Model understanding with Azure Machine Learning
This article is contributed. See the original author and article here.
Overview
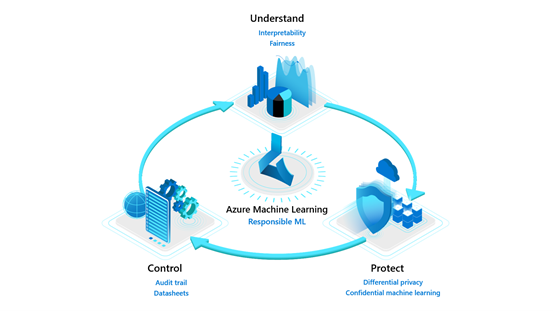
Model interpretability and fairness are part of the ‘Understand’ pillar of Azure Machine Learning’s Responsible ML offerings. As machine learning becomes ubiquitous in decision-making from the end-user utilizing AI-powered applications to the business stakeholders using models to make data-driven decisions, it is necessary to provide tools at scale for model transparency and fairness.
Explaining a machine learning model and performing fairness assessment is important for the following users:
- Data scientists and model evaluators – At training time to help them to understand their model predictions and assess the fairness of their AI systems, enhancing their ability to debug and improve models.
- Business stakeholders and auditors – To build trust with defined ML models and deploy them more confidently.
Customers like Scandinavian Airlines (SAS) and Ernst & Young (EY) put interpretability and fairness packages to the test to be able to deploy models more confidently.
- SAS used interpretability to confidently identify fraud in its EuroBonus loyalty program. SAS data scientists could debug and verify model predictions using interpretability. They produced explanations about model behavior that gave stakeholders confidence in the machine learning models and assisted with meeting regulatory requirements.
- EY utilized fairness assessment and unfairness mitigation techniques with real mortgage adjudication data to improve the fairness of loan decisions from having an accuracy disparity of 7 percent between men and women to less than 0.5 percent.
We are releasing enhanced experiences and feature additions for the interpretability and fairness toolkits in Azure Machine Learning, to empower more ML practitioners and teams to build trust with AI systems.
Model understanding using interpretability and fairness toolkits
These two toolkits can be used together to understand model predictions and their fairness through a loan allocation scenario using For this demonstration, we shall treat this as a loan decision problem. Let’s say that the label indicates whether each individual repaid a loan in the past. We will use the data to train a predictor to predict whether previously unseen individuals will repay a loan or not. The assumption is that the model predictions are used to decide whether an individual should be offered a loan.

Identify your model’s fairness issues
Our revamped fairness dashboard can help uncover the harm of allocation which leads to the model unfairly allocating loans among different demographic groups. The dashboard can additionally uncover harm of quality of service which leads to a model failing to provide the same quality of service to some people as they do to others. Using the fairness dashboard, you can identify if our model treats different demographics of sex unfairly.
Dashboard configurations
When you first load the fairness dashboard, you need to configure it with desired settings, including:
- selection of your sensitive demographic of choice (e.g., sex[1])
- model performance metric (e.g., accuracy)
- fairness metric (e.g., demographic parity difference).
Model assessment view
After setting the configurations, you will land on a model assessment view where you can see how the model is treating different demographic groups.
https://channel9.msdn.com/Shows/Docs-AI/loan-allocation-fairness-toolkit/player
Our fairness assessment shows an 18.3% disparity in the selection rate (or demographic group difference). According to that insight, 18.3% more males are receiving qualifications for loan acceptance compared to females. Now that you’ve seen some unfairness indicators in your model, you can next use our interpretability toolkit to understand why your model is making such predictions.
Diagnose your model’s predictions
The new revamped interpretability dashboard greatly improves the user experience of the previous dashboard. In the loan allocation scenario, you can understand how a model treats female loan applicants differently than male loan applicants using the interpretability toolkit:
https://channel9.msdn.com/Shows/Docs-AI/loan-allocation-interpretability/player
- Dataset cohort creation: You can slice and dice your data into subgroups (e.g., female vs. male vs. unspecified) and investigate or compare your model’s performance and explanations across them.
- Model performance tab: With the predefined female and male cohorts, we can observe the different prediction distributions between males and female cohorts, with females experiencing higher probability rates of being rejected for a loan.
- Dataset explorer tab: Now that you have seen in the model performance tab how females are rejected at a higher rate than males, you can use the data explorer tab to observe the ground truth distribution between males and females. For males, the ground truth data is well balanced between those receiving a rejection or approval whereas, for females, the ground truth data is heavily skewed towards rejection thereby explaining how the model could come to associate the label ‘female’ with rejection.
- Aggregate feature importance tab: Now we observe which top features contribute to the model’s overall prediction (also called global explanations) towards loan rejection. We sort our top feature importances by the Female cohort, which indicates that while the feature for “Sex” is the second most important feature to contribute towards the model’s predictions for individuals in the female cohort, they do not influence how the model makes predictions for individuals in the male cohort. The dependence plot for the feature “Sex” also shows that only the female group has positive feature importance towards the prediction of being rejected for a loan, whereas the model does not look at the feature “Sex” for males when making predictions.
- Individual feature importance & What-If tab: Drilling deeper into the model’s prediction for a specific individual (also called local explanations), we look at the individual feature importances for only the Female cohort. We select an individual who is at the threshold of being accepted for a loan by the model and observe which features contributed towards her prediction of being rejected. “Sex” is second most important feature contributing towards the model prediction for this individual. The Individual Conditional Expectation (ICE) plot calculates how a perturbation for a given feature value across a range can impact its prediction. We select the feature “Sex” and can see that if this feature had been flipped to male, the probability of being rejected is lowered drastically. We create a new hypothetical What-If point from this individual data point and switch only the “Sex” from female to male, and observe that without changing any other feature related to financial competency, the model now predicts that this individual will have their loan application accepted.
Once some potential fairness issues are observed and diagnosed, you can move to mitigate those unfairness issues.
Mitigate unfairness issues in your model
The unfairness mitigation part is powered by the Fairlearn open-source package which includes two types of mitigation algorithms: postprocessing algorithms (ThresholdOptimizer) and reduction algorithms (GridSearch, ExponentiatedGradient). Both operate as “wrappers” around any standard classification or regression algorithm. GridSearch, for instance, treats any standard classification or regression algorithm as a black box, and iteratively (a) re-weight the data points and (b) retrain the model after each re-weighting. After 10 to 20 iterations, this process results in a model that satisfies the constraints implied by the selected fairness metric while maximizing model performance. ThresholdOptimizer on the other hand takes as its input a scoring function that underlies an existing classifier and identifies a separate threshold for each group to optimize the performance metric, while simultaneously satisfying the constraints implied by the selected fairness metric.
The original fairness dashboard also enables the comparison of multiple models, such as the models produced by different learning algorithms and different mitigation approaches. Bypassing the dominated models of GridSearch for instance, you can see the unmitigated model on the upper right side (with the highest accuracy and highest demographic parity difference) and can click on any of the mitigated models to observe them further. This allows you to examine trade-offs between performance and fairness.

Comparing results of unfairness mitigation
After applying the unfairness mitigation, we go back to the interpretability dashboard and compare the unmitigated model with the mitigated model. In the figure below, we see a more even probability distribution for the female cohort for the mitigated model on the right:

Revisiting the fairness assessment dashboard, we also see a drastic decrease in demographic parity difference from 18.8% (unmitigated model) to 0.412% (mitigated model):

Saving model explanations and fairness metrics to Azure Machine Learning Run History
Azure Machine Learning’s (AzureML) interpretability and fairness toolkits can be run both locally and remotely. If run locally, the libraries will not contact any Azure services. Alternatively, you can run the algorithms remotely on AzureML compute and log all the explainability and fairness information into AzurML’s run history via the AzureML SDK to save and share them with other team members or stakeholders in AzureML studio.


AzureML’s Automated ML supports explainability for its best model as well as on-demand explainability for any other models generated by Automated ML.
Learn more
Explore this scenario and other sample notebooks in the Azure Machine Learning sample notebooks GitHub.
Learn more about the Azure Machine Learning service.
Learn more about Responsible ML offerings in Azure Machine Learning.
Learn more about interpretability and fairness concepts and see documentation on how-to guides for using interpretability and fairness in Azure Machine Learning.
Get started with a free trial of the Azure Machine Learning service.
[1] This dataset is from the 1994 US Census Bureau Database where “sex” in the data was limited to binary categorizations.







Recent Comments