This article is contributed. See the original author and article here.
In this guide, you will use the Azure Synapse Analytics Knowledge center to understand the Manage hub blade of Synapse Studio. You will learn how Synapse integrates with other data sources, even non-Azure ones, such as Amazon S3; explore data contained within those sources; and then address access control scenarios in Synapse to facilitate collaboration while keeping resources secure.
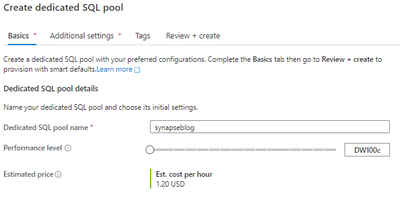
Creating a Dedicated SQL Pool in Manage Hub
To successfully complete this tutorial, you will need to have a dedicated SQL pool provisioned. Luckily, you can do this within the Manage hub. To access the Hub, locate the selector on the left-hand bar of Synapse Studio.

Under Analytics pools, select SQL pools. You will notice that your workspace comes with a serverless SQL pool by default. To create a dedicated pool, select + New.

Provide a name for your dedicated pool and set it to a reasonable performance tier.
Select Review + create. Then, select Create. Wait for your pool to provision and come online. If you want to learn more information about the difference between dedicated SQL pools and serverless SQL pools, you can find more here.
Creating a Pipeline from Knowledge Center
You will need to access the Knowledge center. Recall that it can be accessed under the ? button in the upper right-hand corner of Synapse Studio. Knowledge center will be the first menu option.

Select Browse gallery. Then, select Pipelines. Search for the Movie Analytics pipeline. Select the pipeline and then select Continue.

You will need to provide three user inputs to provision the pipeline: MoviesS3, MoviesADLS, and SinkDW.

On the right side of the page, under the Preview section, you also see a high-level view of the pipeline. Configure MoviesS3 first. Lower the dropdown menu and select + New. The New linked service (Amazon S3) window will open. Provide the following configuration:
- Name: Any descriptive name will suffice
- Authentication type: Access key
- Access Key ID: Provide the Access Key ID for an AWS IAM user with read permissions to the source S3 bucket
- Secret Access Key: The Secret Access Key for the IAM user
- Service URL: A path-style S3 URL referencing the bucket, not the CSV file in the bucket. Find more information here.

If you want to confirm your S3 connection settings, select the Test connection button in the bottom right-hand corner of the page. You can test the connection to the S3 bucket or to the moviesDB.csv file by changing the selection of the Test connection radio buttons. Either way, both tests should be successful.

Once the tests succeed, select Create. You have created your first linked service in Azure Synapse. Consider linked services like connection strings. Connection information is stored in linked services to simplify the process of creating datasets from sources. To specify the MoviesADLS input, select the dropdown. When you provisioned your Synapse workspace, you provisioned an Azure Data Lake Storage Gen2 account. Selecting your account linked service will suffice for this exercise.

Finally, specify SinkDW. Again, choose the default linked service. It refers to the DNS endpoint of your workspace’s dedicated SQL pool(s).

Now that you have specified all User inputs, select Open pipeline. In Synapse Studio, you will now see the Movie Analytics pipeline in the Data hub. We will be editing this pipeline soon.

Configuring the Movie Analytics Pipeline
Select the MoveFromS3ToADLS activity. Select the Source tab. Select Open next to the MoviesS3 dataset. Verify that the Connection information is set correctly:
- Linked service: The S3 linked service you created earlier
- File path: The location of your moviesDB.csv file in [bucket]/[directory]/moviesDB.csv format
- First row as header: selected
- Retain all other defaults

To test that your settings are correct, select the Preview data button.

Returning to the Copy data activity, select the Sink tab. Select Open next to the MoviesADLS dataset. Ensure that the following information is provided under the Connection tab.
- Linked service: Choose the reference to your workspace’s ADLS Gen2 account
- File path: sample-data/ready-demo/moviesDB.csv
- First row as header: selected
- Keep all other defaults

You are now ready to execute the Copy data activity. Add a breakpoint to the Copy data activity and debug it, as the image below demonstrates.

After a few seconds, in the Output tab, you should see that the activity succeeds.

You will now execute the AggregateAndWriteToDW data flow. First, turn on data flow debug. When you do this, Azure temporarily provisions an eight core cluster.

Choose OK for the Turn on data flow debug dialog.
Open the AggregateAndWriteToDW data flow.

Select the MoviesADLS source. Then choose the Data preview tab. Select Refresh to see the data loaded from ADLS Gen2.

Since the emphasis of this guide is not on the data handling capabilities of Azure Synapse Analytics, proceed to the SinkToDW sink. Under the Settings tab, ensure that Allow upsert is enabled.

Under the Sink tab, next to the Dataset dropdown, select Open.
Under the Connection tab, open Linked service properties. For DBName, provide the name of your dedicated SQL pool as the value. Keep the Table value the same (ADF_Lab_Sink).
Return to the Integrate hub and access the Movie Analytics pipeline.

Debug the pipeline. Do not set breakpoints.
In the Output tab, monitor the execution of both activities. As indicated below, the eyeglasses icon allows you to examine the debug results of a pipeline activity more in-depth.

Examining the results for the AggregateAndWriteToDW data flow should reveal that 737 rows were written to the SQL dedicated pool.

Feel free to Publish your new pipeline and your modifications to it. That will facilitate your knowledge of securing Azure Synapse resources.
Access Control in Azure Synapse Analytics
Now that you have created SQL pools, created and edited pipelines, and added linked services, this raises the question of securing your resources. To control access to your resources, Microsoft recommends the use of Azure Active Directory security groups, simplifying security administration to verifying that users are placed in the correct groups. For example, you might create a SynapseContributors security group for developers. Synapse Roles, like Synapse Contributor, can then be assigned to security principals, which include AAD groups. These role assignments can be limited to a certain scope.

Such a role assignment can be created in the Manage hub. Locate the Access control page under the Security tab and select Add. Here are a couple of Synapse Roles that you should be aware of:
- Synapse Administrator: Access to all Synapse resources and published artifacts. The recipient can grant others roles.
- Synapse Contributor: Access to all Synapse resources except managed private endpoints (more information below) and credentials.
Note that you can change the scope of your Azure Synapse role assignments. For example, we can give a certain user permissions to use the Synapse workspace’s managed identity (WorkspaceSystemIdentity). Note that the Synapse Roles you can assign to the security principal are reduced–in this example, only the Synapse Administrator and Synapse Credential User (preview) roles can leverage the managed identity. Managed identities provide simple and secure authentication to services that use Azure Active Directory for authentication, like Azure Data Lake.

Azure provides even more capabilities to govern the access and administration of Azure Synapse Analytics. For users to create compute resources, including SQL pools, they must have at least the Azure Contributor role on the workspace. This role assignment can be added through the Access control (IAM) panel of the Synapse workspace Azure resource.

Lastly, we will discuss SQL permissions. If you have the Synapse Administrator role, you are already a db_owner on the serverless pool which is provided with your workspace, Built-in. Suppose you are a developer on the project. The Synapse Administrators can give you access through the SynapseContributors group using the following commands:
CREATE DATABASE analyticsdb;
use analyticsdb
CREATE USER [SynapseContributors] FROM EXTERNAL PROVIDER;
ALTER ROLE db_owner ADD MEMBER [SynapseContributors];
SynapseContributors is an AAD security principal (group). To enter this script, navigate to the Develop hub. Then, create a new SQL script.

The situation is slightly different for the dedicated SQL pool. Instead of using the ALTER ROLE T-SQL statement, you use the sp_addrolemember stored procedure.
CREATE USER [SynapseContributors] FROM EXTERNAL PROVIDER;
EXEC sp_addrolemember ‘db_owner’, ‘SynapseContributors’;
In the Connect to bar, the dedicated pool is specified and the specific database used in the pipeline earlier has been selected.

Azure Synapse Analytics provides a whole host of access control solutions. To learn more, please consult this. We will conclude this post with a discussion of network security in Azure Synapse Analytics.
Network Security in Azure Synapse Analytics
Azure Synapse Analytics allows you to provision a managed virtual network for your workspace. With the managed VNet, administators do not need to handle the burden of configuring traffic management rules, since that configuration is handled by Synapse. Moreover, using the managed VNet provides support for managed private endpoints. These endpoints are created in the managed VNet and enable access to Azure services. Communication between private endpoints and Azure resources occurs over private links, which transfer data through Microsoft’s network infrastructure.

Examine the image above from the Microsoft documentation. Here are a couple of important ideas you can pull from this diagram:
- The SQL pools exist outside of the managed VNet, but they can be referenced using managed private endpoints
- Private endpoints can reference Azure resources within the same Azure tenant and even resources in subscriptions outside of the AAD tenant
Clearly, using managed virtual networks with your Synapse workspaces avoids data exfiltration. You can manage private endpoints in the Manage hub, as seen below. If you provision you workspace with support for managed VNets, endpoints referencing both the SQL pool and the serverless SQL pool are automatically created.

To reap the benefits of managed VNets in Synapse workspaces, you will need to provision your workspace with support for the managed VNet–you cannot add this after the workspace is provisioned.

In this image, managed virtual network support is enabled for this Synapse workspace deployment. Moreover, since the Allow outbound data traffic only to approved targets is set, the AD tenants of target resources will need to be added.
Clean-up
In this post, you created a dedicated SQL pool. To locate the pool, navigate to Manage hub, and select SQL pools below Analytics pools. Select the three dots next to the dedicated pool you created.

You can either Pause the SQL pool if it is running, or Delete the pool. Note that if you pause the dedicated pool, you will release the compute node(s), thus halting compute billing. Alternatively, you can delete the SQL pool.
Quick get started with Azure Synapse and try this tutorial with these resources:
- Sign up for an Azure free account and receive $200 of credit to try Azure Synapse
- Create an Azure Synapse workspace in minutes to access these new features
- Embark on your Azure Synapse self-study journey with the Microsoft Learn materials
- Check this blog daily to see a roundup of all the new tutorial blogs that will be posted for the next two weeks.

Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments