upload
Archive each dump file in its own ZIP and prepare to hand over to the support engineer; upload in a secure file transfer space.
Remember my article about how exceptions are handled and how to collect memory dumps to study them. We can double check if a crash occurred or not: read about w3wp.exe crashes.
Aside: Just in case you are wondering what I use to capture screenshots for illustrating my articles, check out this little ShareX application in Windows Store.
by Contributed | Jul 22, 2021 | Technology
This article is contributed. See the original author and article here.
Call Summary:
Unfortunately, we had technical difficulties and were unable to record this month’s call. We’ll record the presentations again and update this blog with links when they are ready.
This month’s community call featured presentations:
- Shared mailboxes in Outlook – Juan Balmori (Microsoft) and Ankush Oberoi (Microsoft) discussed shared mailboxes and shared folders. Shared mailbox is now in preview and we encourage you to try it out and give us feedback at https://github.com/OfficeDev/office-js/issues.
- Message recipients changed event for Outlook – Elizabeth Samuel (Microsoft) shared a new PnP sample demonstrating how to use the Recipients Changed event to tag an email when there are external recipients.
Q&A (Question & Answers)
Due to the technical difficulties we had on this call, we could not access the chat to read your questions and provide follow-up. If you had a question that did not get answered during the call, or in this blog, please reach out to us by using our short survey form. We’ll address any questions you have during the next call.
Can you add some additional error handling around failure cases for an Outlook add-in that uses the On-send event? We have a scenario where if an On-send add-in fails due to service outage users are unable to send emails unless an admin performs a companywide deactivation of the add-in. It would be helpful to let end-users still send their emails if the On-send add-in fails to load or throws an unhandled exception.
That’s by design for the On-send event when we released the 1.8 requirement set. The good news is that the team is working on enabling a new version of this event that will deal with the “add-in unavailable” cases. We are working to get this into preview soon, so please keep an eye out on future community calls.
On the iOS and Android platforms, you only support Outlook API 1.5. Do you think we will see support for 1.6+ before 2022?
We have this in our backlog, but we don’t yet have an ETA.
Outlook on mobile still does not support compose mode add-ins, or the On-send event. This was a highly requested feature on the UserVoice system. When will Outlook on mobile support both of these? How did the ‘Exclaimer’ add-in from June 2021’s community call work on Outlook mobile without support for compose mode add-ins?
We have this in our backlog, but we don’t yet have an ETA. The Exclaimer add-in isn’t designed for use on Outlook on mobile.
Is there a way to write a CSV file to the local computer’s storage where the add-in is running?
Office Add-ins run in a browser runtime and only have the capabilities of any web app running in a browser. It’s not possible to write directly to disk from the browser in any way that works cross-platform. A recommended approach to write to a CSV file is to write to files using Microsoft Graph and OneDrive.
Resources
Outlook shared mailbox
PnP: Use Outlook event-based activation to tag external recipients (preview)
Office Add-ins community call
Office Add-ins feedback
The next Office Add-ins community call is on Wednesday, August 11, 2021 at 8:00AM PDT. Get the calendar invite at https://aka.ms/officeaddinscommunitycall.
by Contributed | Jul 21, 2021 | Technology
This article is contributed. See the original author and article here.
This blog is part of the Change Data Capture in Azure SQL Databases Blog Series, which started with the announcement on releasing CDC in Azure SQL Databases in early June 2021. You can view the release announcement here: https://aka.ms/CDCAzureSQLDB
Introducing Change Data Capture in Azure SQL Databases
Change data capture (CDC) provides historical change information for a user table by capturing both the fact that Data Manipulation Language (DML) changes (insert / update / delete) were made and the changed data. Changes are captured in real time by using a capture process that reads changes from the transaction log and places them in corresponding change tables. These change tables provide a historical view of the changes made over time to source tables. CDC functions enable the change data to be consumed easily and systematically.
CDC is now available in public preview in Azure SQL, enabling customers to track data changes on their Azure SQL Database tables in near real-time. Now in public preview, CDC in PaaS offers similar functionality to SQL Server and Azure SQL Managed Instance CDC, providing a scheduler which automatically runs change capture and cleanup processes on the change tables.
Streaming Change Data to External Targets
Data integration platforms such as Striim can integrate with your CDC-enabled Azure SQL Database to stream data changes to diverse targets in real-time.
“Real-time information is vital to the health of enterprises,” says Codin Pora, VP of Technology and Partnership at Striim. “Striim is excited to support the new change data capture (CDC) capabilities of Azure SQL Database and help companies drive their digital transformation by bringing together data, people, and processes. Striim, through its Azure SQL Database CDC pipelines, provides real-time data for analytics and intelligence workloads, operational reporting, ML/AI implementations and many other use cases, creating value as well as competitive advantage in a digital-first world. Striim builds continuous streaming data pipelines with minimal overhead on the source Azure SQL Database systems, while moving database operations (inserts, updates, and deletes) in real time with security, reliability, and transactional integrity.”
To learn more about using Striim for real-time ETL to Azure SQL Databases, go here. You can also try out setting up an ETL pipeline to your chosen Azure SQL Database by using Striim’s free trial.
Current Use Case
For this tutorial, we will use Striim to send CDC change data from an Azure SQL Database to another Azure SQL Database target in a separate region. The source database is enabled for CDC. Apart from that, each table that is tracked for data changes is enabled for CDC. To learn more about enabling and disabling CDC on databases and tables, go here.
Striim will connect to the source database and will push CDC changes from the change tables to the downstream target. This can be helpful for customer scenarios such as global data synchronization (i.e. keep databases in different regions around the world synchronized) or distributed applications (i.e. synchronize data across databases that store diverse workloads).
Steps for Sending CDC Data Changes from an Azure SQL Database with Striim
- Create, purchase and deploy your solution by following these steps: Striim with Azure Storage or SQL Database
- In the Striim web GUI, go to the Apps section.
- Click on the Add App button to start a new app. Given our scenario, we will start a new app from scratch by clicking on the Start From Scratch button. Depending on your use case, you might need one app to run an initial snapshot of your source database and one separate app to replicate incremental changes using CDC. For this scenario, you will get zero downtime migration. However, you might decide to execute your initial load outside of Striim by using backup and restore tools. For the purposes of this demo, we will have two apps – one for running an initial load (SQLDBInitLoadTest app) and one for replicating incremental changes from source to target database, for which CDC needs to be enabled on the source database (SQLDBCDCTest app).
- We will start with the SQLDBInitLoadTest app configuration. In the Name your App section, give your app a name and a namespace (namespaces are logical groupings of applications). Click Save. 5. From the drag-and-drop Striim web UI, select your source, which in our case will be SQLDbInitLoad_source DatabaseReader. Learn more about Database Readers here. Configure the Adapter, Connection URL (JDBC), Username, Password, and the Output, which can be either new or existing. You can select the Tables to read from as well. In our case, we will send the initial load to the SQLDbInitLoad_stream, which will send it down to target.
- When configuring the target, in our case SQLDbInitLoad_target, edit the Adapter (DatabaseWriter), Connection URL (JDBC), Username, Password, Tables (comma-separated pairs of source-target tables).
- Once you have configured the source, stream, and target, Deploy the app and Start the app. The initial snapshot of the source database should show up in the target database. In case there are errors starting the app, you can use the Message Log for debugging, then Undeploy the app and Resume again once the errors have been fixed. In case of networking errors, make sure that your Client IP address is allowed to access the database server; you can enable access within the Azure Portal (Update Server Firewall Rules).
- As your application is running, you can monitor the progress for the replication, as seen in the screenshot below. Once the initial load is completed, you should check your target database and see that it’s in sync with the source.
- Now that the initial load is complete, we will configure the app for replicating incremental changes from source to target. For this step, CDC must be enabled on the source database and tracked tables. To learn more about enabling and disabling CDC on databases and tables, go here.
- Similar to configuring your source/stream/target on the SQLDbInitLoadTest app, now go to the SQLDBCDCTest app and configure your source (SQLDBCDC_source), stream (SQLDBCDC_stream), and target (SQLDBCDC_target).
- Deploy and Start app. Your incremental data changes should be replicating to the target.
One of the benefits of Striim is that it supports in-flight transformations and processing as the data flows through its in-memory data pipelines for filtering, aggregating, enrichment, and alerting in real time. Many transformations are available out of the box as a drag-and-drop item from the Striim Flow Designer for a variety of popular operations, Striim Continuous Query (CQ) functionality allows users to write their own custom SQL code to run and act on their streaming data as it flows through the pipeline.
Blog Series for Change Data Capture in Azure SQL Databases
We are happy to continue the bi-weekly blog series for customers who’d like to learn more about enabling CDC in their Azure SQL Databases! This series explores different features/services that can be integrated with CDC to enhance change data functionality.

Recent Comments