This article is contributed. See the original author and article here.
Introduction
When migrating from Oracle to SQL Server, Azure SQL Database or Azure SQL Managed Instance, an application using the Microsoft JDBC Driver for SQL Server is often used to avoid re-writing the application. However, after migration it’s often discovered that performance is not the same as it was when the data was on Oracle. Optimizations are necessary for query tuning due to the distinct behaviors of the two database engines.
An unnoticed yet significant issue arises from implicit conversions due to JDBC driver settings, leading to performance degradation. This blog seeks to highlight this easily overlooked problem, offering solutions to ensure optimal performance with SQL backend while preserving the JDBC application.
How to Detect Implicit Conversion
Obtain execution plans for your most CPU-intensive queries by enabling the query store. Be aware that implicit conversions might be happening in smaller queries with high execution counts, even if they don’t individually consume significant resources. An easy way to identify the type conversion is given in this blog.
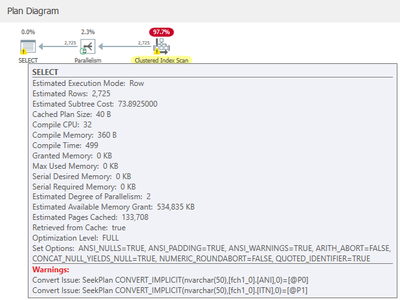
Looking at the execution plan you would see something like this:
While if you look at the statement text, you will see that the JDBC Driver presents the statement like this, which looks innocuous:
(@P0 nvarchar(4000),@P1 nvarchar(4000))select col1, col2 from table1 where col1 = @P0 ….
Nevertheless, implicit conversion will result in queries consuming more CPU resources than anticipated, hindering the scalability of your application. Implicit conversion occurs when the data types of SQL Server columns differ from those presented by the parameter data types of the JDBC driver. Typically, SQL columns are configured with varchar(x) to conserve space compared to Nvarchar(x), while the JDBC driver defaults to transmitting strings as Unicode.
Preventing Implicit Conversion with JDBC Driver
You have two options to choose from based on ease of implementation:
- Change the underlying SQL Server column types to align with the parameter datatype. However, this may not be ideal as Nvarchar occupies more space, and altering SQL column types entails significant design changes.
- For applications utilizing JDBC, utilize a driver connection property known as “sendStringParametersAsUnicode.” This setting determines whether strings are sent to SQL as Unicode parameters or not. It’s the recommended option. If your SQL column datatypes involved in implicit conversion are varchar, set the value to false.
Once this is implemented, check the query plan again. If the value of the “sendStringParametersAsUnicode” setting is false, the parameters presented by the driver will show up as follows:
(@P0 varchar(4000),@P1 varchar(4000))select col1, col2 from table1 where col1 = @P0 ….
As the underlying SQL column types are also varchar, there is no implicit conversion, leading to improved performance and reduced CPU usage!
You can find a list of all the JDBC driver settings here.
Feedback and suggestions
If you have feedback or suggestions for improving this data migration asset, please send an email to Databases SQL Engineering Team.
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments