Video Transcript:
– Up next, I’m joined by Estefani Arroyo to look at the latest updates to the managed, limitless scale, NoSQL Azure Cosmos DB database and what you can do to get the best cost performance for your smaller apps with the new serverless option for on-demand querying and the Cosmos DB free tier for provisioned throughput. Then for your larger workloads, we’re going to look at how you can gain game changing efficiencies by embedding and partitioning your data as well as leveraging autoscale for cost optimizations. So thanks to Estefani for joining us on Mechanics today.
– Hey Jeremy, thanks for having me on. I’m so excited to be here.
– Thank you, so before we get into the updates, it’s been a while since we’ve looked at Azure Cosmos DB on Mechanics. So why don’t we start by getting everyone on the same page, especially if you might be used to relational databases. So how does Cosmos DB differ?
– Yeah, the biggest thing that separates NoSQL databases like Cosmos DB from traditional relational databases is that there is no enforced schema. This makes them extremely flexible. And this is important because across industries, a good majority of the data generated in day-to-day operations will be semi-structured or unstructured, meaning it doesn’t need to follow a rigid tabular form or schema. It could be metadata or activity data from JSON files generated by IoT devices on the edge, or something like click-stream data from your web apps used to generate personalized, real-time recommendations, or even invoices containing customer information and line items from your payment systems. Really it can be any number of things. And this type of operational data is often high volume with a high change rate, so a flexible schema is key. Which is where Azure Cosmos DB comes in as a fully managed NoSQL database for applications at any scale. It supports multiple data models to represent your data from Graph, which models many to many relationships within your data, to the popular document model, the columnar format, and the key value model as well.
– Okay, so as a developer or database admin, then how would you be able to interact with the data in these models?
– Well, that’s where APIs come in. We have our full-featured Core SQL API, which was designed for Azure Cosmos DB and supports the document model. If you have experience in SQL, this API lets you query data using the familiar SQL syntax. But then we also give you other sets of familiar APIs aligned to data models which let you continue to use your existing language and database skills while still leveraging Azure Cosmos DB.
– So it’s easy then to use your preferred model and also environment to interact with Cosmos DB. And you also mentioned that data volumes can get pretty dynamic and large for this type of operational data. So how does Cosmos DB then handle that?
– Well, Cosmos DB has a scale-out architecture. Compared to traditional relational databases that might reside entirely on a single VM, requiring you to scale up and down with v cores and RAM, Cosmos DB scales in and out by adding and removing nodes, or as we call them physical partitions, which comprise of data you store and the compute you provision. We also have built-in geo redundancy with data replication into any Azure region. In fact, Cosmos DB has an SLA-backed five nines of availability.
– So is Cosmos DB then better suited for larger or smaller apps?
– Well, Cosmos DB works well for any size application. There is no massive scale requirement. And with Cosmo DB, you can start very small, and as operations start to pick up later you can scale out to billions of transactions spread across the globe. And to make Cosmo DB even more accessible for smaller apps, you can now take advantage of serverless for on-demand querying. This makes it viable to run even your smaller apps for less than a dollar a month and only pay by operation.
– And that’s a really good point, because some people might think that Cosmos DB operations can get pretty expensive and that the service actually caters towards larger data operations.
– Yeah, exactly. And that’s something we want to emphasize is not the case. When it comes to cost, one really important concept to understand is the Request Unit, or RU. Think of this like the logical currency for Cosmo DB. It represents the CPU, IOPS, and memory required to perform database operations as a single unit. In our provisioned model, database throughput is the number of RUs provided to you per second. Even though we measure throughput by the second, it’s important to remember this is billed by the hour. And for the serverless model, you only pay for the number of request units consumed by database operations over a one month period. So in either case, you really want to choose the right provisioning model to minimize costs.
– Right, so can you walk us through an example?
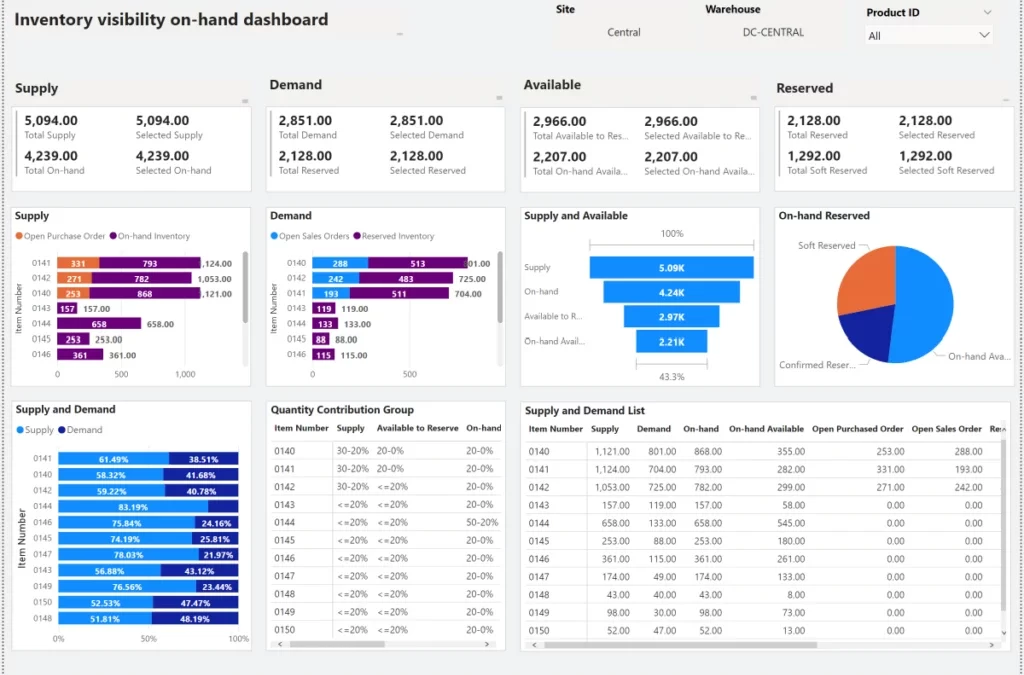
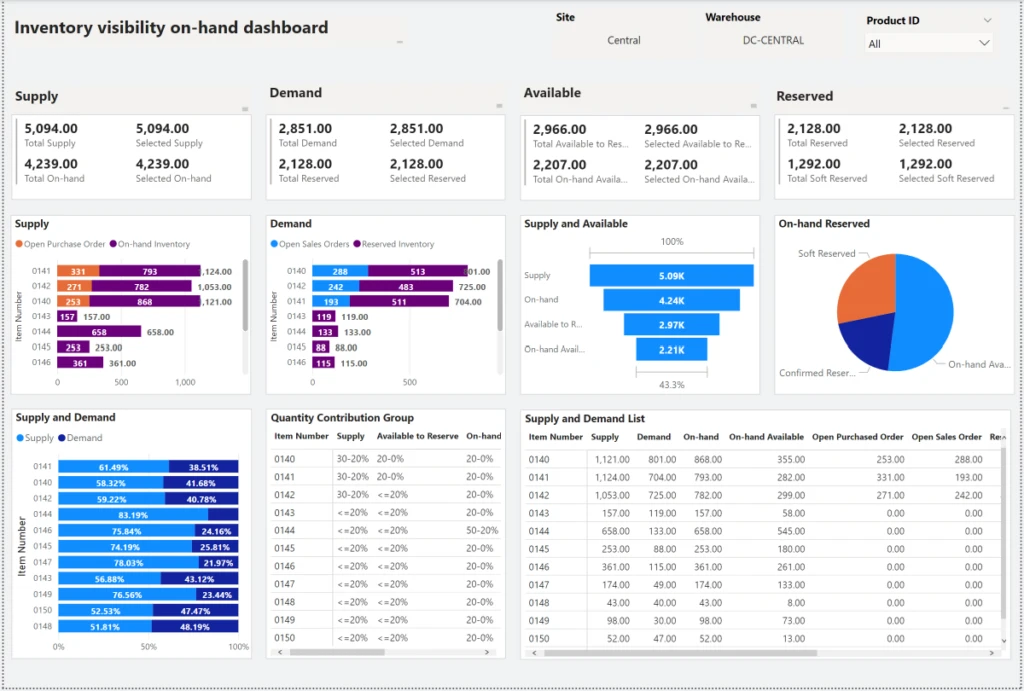
– Sure. Let me show you an example, using our new inexpensive serverless option. Here I have our website open for Adventure Works and it’s an e-commerce app that sells items like outdoor clothing, gear, and outdoor accessories. As a customer, you can log into your profile to get your order history, add items to your wishlist for your next outdoor adventure, and make sure your details are up to date. And as you browse through the products, we’re pulling data from our product databases to see the details. So if I make an order, we’re performing data operations to reserve inventory and write order information to our shopping cart and all the other subsequent steps in the ordering system. So all of these transactions are data operations, reads and writes to various data services. And bringing this back to our concept of RUs, each operation is also consuming request units. So here in our Data Explorer in Azure, let’s take a look at what some of these operations would consume. First, let’s take a look at the customer profile retrieval we had at login. If I manually run the query using an email address, you’ll see it’s consuming about 2.8 RUs. To simulate browsing the product inventory, I can run this query and it consumes around 3.6 RUs. Then as you place an order, this operation takes around 10.3 RUs. So if you add everything up that 16.7 RUs on the low end, but let’s round up to 20 RUs to be safe. And if I received an order per minute, then my throughput is naturally 20 RUs per minute. So doing the math, with a total number of minutes per month, which is about 43,000, that’s 864,000 RUs. So even though that sounds like quite a bit, it turns out to be less than 28 cents, which is the cost for one million RUs. And based on our estimated usage of 864,000, that works out to be 24 cents per month, which is pretty neat. And you can even see that here, when we view our estimated costs in the portal.
– Right and as you said, this can scale all the way down to zero, so you might have hours or days without any activity or consuming any RUs, or maybe you’re not getting 43,000 orders in every month and this could be even less. So what if you want to have provisioned capacity so that the service is always warm and ready to go?
– So in that case, that’s where you want to use provisioned throughput, which also lets you take advantage of increased scalability and multi-region support. Starting small, we have a free tier for Cosmos DB, where we recently doubled the number of RUs. You could now get up to 1,000 request units per second and 25 gigs of storage, and it comes with the same SLAs, which is also great for testing scenarios. If you think about our customer example with transaction and invoice operations, which use around 20 RUs, in that case you can do about 50 types of these operations per second for free.
– And at some point you might actually outgrow a thousand RUs per second on provisioned throughput with the free tier. So why don’t we dig into what you can do to run your NoSQL workloads at scale while keeping all of it as efficient as possible?
– The key to efficiency is getting the data model right. I’ll walk through a few examples using the SQL API document model which is the most popular. And to get this right from the beginning, you’ll want to look at the read and write operations you want Cosmo DB to perform as you structure your model. So for example, if you have a read-heavy application, embedding or de-normalizing helps ensure results come in fast without using JOINS. And by combining the number of related entities into a single document, we reduce the total number of documents in the database. While this increases the size of the document, read results can be returned a lot faster. On the other hand, if you have a write-heavy application, it’s better to use referencing, or normalizing, like you would for a relational database. By creating unique entities that reference one another, you can break up write requests and break down large documents to speed up your write operations. This leads to more small documents and duplication, but will increase performance when doing a large number of writes and updates. So we want to use a flexible schema to minimize the RUs. Let me show you how this would work with a practical example using our customer record retrieval from before. First, if we look at the JSON document here, you’ll see that we have the customer address and password information alongside other customer details, and in a single record. If we compare this to how you would usually structure this information in a typical relational database model using multiple tables or databases, you’d probably have one for the customer by email address, password by customer ID, and address by customer ID.
– That sounds like it’d be a pretty typical or common schema and how you might build out table structures, maybe in a SQL instance, for example.
– That’s right, but to query each of these items and then assemble everything together, these would all be separate requests, each having their own cost in terms of compute. For example, here I’m going to query customer by email requests and you’ll see, it’s consuming about 2.8 RUs. Next, I’ll query the password for that customer ID, and it’s another 2.8 RUs. Then I’ll query the address for the customer, and that operation is again another 2.8 RUs. So we’re almost at nine RUs, which might not sound like a lot, but it all adds up as operations start to scale up. And if you’ll recall from the previous query, we were able to get all three pieces of information with just 2.8 RUs in a single query, which is a third of the RU consumption versus pulling these individually.
– You also mentioned that in parallel, you need to look at partitioning, especially as your operations really start to grow in scale and across regions. So what can we do there to keep the RU and throughput as low as possible without impacting performance?
– Yeah, partitioning is super important. And in Cosmo DB, partitions are used to distribute both your data and your database operations evenly. To achieve this, we use a partition key, which is a required property in your document for routing data to the right partition. Choosing the best partition key is really important. It should be chosen based on data access patterns. You’ll want to plan for this up front to avoid poor performance and to make sure you’re keeping costs low. You can think of physical partitions like buckets where portions of your data sit. These use a partition key, which works like a placement hint to determine where to write new data and where to read data when you query it. The right partition key distributes both operations and the data evenly across all partitions. Now let me show you an example. So what I’ve set up here is two containers for our customer data. All their profile and transaction data will be stored in these containers. Both containers are configured for 1500 RU per second provisioned throughput. And this throughput is evenly distributed across all partitions in the container. And I’ve set up a client application to simulate this workload. It’s now generating 30 sales order documents a second, and inserting these into both of the containers. Let’s have a look at some of the metrics that are available for these containers. Here, I’ve set up a workbook which allows me to compare the metrics for both of these containers side by side. Both containers are getting about the same number requests over time. And both containers have high utilization. If you look at the container on the right, you’ll see that it’s being throttled. This happens when RU utilization exceeds 100% in any one second. In those cases, the operations get retried the next second, which also adds to the number of total requests as you’ll see in our total request count. That said, the container on the left is now running fine, even though it’s running the same operations with the same provisioned throughput.
– So how do you then identify the cause of throttling that happened in the bad container?
– Yeah, that’s a great question. We can investigate this by drilling into the throughput metrics. You’ll see the total request units consumed over time appear very similar. However, when we scroll down a little to look at how these requests and associated request units are being distributed across the partitions, we’ll see some very distinct differences. We have 10 partitions with 1500 RUs per second provisioned. So each partition will have an equal 150 RU per second. In our good container on the left, we’re using all of the partitions of the container to service our workload, and in our bad container on the right we’re only using one. And by looking at the normalized RU consumption graph below, we can see this more clearly. So let’s find out what’s behind that. I’ll go back and look at those two containers in more detail, starting with the good container. In the items view, we can see that the partition key that we’ve chosen for our good container is customer ID in this case. Assuming that sales orders are coming from a large number of different customers, they will be distributed across a large number of partitions. So now let’s go to the same thing, but for the bad container. We can see its partition key is order date. And if we look at the property values for order date, we can see it’s the date the transaction occurred. And this means every transaction that occurs on the same day will land in the same single partition, which means only one of the 10 partitions is serving requests, which is bad because 90% of the available throughput is being wasted.
– So that really proves just how important it is to plan your partition strategy upfront, based on your data access patterns.
– Exactly. If you do that work upfront and you’re using Cosmos DB, this is a game changer for running your applications efficiently. And when you combine this with autoscale, it gets even better. So let’s take our same example, except now simulating around seven times the number of transactions, or 200 per second, during the peak times. Even our well partitioned container is throttled here because it doesn’t have sufficient provisioned throughput. It needs 15,000 RUs per second in this case. Now, I could go and increase the manual provisioned throughput to that level to cope with the peaks. But if I did that, it would be billed the same even for non-peak hours as well. And unless I manually adjust the scale every hour, I’d be stuck paying for unused capacity. And that’s where autoscale comes in. The way autoscale works is that for each hour, the scale is automatically set to the peak throughput value for that hour. And here you can see that each hourly peak matches the provisioned throughput. So let’s autoscale the provisioned throughput. I just need to hit this radio button here and save. And now if we go back to our Insights blade, change the time range, and then select a database and container, you’ll see that we are no longer throttled. And our normalized RU consumption is only part of what has been provisioned. This is good, because we will only be billed for the maximum throughput we consume, or a 10% minimum of the configured max RU per second value. Also autoscale throughput is available instantaneously without interruptions to your app.
– And as you showed, autoscaling is a great way to adjust request units once you’ve been able to observe utilization patterns, and it can also help you out if you’re just starting out from scratch and trying to figure out your workload needs. So for anyone who’s watching, who wants to try out Cosmos DB, what do you recommend they do?
– We have an entire set of training that anyone can access for free on Microsoft Learn at aka.ms/learncosmosdb, and you can set up a free trial at aka.ms/trycosmosdb.
– Thanks so much for joining us today, Estefani. And of course, keep watching Microsoft Mechanics for the latest in tech updates. Subscribe to our channel if you haven’t already, and thank you for watching.



Recent Comments