This article is contributed. See the original author and article here.
This post is co-authored with Xianghao Tang, Lihui Wang, Jun-Wei Gan, Gang Wang, Garfield He, Xu Tan and Sheng Zhao
Neural Text-to-Speech (Neural TTS), part of Speech in Azure Cognitive Services, enables you to convert text to lifelike speech for more natural user interactions. Neural TTS has powered a wide range of scenarios, from audio content creation to natural-sounding voice assistants, for customers from all over the world. For example, the BBC, Progressive and Motorola Solutions are using Azure Neural TTS to develop conversational interfaces for their voice assistants in English speaking locales. Swisscom and Poste Italiane are adopting neural voices in French, German and Italian to interact with their customers in the European market. Hongdandan, a non-profit organization, is using neural voices in Chinese to make their online books audible for the blind people in China.
By September 2020, we extended Neural TTS to support 49 languages/locales with 68 voices. At the same time, we continue to receive customer requests for more voice choices and more language support globally.
Today, we are excited to announce that Azure Neural TTS has extended its global support to five new languages: Maltese, Lithuanian, Estonian, Irish and Latvian, in public preview. At the same time, Neural TTS Container is generally available for customers who want to deploy neural voice models on-prem for specific security requirements.
Neural TTS previews 5 new languages
Five new voices and languages are introduced to the Neural TTS portfolio. They are: Grace in Maltese (Malta), Ona in Lithuanian (Lithuania), Anu in Estonian (Estonia), Orla in Irish (Ireland) and Everita in Latvian (Latvia). These voices are available in public preview in three Azure regions: EastUS, SouthEastAsia and WestEurope.
Hear samples of these voices, or try them with your own text in our demo.
Locale | Language | Voice name | Audio sample |
mt-MT | Maltese (Malta) | “mt-MT-GraceNeural” | Fid-diskors tiegħu, is-Segretarju Parlamentari fakkar li dan il-Gvern daħħal numru ta’ liġijiet u inizjattivi li jħarsu lill-annimali.
|
lt-LT | Lithuanian (Lithuania) | “lt-LT-OnaNeural” | Derinti motinystę ir kūrybą išmokau jau po pirmojo vaiko gimimo.
|
et-EE | Estonian (Estonia) | “et-EE-AnuNeural” | Pese voodipesu kord nädalas või vähemalt kord kahe nädala järel ning ära unusta pesta ka kardinaid.
|
ga-IE | Irish (Ireland) | “ga-IE-OrlaNeural” | Tá an scoil sa mbaile ar oscailt arís inniu.
|
lv-LV | Latvian (Latvia) | “lv-LV-EveritaNeural” | Daži tumšās šokolādes gabaliņi dienā ir gandrīz būtiska uztura sastāvdaļa.
|
With these updates, Azure TTS service now supports 54 languages/locales with 78 neural voices and 77 standard voices available.
Behind the scenes: 10X faster voice building with the low resource setting.
The creation of a TTS voice model normally requires a large volume of training data, especially for extending to a new language, where sophisticated language-specific engineering is required. In this section, we introduce “LR-UNI-TTS”, a new Neural TTS production pipeline to create TTS languages where training data is limited, i.e., ‘low-resourced’. With this innovation, we are able to improve the Neural TTS locale development with 10x agility and support the five new languages quickly.
High resource vs. low resource
Traditionally, it can easily take more than 10 months to extend TTS service to support a new language due to the extensive language-specific engineering required. This includes collecting tens of hours of language-specific training data, and creating hand-crafted components like text analysis etc.. In many cases, one major challenge for supporting a new language is that such large volume of data is unavailable or hard to find, causing a language ‘low-resourced’ for TTS model building. To handle the challenge, Microsoft researchers have proposed an innovative approach, called LRSpeech, to handle the extremely low-resourced TTS development. It has been proved that LRSpeech has the capability to build good quality TTS in the low-resource setting, using multilingual pre-training, knowledge distillation, and importantly the dual transformation between text-to-speech (TTS) and speech recognition (SR).
How LR-UNI-TTS works
Built on top of LRSpeech and the multi-lingual multi-speaker transformer TTS model (called UNI-TTS), we have designed the offline model training pipeline and the online inference pipeline for the low-resource TTS. Three key innovations contribute to the significant agility gains with this approach.
First, by leveraging the parallel speech data (the pairing speech audios and the transcript) collected during the speech recognition development, the LR-UNI-TTS training pipeline greatly reduces the data requirements for refining the base model in the new language. Previously, the high-quality multi-speaker parallel data has been critical in extending TTS to support a new language. The TTS speech data is more difficult to collect as it requires the data to be clean, the speaker carefully selected, and the recording process well controlled to ensure the high audio quality.
Second, by applying the cross-lingual speaker transfer technology with the UNI-TTS pipeline, we are able to leverage the existing high-quality data in a different language to produce a new voice in the target language. This saves the effort to find a new professional speaker for the new languages. Traditionally, the high-quality parallel speech data in the target language is required, which easily takes months for the voice design, voice talent selection, and recording.
Lastly, the LR-UNI-TTS approach uses characters instead of phonemes as the input feature to the models, while the high-resource TTS pipeline is usually composed of a multi-step text analysis module that turns text into phonemes, costing long time to build.
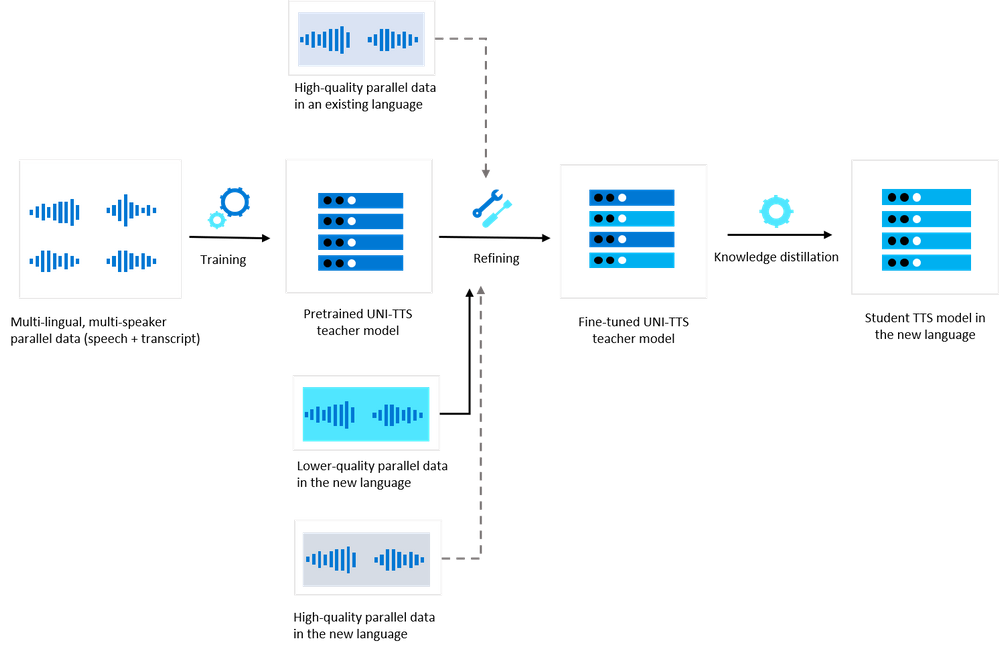
Below figure describes the offline training pipeline for the low-resource TTS voice model.

In specific, at the offline training stage, we have leveraged a few hundred hours of the speech recognition data to further refine the UNI-TTS model. It can help the base model to learn more prosody and pronunciation patterns for the new locales. The speech recognition data is usually collected in daily environments using PC or mobile devices, unlike the TTS data which is normally collected in the professional recording studios. Although the SR data can be much lower-quality than the TTS data, we have found LR-UNI-TTS can benefit from such data effectively.
With this approach, the high-quality parallel data in the new language which is usually required for the TTS voice training becomes optional. If such high-quality parallel data is available, it can be used as the target voice in the new language. If no high-quality parallel data is available, we can also choose a suitable speaker from an existing but different language and transfer it into the new language through the cross-lingual speaker transfer-learning capability of UNI-TTS.
In the below chart, we describe the flow of the runtime.

At the runtime, a lightweight text analysis is designed to preprocess the text input with sentence separation and text normalization. Compared to the text analysis component of the high-resource language pipelines, this module is greatly simplified. For instance, it does not include the pronunciation lexicon or letter-to-sound rules which are used in high-resource languages. The normalized text characters are generated by the lightweight text analysis component. During this process, we also leverage the text normalization rules from the speech recognition development, which saves the overall cost a lot.
The other components are similar to the high-resource language pipelines. For example, the neural acoustic model uses the FastSpeech model to convert the character input into mel-spectrogram.
Finally, the neural vocoder HiFiNet is used to convert the mel-spectrogram into audio output.
Overall, using LR-UNI-TTS, a TTS model in a new language can be built in about one month, which is 10x faster than the traditional approaches.
In the next section, we share the quality measurement results for the voices built with LR-UNI-TTS.
Quality assessments
Similar to other TTS voices, the quality of the low-resource voices created in the new languages are measured using the Mean Opinion Score (MOS) tests and intelligibility tests. MOS is a widely recognized scoring method for speech naturalness evaluation. With MOS studies, participants rate speech characteristics such as sound quality, pronunciation, speaking rate, and articulation on a 5-point scale, and an average score is calculated for the report. Intelligibility test is a method to measure how intelligible a TTS voice is. With intelligibility tests, judges are asked to listen to a set of TTS samples and mark out the unintelligible words to them. Intelligibility rate is calculated using the percentage of the correctly intelligible words among the total number of words tested (i.e., the number of intelligible words/the total number of words tested * 100%). Normally a usable TTS engine needs to reach a score of > 98% for intelligibility.
Below table summarizes the MOS score and the intelligibility score of the five new languages created using LR-UNI-TTS .
Locale | Language (Region) | Average MOS | Intelligibility |
mt-MT | Maltese (Malta) | 3.59* | 98.40% |
lt-LT | Lithuanian (Lithuania) | 4.35 | 99.25% |
et-EE | Estonian (Estonia) | 4.52 | 98.73% |
ga-IE | Irish (Ireland) | 4.62 | 99.43% |
lv-LV | Latvian (Latvia) | 4.51 | 99.13% |
* Note: MOS scores are subjective and not directly comparable across languages. The MOS of the mt-MT voice is relatively lower but reasonable in this case considering that the human recordings used as the training data for this voice also gots a lower MOS.
As shown in the table, the voices created with the low resources available are highly intelligible and have achieved high or reasonable MOS scores among the native speakers.
It’s worth pointing out that due to the nature of the lightweight text analysis module for the runtime, the phoneme-based SSML tuning capabilities are not supported for the low-resource voice models, for example, the ‘phoneme’ and the ‘lexicon’ elements.
Coming next: extending Neural TTS to even more locales
LR-UNI-TTS has paved the way for us to extend Neural TTS to more languages for the global users more quickly. Most excitingly, LR-UNI-TTS can potentially be applied to preserve the languages that are disappearing in the world today, as pointed out in the guiding principles of XYZ-code.
With the five new languages released in public preview, we welcome user feedback as we continue to improve the voice quality. We are also interested to partner with passionate people and organizations to create TTS for more languages. Contact us (mstts[at]microsoft.com) for more details.
What’s more: Neural TTS Container GA
Together with the preview of these five new languages, we are happy to share that the Neural TTS Container is now GA. With Neural TTS Container, developers can run speech synthesis with the most natural digital voices in their own environment for specific security and data governance requirements. Learn more about how to install Neural TTS Container and visit the Frequently Asked Questions on Azure Cognitive Services Containers.
Get started
With these updates, we’re excited to be powering natural and intuitive voice experiences for more customers, supporting more flexible deployment. Azure Text-to-Speech service provides more than 150 voices in over 50 languages for developers all over the world.
For more information:
- Try the TTS demo
- See our documentation
- Check out our sample code
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments