by Contributed | Oct 3, 2021 | Technology
This article is contributed. See the original author and article here.
You can now assign incidents and alerts to someone else in your organization
To control and manage incidents and alerts in the organization, sometimes you would need to assign them to a specific analyst. Now you can do that right from the incident queue in Microsoft 365 Defender.
How does it work?
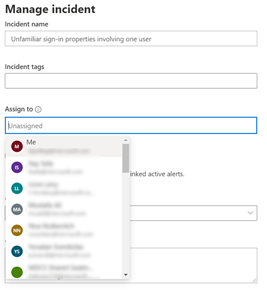
From the incident or alert side pane in the incident queue or the incident page, select Manage incident/alert and choose the user account you want to assign.
By default, the first value in the “assign to” drop menu will be yourself (“Me” at the title).
Note that you can choose all users from the organization, but only users with access to the Microsoft 365 Defender portal will be able to view the incident or alert. So, to help you assign the most relevant people in the organization, the rest of the default suggestions you will get are the latest assignees you chose.

Once the user is assigned, he can filter to see only incidents that are assigned to himself. A SOC manager that dispatches the incident queue can also filter for all unassign incidents or alerts to choose the relevant incident he would like to assign.
by Contributed | Oct 1, 2021 | Technology
This article is contributed. See the original author and article here.
Continuing on the topic of High Availability and Failover Groups from the previous posts on How-to determine the SQL MI Failover Group configuration & How-to determine the SQL MI Failover Group & HA Replicas Details, in this how-to we shall see how to monitor the high availability of the available replicas as well as the Failover Group connection between Azure SQL Managed Instances.
If you are interested in other posts on how-to discover different aspects of SQL MI – please visit the http://aka.ms/sqlmi-howto, which serves as a placeholder for the series.
First of all the easiest way of monitor the current status of the databases is to use the sys.dm_hadr_database_replica_states DMV by looking at the [syncrhonization_health], [database_state] and [is_suspended] columns representing the information about different aspects of health for each of the databases on each of the visible replicas – either local or remote, as in the case of the Failover Group.
Additionally an important part of monitoring is an action of looking at the replay lag that is taking place on the secondary replicas and for that purpose the column [secondary_lag_seconds] exists, representing the lag time in seconds.
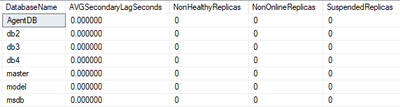
The final result for the first query is rather simple – representing an average lag on the secondary replicas (which value and especially value growth we should observe with care), and a count of non-healthy and suspended replicas:
SELECT DB_NAME(database_id) as DatabaseName,
AVG(secondary_lag_seconds*1.0) as AVGSecondaryLagSeconds,
SUM( CASE WHEN synchronization_health <> 2 THEN 1 ELSE 0 END ) as NonHealthyReplicas,
SUM( CASE WHEN database_state <> 0 THEN 1 ELSE 0 END ) as NonOnlineReplicas,
SUM( CASE WHEN is_suspended <> 0 THEN 1 ELSE 0 END ) as SuspendedReplicas
FROM sys.dm_hadr_database_replica_states
GROUP BY database_id
ORDER BY DB_NAME(database_id);
The expected result for the healthy replica situation (no matter if there are multiple active replicas or if a failover group is involved or not) is presented below, where there is no Lag for replicating information and there is no replica with any potential problem:
Catching a an unhealthy situation will look similarly to the picture below, where I have provoked the resizing of the Primary Replica and the db4 database was not considered healthy on one of the replicas:

Knowing which database(s) is having problems, as the next step, you might need to determine which replica(s) are affected and for that purpose you can use the following query, which will help you understand the exact nodes and the respective problem it is facing:
SELECT CASE WHEN fabric_replica_role_desc IS NOT NULL THEN fabric_replica_role_desc ELSE link_type END as ReplicaRole,
CASE WHEN replication_endpoint_url IS NOT NULL THEN replication_endpoint_url ELSE partner_server END as EndpointURL,
synchronization_state_desc, is_commit_participant, synchronization_health_desc,
is_suspended, suspend_reason_desc,
DB_NAME(repl_states.database_id) as DatabaseName,
repl_states.database_state_desc,
seedStats.internal_state_desc as SeedingStateDesc
FROM sys.dm_hadr_database_replica_states repl_states
LEFT JOIN sys.dm_hadr_fabric_replica_states frs
ON repl_states.replica_id = frs.replica_id
LEFT OUTER JOIN sys.dm_hadr_physical_seeding_stats seedStats
ON seedStats.remote_machine_name = replication_endpoint_url
AND (seedStats.local_database_name = repl_states.group_id OR seedStats.local_database_name = DB_NAME(database_id))
LEFT OUTER JOIN sys.dm_hadr_fabric_continuous_copy_status fccs
ON repl_states.group_database_id = fccs.copy_guid
ORDER BY ReplicaRole DESC, DatabaseName
This query will help you to determine for each of your databases if there are any unhealthy replicas (meaning that something wrong is going and quite possible the synchronization process is not working) or maybe some of the replicas are not online (maybe there was a problem with one of the secondary replicas or a on Business Critical service tier, for example) and if any of the replicas is suspended.
Also it will help you to determine eventual synchronization problems if the replica is an active secondary, but the [synchronization_state_desc] is SYNCHRONIZING instead of SYNCHRONIZED as expected, or the active seeding is taking place.
A healthy situation of the same initial configuration is presented on the picture below:

Ordered by the Replica Role (Primary, Secondary and Failover Group respectively) and the database name, you can see determine precisely which replica is having a problem.
A non-problematic situation, where actually the scaling operation is running (SLO update) is represented below – while there is a seeding for the new replica is taking place, there are 2 types of the replicas – LAG_REPLICA_LINK_CONTINUOS_COPY and LAG_REPLICA_LINK_TYPE_UPDATE_SLO, with the new one is showing being not yet completely healthy while being built and seeded:
On the image below you have a partial screenshot of this situation.

For troubleshooting more details on the replication between replicas, the following query which provides the habitual details on replication timestamps for commit, hardened and redone operations as well as the log send and redo queue sizes, can be used:
SELECT CASE WHEN fabric_replica_role_desc IS NOT NULL THEN fabric_replica_role_desc ELSE link_type END as ReplicaRole,
CASE WHEN replication_endpoint_url IS NOT NULL THEN replication_endpoint_url ELSE partner_server END as EndpointURL,
DB_NAME(repl_states.database_id) as DatabaseName,
synchronization_state_desc,
synchronization_health_desc,
CASE WHEN secondary_lag_seconds IS NOT NULL THEN secondary_lag_seconds ELSE replication_lag_sec END as lag_in_seconds,
last_commit_time,
last_hardened_time, last_redone_time, DATEDIFF( MS, last_commit_time, last_redone_time) / 1024. as LastRedoDelaySec,
log_send_queue_size, redo_queue_size
FROM sys.dm_hadr_database_replica_states repl_states
LEFT JOIN sys.dm_hadr_fabric_replica_states frs
ON repl_states.replica_id = frs.replica_id
LEFT OUTER JOIN sys.dm_hadr_fabric_continuous_copy_status fccs
ON repl_states.group_database_id = fccs.copy_guid
ORDER BY DatabaseName, ReplicaRole DESC;
The good, healthy result is presented on the picture below, with ordering by the name of the database and the respective Replica role:

Note that these are the queries that can be expanded with more information and details and for better commodity can be enhanced with filters for showing just the databases and/or replicas that having problems, as for example adding the following filter condition to the second query will show only the databases which synchronization health is not HEALTHY or the databases which are not ONLINE or the databases where are asynchronous while they should be synchronous or the databases which are suspended:
WHERE ( ( synchronization_health <> 2 )
OR
( database_state <> 0 )
OR
( synchronization_state <> 2 AND is_commit_participant = 1 )
OR
(is_suspended = 1) )
This post ends the this little sub-series of the 3 posts with a focus on the High Availability and Failover Groups configuration and troubleshooting on the SQL Managed Instance, but certainly, in the future, we shall be adding more how-tos to this topic.
by Scott Muniz | Oct 1, 2021 | Security, Technology
This article is contributed. See the original author and article here.
Google has released Chrome version 94.0.4606.71 for Windows, Mac, and Linux. This version addresses vulnerabilities that an attacker could exploit to take control of an affected system.
CISA encourages users and administrators to review the Chrome Release Note and apply the necessary update as soon as possible.
![[Guest Blog] Living in an autism bubble in an ever-changing world.](https://www.drware.com/wp-content/uploads/2021/09/fb_image-91.png)
by Contributed | Sep 30, 2021 | Technology
This article is contributed. See the original author and article here.
This post was written by Office Apps & Services MVP Peter Rising as a part of our Humans of IT Guest blogger series. This is a follow up from Peter’s first post in November 2020 about the challenges of working from home during Covid-19 times whilst raising a son with severe autism. Almost one year on, life remains extremely challenging, but in different ways.
In early 2020, the world changed as the global pandemic disrupted all our lives. In the months that followed, many of us adjusted to working from home, and supporting our children with home learning. This was a massive shock to the system, but what I did not realise at the time was that this would be the easy part for me and my family.
As a quick recap, I live in the UK with my wife Louise, and our two sons George (14), and Oliver (11). Oliver was diagnosed with severe autism at the age of two and a half, and as he has grown older we have seen sensory processing disorder, extreme anxiety and pathological demand avoidance added to the list of challenges he faces on a daily basis.
Oliver and me
Before the pandemic devastated the world, Oliver attended a Specialist Educational Needs (SEN) school, and was picked up and returned home each day by the school bus. I don’t believe he ever really enjoyed attending school though, as even back then we had some difficulties in that he refused all food during the school day and would also not visit the school toilets. Looking back at those times, I think that Oliver merely ‘tolerated’ school, but it is clear that having to attend caused him distress.
This became ever more apparent when schools started to re-open again in late 2020 and children started to return. To begin with, we were quite hopeful, as Oliver boarded the school bus on the first day back with no real problems. Things began to change very rapidly though and Oliver started refusing to get on the bus and the more we tried to encourage him, the more distressed he would become.
So we tried driving Oliver to school instead. This looked like it may work until we took him into the school building and he refused to go with the teacher, so we ended up taking him back home with us. Slowly but surely, the mere mention of school made Oliver more anxious. What didn’t help matters was that on the few occasions we succeeded in getting him to attend, the pattern was disrupted when a teacher or classmate inevitably tested positive for Covid-19, resulting in the entire class needing to stay at home and self-isolate for 14 days. Routine and pattern is essential in Oliver’s life, and this unpredictability did not help our cause one bit.
By the time 2020 came to a close, I think Oliver may have attended school for approximately 10 days in total since it reopened before we got to the point that he stopped attending completely. At this time, both the education and social authorities agreed with us that there was little point in persisting with trying to get Oliver to attend school whilst the requirement to self isolate was still in place as it meant that consistency was almost impossible.
As we started the new year of 2021, we became accustomed to Oliver staying at home. This was arguably hardest on our oldest son George who was now the only person leaving the house on a regular basis to attend school. I was still working exclusively from home myself. George, to his credit has shown incredible maturity beyond his 14 years throughout these difficult times – particularly as Oliver staying away from school has led to many other stresses and anxieties in our house.
For many months earlier in the year, we established a pattern of Oliver visiting Louise’s parents who live very close to us. He only went for a short time each day between 3.00pm and 6.00pm but this was extremely helpful to us as it provided us (Louise especially) with some respite. Oliver has become particularly attached to his Mother over the past year – almost to the point of obsession, and he always likes to know where she is.
This extreme attachment to Louise has only been exacerbated by two escalating anxiety triggers which Oliver has developed during this time. The first trigger is barking dogs. There are a lot of dogs living on our street and when they bark (which is frequent), Oliver becomes hugely distressed and will scream. If the barking does not subside quickly, Oliver will run through the house to find Louise and will start hitting her repeatedly. This is utterly horrifying as you can imagine. It contradicts entirely his special bond with Louise, but illustrates that he does not understand how to appropriately process and express his emotions. This behaviour is still a problem as I write this.
The second trigger is bad weather. Oliver seems to sense bad weather before it happens. He will appear in the living room and demand that the curtains are closed and the lights turned on (regardless of the time of day). we then have to play calming music at high volume. This can go on for quite some time, even if the weather has improved. It will only end on Oliver’s terms. Ironically, the bad whether stops the barking dogs issue, but when the sunshine returns, the dogs come out again. It feels like we just can’t catch a break.
To add to the problems, back in July Oliver stopped going to his grandparents. We have no idea why but now we are effectively housebound. Oliver becomes distressed if Louise tries to leave the house for any reason. I am not so restricted but the only time I really go anywhere is to take George to school as I don’t want Louise to be left alone with Oliver for any length of time.
When you write all of this down and read it back, it sounds ridiculous and unbelievable, and you do start to question if you have been good enough parents. Fortunately we did receive some validation recently as child mental health services and a clinical nurse started visiting Oliver every day recently. They were confident that they could challenge Oliver’s rigidity, but they too have found that Oliver is not going to be an easy code to crack. They attempted to get him to attend his new school last week, and on the first day they managed to get him there for a few hours. He clearly did not realise where he was going though, as the following day when they attempted this again he refused their attempts to get him ready and into the car.
Despite all this, we still manage to get things done. I manage to do my work, have teams meetings, record a podcast, and write blogs like this one. Louise manages to enjoy her crafting which includes knitting and crochet, and she has recently rediscovered a passion for water colour painting. These activities are often interrupted of course and things take a lot longer than they normally would as a result. In the extreme, I have had to abandon an important work call to respond to a violent episode from Oliver when a dog barks.
I have to be honest and say that I never imagined that life could be this hard, and I don’t know how on earth we are going to work our way out of this situation. The services that are working with us to support us and trying to de-sensitise Oliver to his anxieties are now regrouping and thinking of new strategies, but it feels like while the rest of the world has started to do normal everyday things again, we have never actually come out of lockdown.
We remain upbeat though throughout it all, and our families always kindly remark how incredible it is that we still have a smile on our faces considering the stressful life we live. That gives me so much strength, especially on the days where I’m running on empty and feel like I have nothing more to give.
I have to keep the faith that there is an answer to this situation, and the support and friendship I receive from this community helps me stay strong more than you can know.
Thanks for reading, I hope I can update you in the not too distant future with some good progress. Keep your fingers crossed for us!!
Take care and stay safe!
Peter

by Contributed | Sep 29, 2021 | Technology
This article is contributed. See the original author and article here.
If you’re a Java developer and Kubernetes is on your plate to learn and to deploy in the cloud, this is the event you don’t want to miss. There’s a rich line-up of stellar Java and Kubernetes speakers across two tracks whose only goal is to share their wisdom and experience with others. It’s free and it’s fabulous, so why not register today?
If that’s not enough, here are the top three reasons why you should join as an attendee now, and possibly as a speaker in the future:
- Sharpen your cloud-development skills – you want to know how to build resilient and resource-efficient software in any cloud environment.
- Network with the experts – gain valuable industry insights and vital job skills from the J4K community experts.
- Check out the cool tech – it’s not just buzzwords, they’re real and they’ll make your life easier. Learn about Quarkus, Spring Boot, App Service, cloud-native Java, MicroProfile, Jakarta EE, GitOps and all things Kubernetes.
J4K is a developer oriented conference focused on open-source and hybrid cloud application development of Java and Kubernetes. This is a free community event, delivered by Java and Kubernetes community leaders and influencers. J4K is dedicated to enrich developers and architects with cloud focused solutions.
The three basic building blocks of this conference are:
- Learn – about the latest Java innovations on Kubernetes
- Build – get hands-on experience with workshops and labs
- Exchange ideas – network and contribute to open source projects that optimizes Java apps on Kubernetes
Don’t let conference fatigue have you miss out on a day of learning. Attend sessions that matter to you or stay for the whole show, it’s up to you. Or get up to speed with how Microsoft supports Java. Check out Microsoft’s keynote and sessions:
J4K is a free event for our communities to learn about Java on Kubernetes, network with community leaders and developers, collaborate on open-source projects and gain insight in industry innovations. There’s also live music by Nirvanna, a tribute band to the famous grunge band Nirvana, and awesome entertainment between sessions. Join us on October 6th by registering now and fill your noggins with all sorts of Java and Kubernetes goodness. See you soon!

Recent Comments