This article is contributed. See the original author and article here.
Hello Everyone,
One of the amazing journeys I have been lucky to be a part of is developing our self-tuning algorithms for detecting attacks on accounts in real-time. Back in 2012, we got tired of the treadmill of manually adapting to attackers and committed to adaptive learning systems. Today, I want to share some cool new work the team has delivered. When I started fighting account compromise at Microsoft, we put a lot of effort into building and maintaining a large set of heuristic rules that ran during authentication. These rules effectively spotted compromise based on observed behavior, but it was easy for attackers to change their patterns and bypass those rules. This meant that we were always in reactionary mode trying to update the heuristics every time an attack pattern changed, or a new attack evolved. At that point, we decided that the only scalable and maintainable way to prevent current attacks and adapt to block new attacks was to apply machine learning to the area of account compromise. After much research and many iterations, we built a real-time system that uses supervised machine learning to analyze the current compromise to adapt and block attacks as they happen.
Fast forward to today, we just released a re-design on the real-time machine learning compromise prevention system for Azure AD. The improved system still leverages supervised machine learning but it expands the features and process used to train the model, which provides significantly improved accuracy in Azure AD real-time risk assessment. The model flags more bad activity as risky while simultaneously reducing false alarms. This risk can be used by Azure AD Identity Protection customers as a condition in their Conditional Access policy engine to block risky sign-ins or ask for multi-factor authentication. Let’s dive into how the real-time compromise prevention system works.
The real-time ML system leverages intelligence from many sources, including:
- User behavior: is the user signing in from a known device, a known location, a known network?
- Threat intelligence: is the sign-in coming from a known bad, suspicious infrastructure?
- Network intelligence: is the IP address part of a mobile network, a proxy, a hosting facility?
- Device intelligence: is the device compliant or managed?
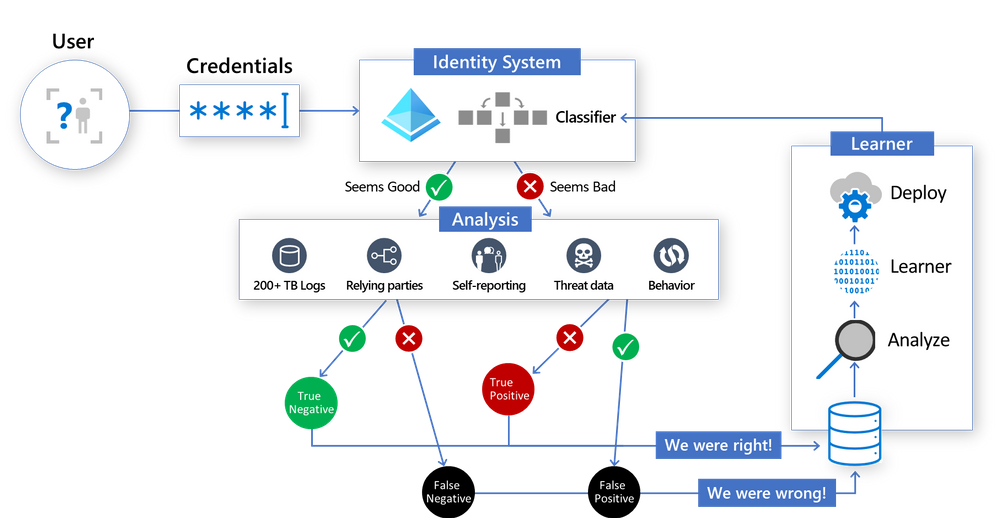
Known good or bad sign-ins are used to label the data and help “teach” the algorithm what is a good sign-in and what is a malicious sign-in. These known good and bad sign-ins are called labels and are a precious good when it comes to building AI systems for security. Our team has invested a lot in having good quality labels that can be used to train models and to assess the detection performance. One of our most significant assets is a team of highly trained analysts who work on data labelling by manually reviewing cases and making determinations. We also leverage other sources for labelling, such as customer feedback that we get directly from the Identity Protection UX and API, and threat intelligence sources from across Microsoft ecosystem.
All this intelligence is used to automatically train new supervised machine learning models, which are then deployed to the Azure AD authentication service and used to score 30 Billion authentications every day in real-time and taking just a few milliseconds per authentication. The new protection system is ever vigilant, regularly retraining the ML models dynamically adapt to changes in the bad actor ecosystem.
Here’s a look at how the new sign-in risk scoring system works – the classifier scores each login in the core Identity System, and then label data generated in the “Analysis” section is used by the Learner to generate an improved model, then the whole cycle starts again:
We are so excited about the improvement this new system provides and we want to show you the data. You can see Precision-Recall curves for the previous scoring system and the newly improved system in the chart below. Precision indicates the percentage of the sign-ins flagged as risky that are actually bad sign-ins. A recall is a measure of the percentage of all bad sign-ins that are flagged as risky. Each point in each line represents the precision and recall at a specific score. The score is the probability or confidence level that the model has about the sign-in being bad. In summary, the higher the precision and higher the recall, the better the model performs.

This is just one of the exciting new Identity Protection features our team has been working on. Our team continues to work with our customers, partners, and teams across Microsoft to offer customers the best Identity protection systems. If you want to find out more information about how machine learning systems like this works, be sure to check out a recent session from the Ignite conference entitled “The science behind Azure Active Directory Identity Protection”.
On the behalf of Azure AD team, thank you for all your feedback far. We hope you’ll continue to help us improve and share more about your experience with Azure AD Identity Protection. And be sure to follow us on Twitter (@AzureAD) to get the latest updates on Identity security.
Maria Puertas Calvo (@Maria_puertas_calvo)
Principal Lead Data Scientist
Microsoft Identity Division
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments