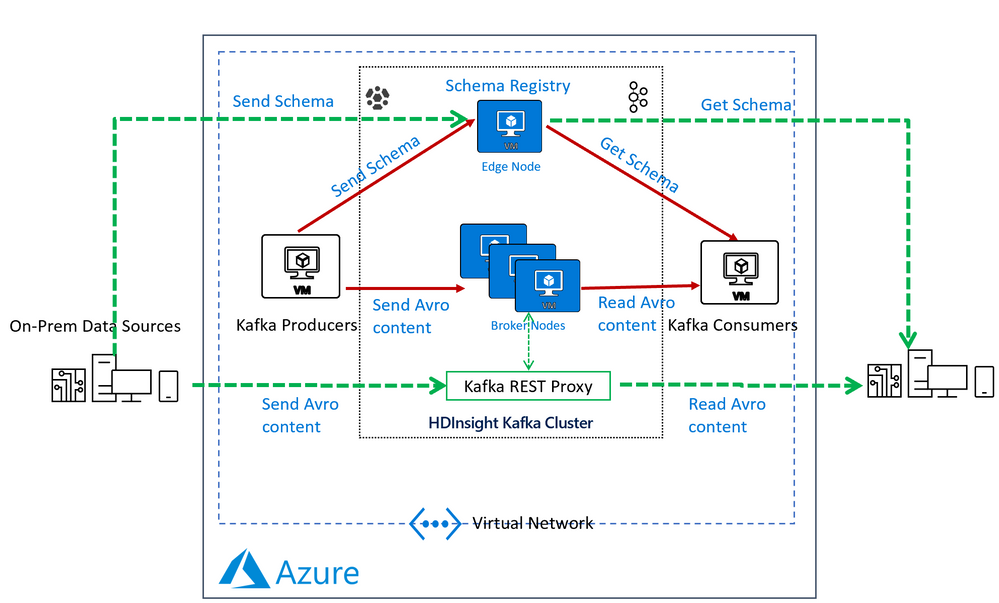
In the next section we would configure the Confluent Kafka Schema Registry that we installed on the edge node
Configure the Confluent Schema Registry
The confluent schema registry is located at /etc/schema-registry/schema-registry.properties and the mechanisms to start and stop service executables are located at the /usr/bin/ folder.
The Schema Register needs to know the Zookeeper service to be able to interact with HDInsight Kafka cluster. Follow the below steps to get the details of the Zookeeper Quorum.
- Set up password variable. Replace
PASSWORD with the cluster login password, then enter the command
export password='PASSWORD'
- Extract the correctly cased cluster name
export clusterName=$(curl -u admin:$password -sS -G "http://headnodehost:8080/api/v1/clusters" | jq -r '.items[].Clusters.cluster_name')
- Extract the Kafka Zookeeper hosts
export KAFKAZKHOSTS=$(curl -sS -u admin:$password -G https://$clusterName.azurehdinsight.net/api/v1/clusters/$clusterName/services/ZOOKEEPER/components/ZOOKEEPER_SERVER | jq -r '["(.host_components[].HostRoles.host_name):2181"] | join(",")' | cut -d',' -f1,2);
- Validate the content of the
KAFKAZKHOSTS variable
echo $KAFKAZKHOSTS
- Zookeeper values appear in the below format . Make a note of these values as they will be used later
zk1-ag4kaf.q2hwzr1xkxjuvobkaagmjjkhta.gx.internal.cloudapp.net:2181,zk2-ag4kaf.q2hwzr1xkxjuvobkaagmjjkhta.gx.internal.cloudapp.net:2181
- To extract Kafka Broker information into the variable KAFKABROKERS use the below command.
export KAFKABROKERS=$(curl -sS -u admin:$password -G https://$clusterName.azurehdinsight.net/api/v1/clusters/$clusterName/services/KAFKA/components/KAFKA_BROKER | jq -r '["(.host_components[].HostRoles.host_name):9092"] | join(",")' | cut -d',' -f1,2);
Check to see if the Kafka Broker information is available
echo $KAFKABROKERS
- Kafka Broker host information appears in the below format
wn1-kafka.eahjefyeyyeyeyygqj5y1ud.cx.internal.cloudapp.net:9092,wn0-kafka.eaeyhdseyy1netdbyklgqj5y1ud.cx.internal.cloudapp.net:9092
- Open the Schema Registry properties files in edit mode
sudo vi /etc/schema-registry/schema-registry.properties
- By default the file would contain the below parameters
listeners=http://0.0.0.0:8081
kafkastore.connection.url=zk0-ohkl-h:2181,zk1-ohkl-h:2181,zk2-ohkl-h:2181
kafkastore.topic=_schemas
debug=false
- Replace the kafastore.connection.url variable with the Zookeeper string that you noted earlier. Also replace the debug variable to true . If set to true true, API requests that fail will include extra debugging information, including stack traces. The properties files now looks like this.
listeners=http://0.0.0.0:8081
kafkastore.connection.url=zk1-ag4kaf.q2hwzr1xkxjuvobkaagmjjkhta.gx.internal.cloudapp.net:2181,zk2-ag4kaf.q2hwzr1xkxjuvobkaagmjjkhta.gx.internal.cloudapp.net:2181
kafkastore.topic=_schemas
debug=true
cd /bin
$ sudo schema-registry-start /etc/schema-registry/schema-registry.properties
- Schema Registry Starts and starts listening for requests.
...
...
[2020-03-22 13:24:49,089] INFO Adding listener: http://0.0.0.0:8081 (io.confluent.rest.Application:190)
[2020-03-22 13:24:49,154] INFO jetty-9.2.24.v20180105 (org.eclipse.jetty.server.Server:327)
[2020-03-22 13:24:49,753] INFO HV000001: Hibernate Validator 5.1.3.Final (org.hibernate.validator.internal.util.Version:27)
[2020-03-22 13:24:49,902] INFO Started o.e.j.s.ServletContextHandler@40844aab{/,null,AVAILABLE} (org.eclipse.jetty.server.handler.ContextHandler:744)
[2020-03-22 13:24:49,914] INFO Started NetworkTrafficServerConnector@33fe57a9{HTTP/1.1}{0.0.0.0:8081} (org.eclipse.jetty.server.NetworkTrafficServerConnector:266)
[2020-03-22 13:24:49,915] INFO Started @2780ms (org.eclipse.jetty.server.Server:379)
[2020-03-22 13:24:49,915] INFO Server started, listening for requests... (io.confluent.kafka.schemaregistry.rest.SchemaRegistryMain:45)
-
With the Schema Registry running in one SSH session , launch another SSH window and try out some basic commands to ensure that Schema Registry is working as expected.
-
Register a new version of a schema under the subject “Kafka-key” and note the output
$ curl -X POST -i -H "Content-Type: application/vnd.schemaregistry.v1+json"
--data '{"schema": "{"type": "string"}"}'
HTTP/1.1 200 OK
Date: Sun, 22 Mar 2020 16:33:04 GMT
Content-Type: application/vnd.schemaregistry.v1+json
Content-Length: 9
Server: Jetty(9.2.24.v20180105)
- Register a new version of a schema under the subject “Kafka-value” and note the output
curl -X POST -i -H "Content-Type: application/vnd.schemaregistry.v1+json"
--data '{"schema": "{"type": "string"}"}'
HTTP/1.1 200 OK
Date: Sun, 22 Mar 2020 16:34:18 GMT
Content-Type: application/vnd.schemaregistry.v1+json
Content-Length: 9
Server: Jetty(9.2.24.v20180105)
- List all subjects and check the output
curl -X GET -i -H "Content-Type: application/vnd.schemaregistry.v1+json"
http://localhost:8081/subjects
HTTP/1.1 200 OK
Date: Sun, 22 Mar 2020 16:34:39 GMT
Content-Type: application/vnd.schemaregistry.v1+json
Content-Length: 27
Server: Jetty(9.2.24.v20180105)
["Kafka-value","Kafka-key"]
Send and consume Avro data from Kafka using schema registry
- Create a fresh Kafka Topic
agkafkaschemareg
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 3 --partitions 8 --topic agkafkaschemareg --zookeeper $KAFKAZKHOSTS
-
Use the Kafka Avro Console Producer to create a schema , assign the schema to the Topic and start sending data to the topic in Avro format. Ensure that the Kafka Topic in the previous step is successfully created and that $KAFKABROKERS has a value in it.
-
The schema we are sending is a Key: Value Pair
Key : Int
Value
{
"type": "record",
"name": "example_schema",
"namespace": "com.example",
"fields": [
{
"name": "cust_id",
"type": "int",
"doc": "Id of the customer account"
},
{
"name": "year",
"type": "int",
"doc": "year of expense"
},
{
"name": "expenses",
"type": {
"type": "array",
"items": "float"
},
"doc": "Expenses for the year"
}
],
"doc:": "A basic schema for storing messages"
}
- Use the below command to start the Kafka Avro Console Producer
/usr/bin/kafka-avro-console-producer --broker-list $KAFKABROKERS --topic agkafkaschemareg --property parse.key=true --property key.schema='{"type" : "int", "name" : "id"}' --property value.schema='{ "type" : "record", "name" : "example_schema", "namespace" : "com.example", "fields" : [ { "name" : "cust_id", "type" : "int", "doc" : "Id of the customer account" }, { "name" : "year", "type" : "int", "doc" : "year of expense" }, { "name" : "expenses", "type" : {"type": "array", "items": "float"}, "doc" : "Expenses for the year" } ], "doc:" : "A basic schema for storing messages" }'
- When the producer is ready to accept messages start sending the messages in the predefined Avro schema format. Use the Tab key to create spacing between the Key and Value.
1 TAB {"cust_id":1313131, "year":2012, "expenses":[1313.13, 2424.24]}
2 TAB {"cust_id":3535353, "year":2011, "expenses":[761.35, 92.18, 14.41]}
3 TAB {"cust_id":7979797, "year":2011, "expenses":[4489.00]}

















Recent Comments