by Scott Muniz | Jul 29, 2020 | Uncategorized
This article is contributed. See the original author and article here.
Recently, I tried to use the SQL Server 2019 import certificate feature in configuration manager, however, when I import by the pfx file, it prompted me errors at the last step as below:
Errors or Warnings for certificate:C:UsersAdministrator.CONTOSODesktopcerttest.pfx
———————–
The selected certificate is a self signed certificate. Proceeding with this certificate isn’t advised
Error:
The selected certificate name does not match FQDN of this hostname. This property is required by SQL Server
Certificate name: Contoso-DC-CA
Computer name: Node1.Contoso.lab
Error:
The selected certificate does not have the KeySpec Exchange property. This property is required by SQL Server to import a certificate.
Import error: 0x2, Windows Native Error: 0x80092004
The selected certificate does not contain server authentication key usage property. This property required to import certificate to SQL Server.
Actually I have configured the CN the same as my node FQDN, and ‘Contoso-DC-CA’ was the issuer’s name, below is the CheckSQLSSL tool running result:
Store: Local Machine – Personal (CERT_SYSTEM_STORE_LOCAL_MACHINE)
**************************************
> CERT =>Node1.Contoso.Lab
>
OK > Subject name: Node1.Contoso.Lab
FQDN: Node1.Contoso.lab
OK > AT_KEYEXCHANGE is set
OK > Time stamp is valid
OK > Server Authentication 1.3.6.1.5.5.7.3.1
OK > Friendly name: Node1.Contoso.Lab
That’s strange, so I begin to think of where the certificate name get from code, after debugging I found when initialize the certificate object, the certificate name has already been the issuer’s name:
[+0x224] m_strCertname : 0x8054f88 : “Contoso-DC-CA” [Type: wchar_t *]
[+0x228] m_bProcessedSans : 0 [Type: int]
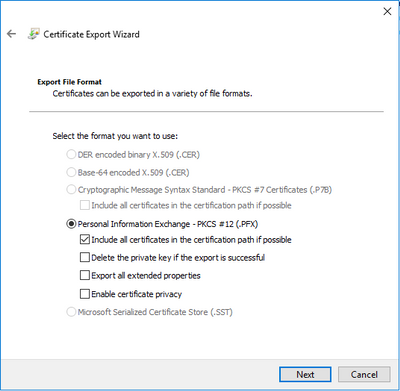
So what makes it get the issuer’s name? After checking the certificate generate process again, I found it was due to an option during export certificate. When you export a certificate to file, “Include all certificates in the certification path if possible” is checked by default, if you check this the exported file will include certificate chain, the root cert’s CN was the CA’s name, that’s why the certificate name always shown as the CA’s name.

This option is not notable because it’s a default option, you may forget to uncheck it. How do I find it? I just tried to import this .pfx file in certmgr.msc, and import the pfx here again, then I found 2 certs were imported, one is the root cert, one is the cert I applied.
So the solution is easy, just uncheck the option and export the pfx file again, you will get it succeeded :)
by Scott Muniz | Jul 29, 2020 | Uncategorized
This article is contributed. See the original author and article here.
Our experience shows that cloud technology, and the architecture used to create solutions can have a substantial impact on human lives. Positive human experiences can encourage broader adoption of products, services, or ideas, and from a change management perspective can help individuals, teams, and organizations achieve lasting change. To positively affect lives, solution architects, sponsors, and stakeholders need to do their part by help transform the experiences of those interacting/transacting with their organization by designing adaptable, end-to-end data and analytics solutions. Architectures that have shown good results for our clients are based on these architectural styles (big data, event-driven, microservices).
Let’s start by looking at some of the architectural components and layers of an enterprise architecture.
Architectural Components
The major architectural components of any system are the software and the hardware. All software systems can be divided into four basic functions. These four functions (data storage, data access logic, application logic, and presentation logic) are the basic building blocks of any information system. The three primary hardware components of a system are client computers, servers, and the network that connects them.
System Analysis and Design, Fifth Edition by Roberta M. Roth; Barbara Haley Wixom; Alan Dennis Published by Wiley, 2012
When the storage, compute, network, database, web app, analytics, and AI and Machine Learning components are on the Azure data and analytics platform great things are possible. Here are some Enterprise Architecture diagrams that focus on the layers that make up a solution architecture.
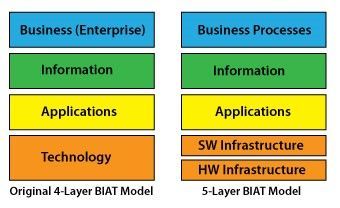
Enterprise Architecture (EA) Layers

Conventional BIAT Diagram and the 5-Layer BIAT Diagram
http://eitbokwiki.org/Enterprise_Architecture
This post uses the term data vs information because in the world of Data & AI the industry terms are more data centric: Big Data, Data Engineer, Data Science, Data Analyst, Data Warehouse, Data Mart, Data Model, Datastore, Database, Data Visualization, Data Wrangling, Data Mining, Data Lake, DataFrame, Change Data Capture, and Master Data. This is a lot of information, but it is all data! Combining the two references above you might end up with a diagram that looks like this:

Darwin’s munging (in a data wrangling kind of way) of EA layers and Architectural Components
Real-life scenario
For a real-life scenario to test some of this out, let’s use moving stuff (furniture, boxes, lamps, rugs, chairs tables) from one place to another (warehouse, house, apartment, office). To do this most people either hire a moving company, or if you like to be hands-on, do-it-yourself and rent a trailer or truck. Renting moving equipment is a very complex logistics business process. The moving equipment rental business process has many actors (users of the system) that are human users, and there is little control over the human users involved in the system (customer might not take the truck or trailer back in time, extend their rental, or return equipment to a location that has no demand for the being rented the next day); thus the need to check for human errors, contain bias, expedite last minute changes, and have the privileges setup to reduce any harm to the parties involved. It is real life, tough to automate, and kind of out of control. Such a process to far less controlled than fulfilling an online order from a online retailers warehouse to your house. Throw in Covid-19, with requirements to clean equipment, wear masks, and social distance and you have potential for some chaos! For example, no more paper rental agreement which probably changes the process.
Recommended solution architecture to approach and organize the chaos
What are some of the things to consider when building a data and analytics solution that works for the real-life scenario described? Using a Cloud-based Data, AI/ML, Modern Data Management, and Modern Application focused approach the design of an End-to-End (E2E) solution might use and combine these capabilities:
- OLTP (Online Transactional Processing) to create, read, update, and delete (CRUD stuff) the transactions in an operational RDBMS (Relational Database Management System) like Azure SQL Database
- NoSQL database like Azure Cosmos DB as the cloud-native operational database to store the data that is better stored in document databases (rental contract, attributes and preferences of the customers and dealers, and profiles of the rental equipment)
- Event-driven architecture to capture all the interactions between the human to human and device actors (emails, texts, social media tweets and Instagram posts, near real-time IoT telemetry data streaming from the fleet of trucks and trailers). Capture events using Azure Event Hub, Azure IoT Hub, Apache Kafka and perform complex event processing using Azure Stream Analytics. Much of this human created data comes from the endless mobile devices that the customers (drivers) use during the lifecycle from reservation – to pick up location – to return location. This also can include SOA/ESB driven application integration via APIs and messaging. This information could be landed in storage, in relational or NoSQL databases, or use Azure Data Explorer – a fast, fully managed data analytics service for real-time analysis on large volumes of data streaming from applications, websites, IoT devices, and more.
- Data Lake storage and Big Data analytical processing like Azure Databricks (Spark) and data integration tools like Azure Data Factory for combining data from the OLTP and operational systems as well as near real-time data streaming from fleet IoT device telemetry in trucks and trailers, from emails, from texts, from chats with chatbots, or from tweets. Change Data Capture, transactional replication and other data movement technologies need consideration here as well.
- Analytical data stores to create modern data warehouses like Azure Synapse Analytics. In fact Azure Synapse Analytics combines all of the capabilities in the first 4 items above and can be used to create HTAP (hybrid transactional and analytical processing) systems using offerings like Azure Synapse Link for Azure Cosmos DB.
- Business Intelligence analysis and data visualizations using Power BI. It is amazing what can be done with Cloud-based BI. The connectivity, capabilities, scalability, security, performance, and affordability make getting started easy.
- AI and Machine Learning like Azure Cognitive Services to process images like the pictures on drivers’ licenses, automating forms, predicting customer sentiment in texts, as well as tools like Azure Machine Learning for data scientists to build and deploy models to suggest next best offers to customers that have similar profiles, or to predict the need for additional insurance coverage or fraudulent activities. Maybe even predict who is having a bad experience and needs a call of support.
- Cloud Native Applications using microservices, serverless, and containers like Docker and container orchestration services like Kubernetes —optimized for cloud scale and performance. Apps built using programming languages like JavaScript and TypeScript, frameworks like React and Angular, and runtime environments like Node.js. With AI and machine learning built in.
Note: You will have some of the capabilities and technologies already in place, so this is an integration-based solution that often extends what you already have. You will want to migrate some of the applications and data sources to Azure, but the data and analytics components (stuff in land, stage, warehouse, information delivery, BI, AI and ML, and applications) are definitely best up on Azure.

Darwin’s end-to-end cloud solution architecture diagram
The diagram above currently excludes Master Data Management (MDM), Data Governance, Data Catalogs, and probably missed something. This post is already broad and complex. This complexity brings all these currently excluded capabilities to a greater level of importance but let’s leave that for another day.
Some of the inspiration for this post comes from the Data Vault methodology. Solutions I have created during the last 25 years used Land, Stage, and Publish tables and schema along with association tables to associate source system keys with surrogate keys. Information delivery was through star schema accessed by BI tools like Power BI. I considered my approach as Kimball-based but in many ways it was actually pretty aligned with the Data Vault methodology, which IMO is a nice blend of the Ralph Kimball and the Bill Inmon approaches to data warehousing. Below is a diagram of the Data Vault architecture.

Building a Scalable Data Warehouse with Data Vault 2.0 by Dan Linstedt and Michael Olschimke
I also found this illustration helpful from the eBook Data Warehouse Automation in Azure for Dummies by Matthew Basile, Clive Bearman, Rajeev Jain, and Kevin Pardue

So, to wrap up and test my real-life scenario, would this architecture improve the experience of someone renting moving equipment? In my opinion as both a solution architect and a consumer, a definitive yes! There are systems, people, and processes in place, but there are things to consider extending to improve the human experience. For example, if the people and processes change the pickup and drop off locations with the customer at too great a frequency; something has to report, predict the negative experience, and then the system, people, and processes have to adopt to prevent the occurrence of such negative experiences. It is the interactions that happen around the transactions that often determine the experience.
There is no immutable master plan for this type of architecture, and you need to get started to realize any of it. You have probably already started, but is something missing that this post helped surface? Start small with a business problem and combine some operational structured data sources and some streaming data sources needed to solve the problem; create some reports in Power BI, and build and deploy ML models to embed into a Power Apps or custom Apps so users can use them. Use Agile and DevOps and iterate on the solution, and then use what you learned and do more projects. Hopefully this post has provided some insights, but it is a journey that requires a growth mindset for the entire organization at the individual, team, and corporate level. Whether you categorize yourself as a consumer, architect, developer, designer, engineer, employee, student, teacher, line of business manager, administrator, or executive; hopefully you are inspired to take that next step in your journey. If you have an idea you would like to discuss, please call, email, or comment. Would love to help turn your vision into reality and help you embrace and harness the chaos in your organization.
Hope you enjoy your summer whether relaxing or productive (does not need to be house painting, could be camping or time at the lake house)!
Stay Safe,
Darwin
by Scott Muniz | Jul 28, 2020 | Uncategorized
This article is contributed. See the original author and article here.
Azure Cognitive Services provides a suite of AI services and APIs that lets developers work with AI technologies without having a deep expertise in machine learning. This post will cover how we can use two of these services together, Custom Vision and Bing Image Search APIs, along with a .net core console application for rapid prototyping of Custom Vision models.
Custom Vision is a service that lets user build and deploy customized computer vision models using their own image datasets. The process of training a customized computer vision model is simplified as the machine learning happening under the hood is all managed by Azure, only the image data for the model itself is required by the user. A separate user interface is also provided as part of the Custom Vision service which makes it very simple to understand and use.
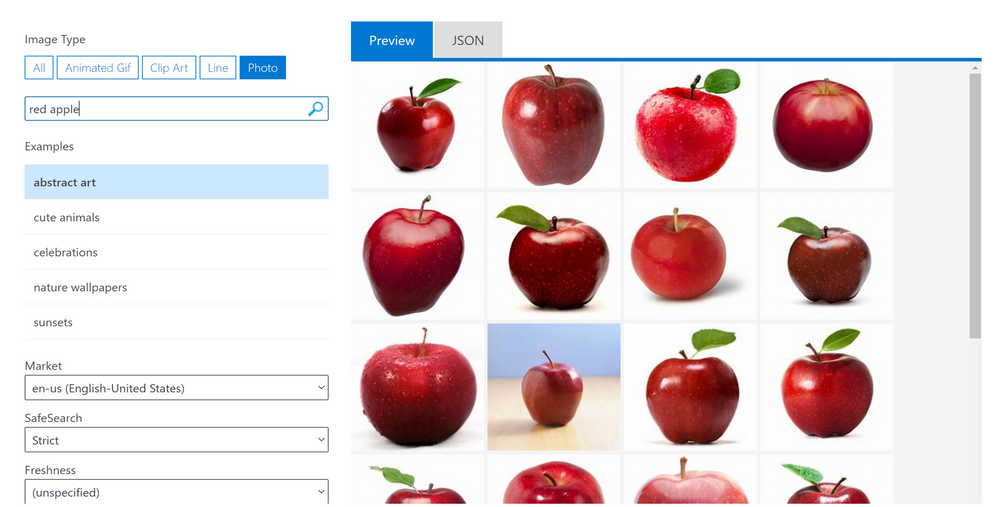
Bing Image Search APIs is a service that executes a search query and returns a result of images and functions very similarly to an image search done the web version of Bing Image Search. Query filters can also be applied as part of the Bing Image Search APIs to refine the results e.g: filtering for specific colours, selecting image type (photograph, clipart, GIF). The image below shows the Bing Image Search APIs through a visual interface that users can try their own search terms on, as well as apply some query filters such as the image type and content freshness.

To create a Custom Vision model, it is recommended to have at least 50 images for each label before beginning to train a model. This can be a time consuming process especially when you have no pre-existing datasets and looking to prototype multiple models. By using a combination of the Bing Image Search APIs and the Custom Vision REST APIs, the process of populating a Custom Vision project with tagged images can be accelerated, and once all the images are in the Custom Vision project and tagged, a model can immediately be trained. The flow of this process is captured in a .net core console application that easily be altered to test this process with different Bing Image Search terms and query filters to understand what results are returned and how to further improve the model. The below diagram shows the flow between the components of this application.

After creating the necessary resources on Azure, the console application of this solution can be opened to specify the name of the tag and the search term to be queried in Bing Image Search. In this example, two subjects are set, the first one with a tag name of “Apple” and a search term of “Red Apple”, and the second one with a tag name of “Pear” and a search term of “Green Pear”. Afterwards, the console application is run and the user populates all the required values such as the resource keys. This will then trigger off the application at it starts with carrying out a search query and populates the specified Custom Vision Project. Once the application has finished running, the Custom Vision project should be populated with tagged images of red apples and green pears. To now train the model, the user can select between two options: quick training and advanced training.
- Quick training trains the model in a few minutes which is good for quick testing of simpler models.
- Advanced training option provides the option of allocating virtual machines over a selected amount of time to train a more in-depth model.

In this example, within 2 minutes after selecting the quick training option, a model for distinguishing between apples and pears has been trained. To test my model, I’ve used a photo of an apple at home which has been correctly identified as being an apple. If the user wanted to expand on this and include more fruit as part of this model, this can easily be done with very minor changes to the code. Otherwise, by also changing the count & offset values when running the console application, more images of apples and pears can be populated in the project to retrain an updated model.

More detailed steps on running this solution are available in the Readme as part of the GitHub repository for this solution which can be used to not just classify between apples and pears but any other examples you have in mind – I have also used this solution to create a Custom Vision model that classifies between 5+ different car models. At the time of writing this post, this solution can be run on the free tiers of both Custom Vision and Bing Image Search APIs so please feel free to try this in your own environment.
Link to GitHub Repository




Recent Comments