by Contributed | May 25, 2023 | Technology
This article is contributed. See the original author and article here.
Today, we faced a service request where our customer got the following issue Msg 9002, Level 17, State 2, Line 8
The transaction log for database ‘2d7c3f5a-XXXX-XZY-ZZZ-XXX’ is full due to ‘REPLICATION’ and the holdup lsn is (194XXX:24X:1). Following I would like to share with you what was the lesson learned here.
We need to pay attention about the phrase “is full due to”, in this case is REPLICATION that means that could be related about Transaction Replication or Change Data Capture (CDC).
In order to determine the situation, if we are not using Transaction Replication is to review if CDC is enabled running the following query: select name,recovery_model,log_reuse_wait,log_reuse_wait_desc,is_cdc_enabled,* from sys.databases where database_id=db_id() – sys.databases (Transact-SQL) – SQL Server | Microsoft Learn
If the value of the column is_cdc_enabled is 1 and you are not using CDC, use the command sys.sp_cdc_disable_db to disable the CDC job. sys.sp_cdc_disable_db (Transact-SQL) – SQL Server | Microsoft Learn
During the troubleshooting process during the execution of sys.sp_cdc_disable_db we got another error Msg 22831, Level 16, State 1, Procedure sys.sp_cdc_disable_db_internal, Line 338 [Batch Start Line 6]
Could not update the metadata that indicates database XYZ is not enabled for Change Data Capture. The failure occurred when executing the command ‘(null)’. The error returned was 9002: ‘The transaction log for database ‘xxx-XXX-43bffef44d0c’ is full due to ‘REPLICATION’ and the holdup lsn is (51XYZ:219:1).’. Use the action and error to determine the cause of the failure and resubmit the request.
In this situation, we need to add more space to the transaction log file due there is not possible to register the disabling CDC operation in the transaction log.
Once, we have more space in our transaction log, we were able to disable CDC and after disabling CDC, Azure SQL Database was able to marked as backup the Transaction Log.
Finally, in order to try to speed up the truncation of this transaction log we executed several times the command DBCC SHRINKFILE (Transact-SQL) – SQL Server | Microsoft Learn and we were able to reduce the file size of the transaction log file.
Also, during the troubleshooting we used the following to see how many VLFs that we have and the space usage: sys.dm_db_log_info (Transact-SQL) – SQL Server | Microsoft Learn and sys.database_recovery_status (Transact-SQL) – SQL Server | Microsoft Learn
SELECT * FROM sys.dm_db_log_info(db_id()) AS l
select * from sys.database_recovery_status where database_id=db_id()
by Contributed | May 24, 2023 | Technology
This article is contributed. See the original author and article here.
This solution architecture proposal outlines how to effectively utilize OpenAI’s language model alongside Azure Cognitive Services to create a user-friendly and inclusive solution for document translation. By leveraging OpenAI’s advanced language capabilities and integrating them with Azure Cognitive Services, we can accommodate diverse language preferences and provide audio translations, thereby meeting accessibility standards and reaching a global audience. This solution aims to enhance accessibility, ensure inclusivity, and gain valuable insights through the combined power of OpenAI, Azure Cognitive Services and PowerPlatform.
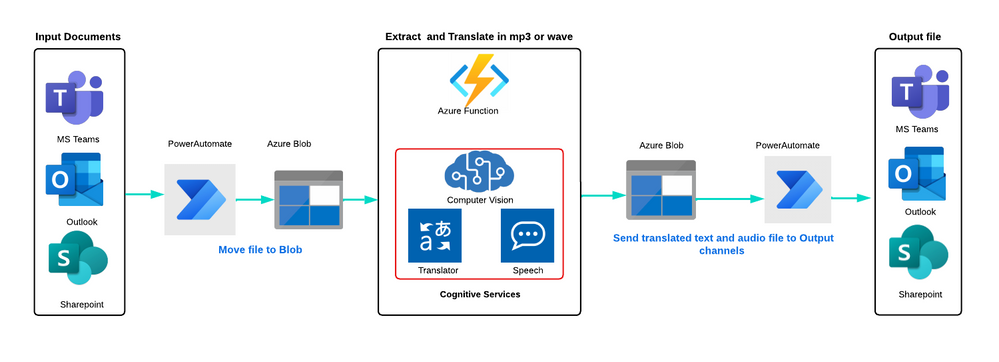
Dataflow
Here is the process:
Ingest: PDF documents, text files, and images can be ingested from multiple sources, such as Azure Blob storage, Outlook, OneDrive, SharePoint, or a 3rd party vendor.
Move: Power Automate triggers and moves the file to Azure Blob storage. Blob triggers then get the original file and call an Azure Function.
Extract Text and Translate: The Azure Function calls Azure Computer Vision Read API to read multiple pages of a PDF document in natural formatting order, extract text from images, and generate the text with lines and spaces, which is then stored in Azure Blob storage. The Azure Translator then translates the file and stores it in a blob container. The Azure Speech generates a WAV or MP3 file from the original language and translated language text file, which is also stored in a blob container
Notify: Power Automate triggers and moves the file to the original source location and notifies users in outlook and MS teams with an output audio file.
Without Open AI
With Open AI
.png")
Alternatives
The Azure architecture utilizes Azure Blob storage as the default option for file storage during the entire process. However, it’s also possible to use alternative storage solutions such as SharePoint, ADLS or third-party storage options. For processing a high volume of documents, consider using Azure Logic Apps as an alternative to Power Automate. Azure Logic Apps can prevent you from exceeding consumption limits within your tenant and is a more cost-effective solution. To learn more about Azure Logic Apps, please refer to the Azure Logic Apps.
Components
These are the key technologies used for this technical content review and research:
Scenario details
This solution uses multiple Cognitive Services from Azure to automate the business process of translating PDF documents and creating audio files in wav/mp3 audio format for accessibility and global audience. It’s a great way to streamline the translation process and make content more accessible to people who may speak different languages or have different accessibility needs.
Potential use cases
By leveraging this cloud-based solution idea that can provide comprehensive translation services on demand, organizations can easily reach out to a wider audience without worrying about language barriers. This can help to break down communication barriers and ensure that services are easily accessible for people of all cultures, languages, locations, and abilities.
In addition, by embracing digital transformation, organizations can improve their efficiency, reduce costs, and enhance the overall customer experience. Digital transformation involves adopting new technologies and processes to streamline operations and provide a more seamless experience for customers.
It is particularly relevant to industries that have a large customer base or client base, such as e-commerce, tourism, hospitality, healthcare, and government services.
by Contributed | May 23, 2023 | Technology
This article is contributed. See the original author and article here.
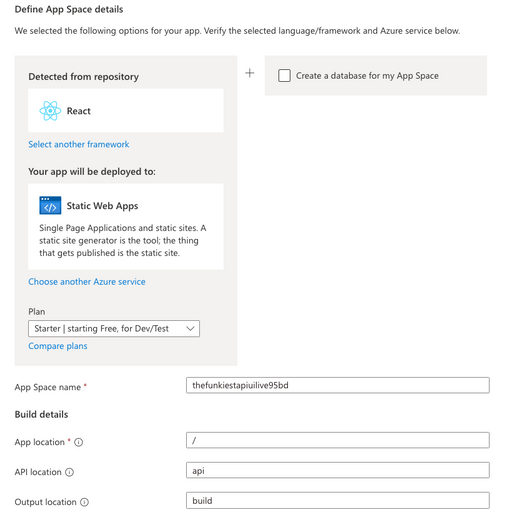
We are excited to announce Azure App Spaces (preview), one of the fastest and easiest way to deploy and manage your web apps on Azure. Azure App Spaces is a portal-based experience that takes an app-first approach to building, deploying, and running your apps. App Spaces makes it easier for developers to get started using Azure, without needing to be an expert on the hundreds of different cloud services.
Detect the right Azure services from your repository
App Spaces lets you connect your GitHub repositories to Azure, and through analysis of the code inside your GitHub repository, suggests the correct Azure services you should use. Once you deploy, GitHub Actions is used to create a continuous deployment pipeline between your repositories and your newly provisioned cloud services. Once you’ve deployed your app via App Spaces, changes to your code will immediately be pushed to your connected Azure services.
Bring your own repository or start from a template

App Spaces also provides sample templates, powered by Azure Developer CLI, that provide a helpful blueprint for getting started with Azure. You can use these templates to immediately create a GitHub repository, connect it to Azure, and provision a distinct set of services for the template scenario. Our templates include sample static websites, web apps, and APIs, in a variety of different languages.
Manage your app in a consolidated view

In addition to making it easier and faster to get started developing, App Spaces also provides a simplified, app-centric management experience. An “App Space” is a loose collection of cloud services that, collectively, comprise the app you are building. You can manage your compute, database, caching, and other key services all within the same, easy-to-use management experience.
To get started immediately, you can check out App Spaces here. You can also read our documentation to get a better look at what App Spaces can do for you.

by Contributed | May 23, 2023 | AI, Business, copilot, Microsoft 365, Technology
This article is contributed. See the original author and article here.
Generative AI models are ushering in the next frontier in interactions between humans and computers. Just like graphical user interfaces brought computing within reach of hundreds of millions of people three decades ago, next-generation AI will take it even further, making technology more accessible through the most universal interface—natural language.
The post Empowering every developer with plugins for Microsoft 365 Copilot appeared first on Microsoft 365 Blog.
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.
by Contributed | May 22, 2023 | Technology
This article is contributed. See the original author and article here.
First, big kudos to Martin for crafting this amazing playbook and co-authoring this blogpost.
Be sure to check out his SAP-focused blog for more In-Depth Insights!
The purpose of this blog post is to demonstrate how the SOAR capabilities of Sentinel can be utilized in conjunction with SAP by leveraging Microsoft Sentinel Playbooks/Azure Logic Apps to automate remedial actions in SAP systems or SAP Business Technology Platform (BTP).
Before we dive into the details of the SOAR capabilities in the Sentinel SAP Solution, let’s take a step back and take a very quick run through of the Sentinel SAP Solution.
The Microsoft Sentinel SAP solution empowers organizations to secure their SAP environments by providing threat monitoring capabilities. By seamlessly collecting and correlating both business and application logs from SAP systems, this solution enables proactive detection and response to potential threats. At its core, the solution features a specialized SAP data-connector that efficiently handles data ingestion, ensuring a smooth flow of information. In addition, an extensive selection of content, comprising analytic rules, watchlists, parsers, and workbooks, empowers security teams with the essential resources to assess and address potential risks.
In a nutshell: With the Microsoft Sentinel SAP solution, organizations can confidently fortify their SAP systems, proactively safeguarding critical assets and maintaining a vigilant security posture.
For a complete (and detailed) overview of what is included in the Sentinel SAP solution content, see Microsoft Docs for Microsoft Sentinel SAP solution
Now back to the SOAR capabilities! About a year ago, we published a blog post titled “How to use Microsoft Sentinel’s SOAR capabilities with SAP“, which discussed utilizing playbooks to react to threats in your SAP systems.
The breakthrough which the blogpost talked about was the use of Sentinel’s SOAR (Security Orchestration and Automated Response) capabilities on top of the Sentinel SAP Solution.
This means that we can not only monitor and analyze security events in real-time, we can also automate SAP incident response workflows to improve the efficiency and effectiveness of security operations.
In the previous blog post, we discussed blocking suspicious users using a gateway component, SAP RFC interface, and GitHub hosted sources.
In this post, we showcase the same end-to-end scenario using a playbook that is part of the OOB content of the SAP Sentinel Solution.
And rest assured, no development is needed – it’s all about configuration! This approach significantly reduces the integration effort, making it a smooth and efficient process!
Overview & Use case
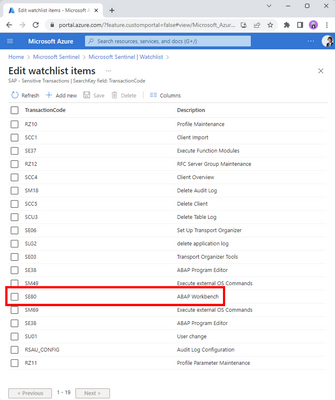
Let me set the scene: you’re the defender of your company’s precious SAP systems, tasked with keeping them safe. Suddenly Sentinel warns you that someone is behaving suspiciously on one of the SAP systems. A user is trying to execute a highly sensitive transaction in your system. Thanks to your customization of the OOB “Sensitive Transactions” watchlist and enablement of the OOB rule “SAP – Execution of a Sensitive Transaction Code”, you’re in the loop whenever the sensitive transaction SE80 is being executed. You get an instant warning, and now it’s time to investigate the suspicious behavior.
Sensitive Transactions watchlist with an entry for SE80
As part of the security signal triage process, it might be decided to take action against this problematic user and to (temporarily) kick-out them out from ERP, SAP Business Technology Platform or even Azure AD. To accomplish this, you can use the automatic remediation steps outlined in the OOB playbook “SAP Incident handler- Block User from Teams or Email”.
 Screenshot for the OOB SAP playbook
Screenshot for the OOB SAP playbook
By leveraging an automation rule and the out-of-the-box playbook, you can effectively respond to potential threats and ensure the safety and security of your systems. Specifically, in this blog post, we will use the playbook to promptly react to the execution of the sensitive transaction SE80, employing automation to mitigate any risks that may arise.
Now, it’s time to dive deeper into this OOB playbook! Let’s examine it closely to better understand how it works and how it can be used in your environment.
Deep dive into the playbook
To start off, we’ll break down the scenario into a step-by-step flow.
 Overview of the SAP user block scenario
Overview of the SAP user block scenario
The core of this playbook revolves around adaptive cards in Teams (see step 5 in the overview diagram), and relies on waiting for a response from engineers. As we covered earlier, Sentinel detects a suspicious transaction being executed (steps 1-4), and an automation rule is set up as a response to the “SAP – Execution of a Sensitive Transaction Code” analytic rule. This sets everything in motion, and the adaptive cards in Teams play a crucial role in facilitating communication between the system and the engineers.
 Adaptive card for a SAP incident offering to block the suspicious user
Adaptive card for a SAP incident offering to block the suspicious user
As demonstrated in the figure above (which correspond to step 5 in the step-by-step flow), engineers are presented with the option to block the suspicious user (Nestor in this case!) on SAP ERP, SAP BTP or on Azure AD.
Let’s dive into this part of the playbook design to see how it works behind the scenes.:
 Screenshot for block user action in the playbook
Screenshot for block user action in the playbook
In the screenshot you’ll notice three distinct paths for the “block user” action, each influenced by the response received in Teams. Of particular interest in this blog is the scenario where blocking a user on SAP ERP is required. This task is achieved through SOAP, providing an efficient means to programmatically lock a backend user using RFC (specifically BAPI_USER_LOCK).
When it comes to sending SOAP requests to SAP, there are various options available. Martin’s blog post provides a comprehensive explanation of these options, offering detailed technical insights and considerations. To avoid duplicating information, I encourage you to head over there for valuable insights on sending the SOAP requests.
When reacting to the adaptive cards, we recommend providing a clear and meaningful comment when blocking a user. This comment will be shared back to Sentinel for auditing and helping security operations understand your decision. The same applies when flagging false positives, as it helps Sentinel learn and differentiate between real threats and harmless incidents in the future.
 Screenshot of updated close reason on Sentinel fed with comment from Teams
Screenshot of updated close reason on Sentinel fed with comment from Teams
And there you have it, a lightning-fast rundown of how (parts of) this amazing playbook works!
Final words
And that’s a wrap for this blog post!
But hold on, don’t leave just yet, we’ve got some important closing statements for you:
- Remember that you have the flexibility to customize this playbook to fit your specific needs. Feel free to delete, add, or modify steps as necessary. We encourage you to try it out on your own and see how it works in your environment!
- For those who want to dive even deeper into the technical details (especially regarding SAP), be sure to check out Martin’s blog post. As the expert who designed this playbook, he provides an in-depth explanation of how to configure SAP SOAP interfaces, the authorizations for the target Web Service and RFC and much more! Trust me, it’s a fascinating read and you’re sure to learn a lot!
- On a related note, Martin has also created another playbook that automatically re-enables the audit trail to prevent accidental turn-offs. This playbook is now accessible through the content hub as well.
- And finally, for those who made it all the way to the end, we hope you enjoyed reading this blog post as much as we enjoyed writing it. Now go forth and automate your security like a boss!

Recent Comments