This article is contributed. See the original author and article here.
Well-running apps are critical to a great endpoint experience. Users are never happy when an app crashes or a device restarts and their flow is broken. Worst case scenario, they may even lose the work that they just did. Service desks help solve these problems, but they only have visibility into the ones that people report, not the ones where someone just suffers in silence. What is needed is greater visibility into these issues across the entire organization. The two new Microsoft Endpoint Manager features in Endpoint analytics give IT admins the visibility and insights needed to help improve this experience.
Both of these features — a new application reliability report and new data for reboot frequency in the existing startup performance report — reflect our commitment to the user experience because users are happier when work isn’t slowed down and IT can focus on helping drive the business when there are fewer support calls.
The application reliability report, available in preview and rolling out over the next few days, gives IT visibility into which desktop applications are hampering the user experience, due to frequent crashes and because they are broadly deployed to users. The report also offers suggestions for improving app performance and alerts IT to issues that users may not have created tickets for yet despite growing frustration, which can help decrease the number of support tickets in the long run.
How to use the application reliability report
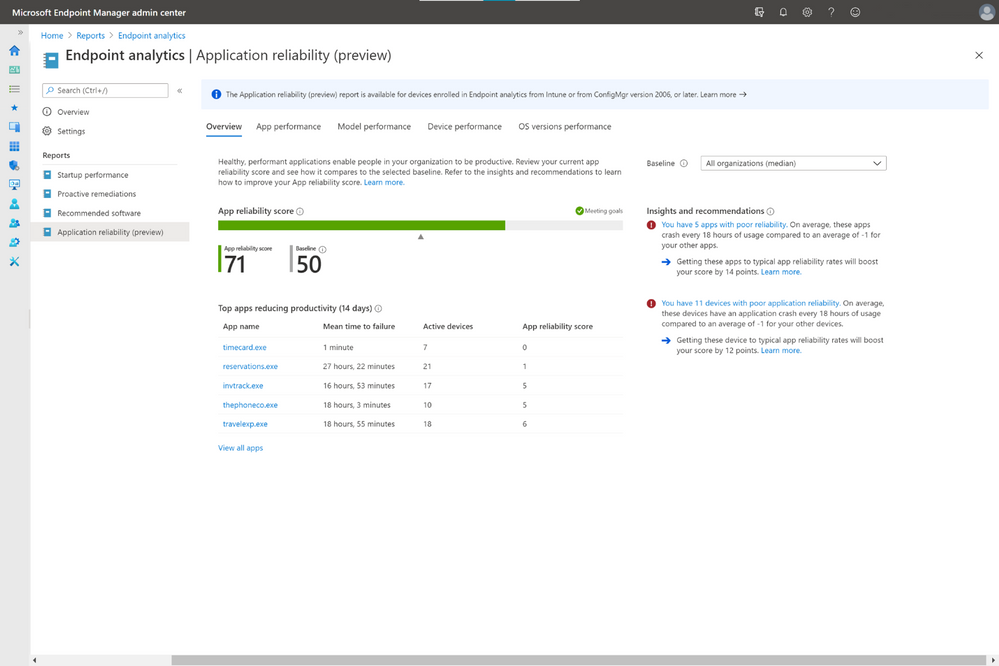
If your devices are Intune managed or co-managed, you don’t need to do anything to see the application reliability report. It sits alongside the rest of the Endpoint analytics reports in the Microsoft Endpoint Manager admin center console. If you have devices enrolled through tenant attach, upgrade to Configuration Manger 2006 for this report to populate. On the Overview page is your app reliability score as well as a baseline score, which, by default, represents the median across all commercial organizations. This can help you determine issues unique to your environment—and potentially caused by poor configurations—versus more widespread issues.
Below that is a list of the apps most likely to have reduced user productivity during the previous 14 days. This considers not only crash frequency but also usage to help reduce noise, such as one-off applications crashing 100 times on a single device. On the right column are app reliability Insights and Recommendations prioritized by which are most likely to boost your score.
In the App performance tab is a list of all your organization’s apps, which can be sorted by app name, publisher, active devices, app reliability score, and mean time to failure, which is the average number of times the app can be used across the organization between crashes.
You can also see your organization’s application reliability performance by other pivots like model, and OS version deployed, as well as troubleshoot application reliability issues with individual devices. In device performance, each device is given a device app health score, based on how often applications crashed on that device during the previous 14 days. Clicking into each device gives you a timeline of app crash and app hang events so you know exactly when crashes occurred, which can help speed troubleshooting.
New insights into device restart frequency
To help improve the user experience even further, we have also enhanced the existing startup performance report. New insights on device restart frequency, also known as reboot frequency, will help you identify problematic devices because reboots break the user from their flow and should not be needed often.
To help you better understand the type of reboots that happens, we classify each them as either normal or abnormal. Normal restarts are those that go through the normal Windows shutdown process. These include: Windows update installations, which typically occur once a month; non-update shutdowns from users, typically to save battery power; and non-update restarts, which shouldn’t occur often beyond monthly patching.
In contrast, abnormal restarts are ones that haven’t gone through the normal Windows shutdown process and could suggest problems that need to be investigated further. There are also three categories for this type of restart.
- Blue screens: This abnormal restart type is also called a stop error. Usually, less than two stop errors occur per device per year.
- Long power button press: This restart happens when a user holds down the power button to force a restart. These shutdowns are typically even less frequent than blue screens.
- Unknown: These are shutdowns that don’t fit either of the two other abnormal shutdown types. Microsoft will continue to research these to determine if additional categories should be added.

The restart frequency feature is now in preview and is rolling out to everyone over the next few days regardless of how you’ve configured the telemetry level or Windows Error Reporting in Windows Diagnostics.
Check out the rest of Endpoint analytics
There is so much more to Endpoint analytics than what we just covered. There are also reports on recommended software that help advise organizations on software that can help optimize OS and Microsoft versions for the best user experience. There is also the proactive remediations feature, giving you the power to automatically detect and remediate some of the top issues hampering users’ productivity — sometimes even before users realize something is wrong — while also helping reduce helpdesk call volume.
More information and feedback
For more information on getting started, visit the Endpoint analytics documentation, and check out the FAQ. Tweet your questions or feedback using the hashtag #MEMpowered and if you have an idea for a new feature, add it to UserVoice.
Please follow @MSIntune on Twitter
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments