This article is contributed. See the original author and article here.
The Max Degree of Parallelism, or MAXDOP, is one of the most known settings in the SQL Database Engine. There are guidelines of how to configure it that have intricate dependencies on the type of hardware resources you’re running on, and there are several occasions where someone might need to veer of those guidelines for more specialized workloads.
There are plenty of blogs on these topics, and the official documentation does a good job of explaining these (in my opinion). If you want to know more about the guidelines and ways to override for specific queries, refer to the Recommendations section in the Configure the max degree of parallelism Server Configuration Option documentation page.
But what does MAXDOP control? A common understanding is that it controls the number of CPUs that can be used by a query – previous revisions of the documentation used this abstraction. And while that is a correct abstraction, it’s not exactly accurate. What MAXDOP really controls are the number of tasks that can be used in each branch of a query plan.
For most use cases, talking about the number of CPUs used in a query, or the number of concurrent tasks scheduled won’t have a practical difference. But sometimes it’s relevant to know the full story, to go beyond the generalization, especially when troubleshooting those ginormous complex plans that involve dozens of operators – you know who you are :smiling_face_with_smiling_eyes:
Defining a few terms
So before we dive deeper into it, let’s make sure we’re all on the same page regarding a few important terms that will be used in this post, and you find in documentation. These my simplified definitions:
- A request is a logical representation of a query or batch an application sends to the Database Engine. Requests can be monitored through the sys.dm_exec_requests DMV, can be executed in parallel (multiple CPUs) or in a serial fashion (single CPU), have a state that reflects the state of underlying tasks, and accumulate waits when resources needed are not available like a page latch or row lock.
- A task is a single unit of work that needs to be carried out for the request to be completed. A serial request will only have one active task, whereas a parallel request will have multiple tasks executing concurrently. Tasks can be monitored through the sys.dm_os_tasks and sys.dm_os_waiting_tasks DMVs, also have a state (running, runnable, or suspended) that reflects up to the owner request state.
- A worker thread, a.k.a worker, a.k.a thread is the equivalent of a CPU thread (see Wikipedia). I’ll use these terms interchangeably. Tasks that need to be executed are assigned to a worker, which in turn is scheduled to run on the CPU. Workers can be monitored through the sys.dm_os_workers DMV.
- A scheduler is the logical equivalent of a CPU. Workers are scheduled to actively carry out the task assigned to them, and in SQL Server most scheduling is cooperative, meaning a worker won’t cling to the CPU, but instead yield its active time (called the quantum, in 4ms chunks) to another worker waiting to execute its own task. Schedulers can be monitored through the sys.dm_os_schedulers DMV.
- DOP (Degree of Parallelism) designates the actual number of schedulers assigned to a given request (more accurately, the set of tasks belonging to a request).
- The MAXDOP server or database configuration, as well as the MAXDOP query hint, determine the DOP ceiling, the maximum number of schedulers that can be used during a request lifetime. It doesn’t mean they’ll all be used. For example, in a very busy server, parallel queries may execute with a DOP that’s lower than the MAXDOP, if that number of schedulers is simply not available. Hence the term “available DOP”.
- A parallel query plan branch. If you think of a query plan as a tree, a branch is an area of the plan that groups one or more operators between Parallelism operators (a.k.a Exchange Iterators). You can see more about the Parallelism operator and other physical operators in the Showplan Logical and Physical Operators Reference.
Bringing it together
Let’s get on with the example. My SQL Server is configured with MAXDOP 8, CPU Affinity set for 24 CPUs across two NUMA nodes. CPUs 0 through 11 belong to NUMA node 0, CPUs 12 through 23 belong to NUMA node 1. I’ll be using the AdventureWorks2016_EXT database, and have enlarged the tables in the query 50 fold, to have the time to run all the DMV queries before the following query was done:
SELECT h.SalesOrderID, h.OrderDate, h.DueDate, h.ShipDate
FROM Sales.SalesOrderHeaderBulk AS h
INNER JOIN Sales.SalesOrderDetailBulk AS d ON h.SalesOrderID = d.SalesOrderID
WHERE (h.OrderDate >= '2014-3-28 00:00:00');
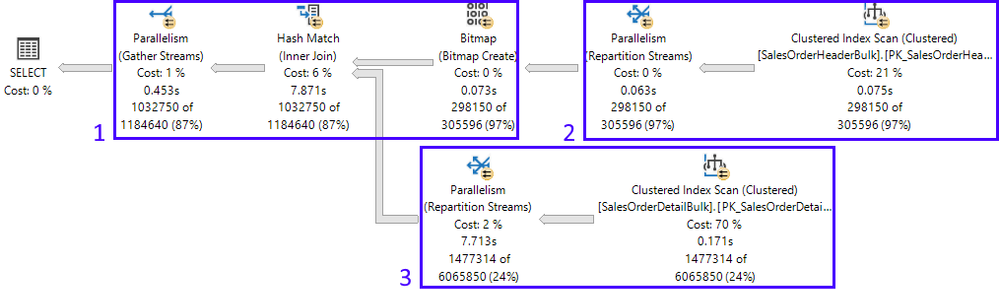
Here is the resulting actual execution plan, divided into its 3 branches:

In this example, looking at the plan properties, we can see more information about how many threads SQL Server will reserve to execute this plan, along with the worker’s placement on the NUMA nodes:

The Database Engine uses information about the plan shape (which allows for 2 concurrent branches in this example – more on this further ahead) and MAXDOP configuration (which is 8), to figure out how many threads to reserve. 2 x 8 = 16.
The threads can be reserved across all NUMA nodes, or be reserved in just one NUMA node, and this is entirely dependent on scheduler load at the moment the reservation is made at runtime. In this case, the reservation was split between both NUMA nodes. But a few minutes later, when I executed the query again, thread reservations were all on NUMA node 1, as seen below from the actual execution plan:

Back to the 1st execution: if there are 3 branches in the execution plan, why can only 2 branches execute concurrently? That’s because of the type of join in this case, and the Query Processor knows this. A hash join requires that its build input be available before starting to generate the join output. Therefore, branches 2 (build input) and 3 (probe input) can be executed concurrently (for more details on hash joins, refer to the documentation on Joins). Once the build input is complete, then branch 1 can start. Only at that point, can branches 3 and 1 be executed concurrently.
The live execution plan gives us a view of this with branches 3 and 1 in flight, and 2 completed:

Ok, so how about tasks? Didn’t I say MAXDOP limits how many tasks are spawned for each branch? Let’s query the sys.dm_os_tasks DMV and find out what’s happening:
SELECT parent_task_address, task_address, task_state, scheduler_id, worker_address
FROM sys.dm_os_tasks
WHERE session_id = 100 -- my session ID
ORDER BY parent_task_address, scheduler_id;
With the following result:

Notice there are 17 active tasks: 16 child tasks corresponding to the reserved threads (8 for each concurrent branch), and the coordinating task. The latter can be recognized because the column parent_task_address is always NULL for the coordinating task.
Each of the 16 child tasks has a different worker assigned to it (worker_address column), but notice that all 16 workers are assigned to the same pool of 8 schedulers (5,8,10,11,12,18,20,22) – the MAXDOP limit. The fact they’re on the same schedulers is by-design: once the first set of 8 parallel tasks on a branch was scheduled, every additional task for any branch will use that same schedulers.
The coordinating task can be scheduled on any NUMA node, even on a node where no threads were reserved. In this case it was on scheduler 3, which is in NUMA node 0.
Summary
So, we’ve seen how a single request can spawn multiple tasks up to the limit set by reserved worker threads – 16 in this case. The threads reserved per branch are limited by MAXDOP – 8 in our example. Because each task must be assigned to a worker thread for execution, the number of tasks that can be running concurrently is therefore limited by MAXDOP. In other words, the MAXDOP limit is enforced at the task level, per branch, not at the query level.
If you want to know more, refer to the SQL Server task scheduling section in the Thread and Task Architecture Guide.
Pedro Lopes ( @SQLPedro ) – Principal Program Manager
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments