This article is contributed. See the original author and article here.
I want to share the following example in how you can use the “computed column” in some cases, to enhance your queries performance.
On AdventureWorks 2019 sample database, there are two tables TransactionHistory and TransactionHistoryArchive (I changed the type of productID on TransactionHistoryArchive from int to varchar), the tables definitions are :
CREATE TABLE [Production].[TransactionHistory](
[TransactionID] [int] IDENTITY(100000,1) NOT NULL,
[ProductID] [int] NOT NULL,
[ReferenceOrderID] [int] NOT NULL,
[ReferenceOrderLineID] [int] NOT NULL,
[TransactionDate] [datetime] NOT NULL,
[TransactionType] [nchar](1) NOT NULL,
[Quantity] [int] NOT NULL,
[ActualCost] [money] NOT NULL,
[ModifiedDate] [datetime] NOT NULL,
CONSTRAINT [PK_TransactionHistory_TransactionID] PRIMARY KEY CLUSTERED
(
[TransactionID] ASC
)
CREATE TABLE [Production].[TransactionHistoryArchive](
[TransactionID] [int] NOT NULL,
[ProductID] [varchar](10) NOT NULL,
[ReferenceOrderID] [int] NOT NULL,
[ReferenceOrderLineID] [int] NOT NULL,
[TransactionDate] [datetime] NOT NULL,
[TransactionType] [nchar](1) NOT NULL,
[Quantity] [int] NOT NULL,
[ActualCost] [money] NOT NULL,
[ModifiedDate] [datetime] NOT NULL,
CONSTRAINT [PK_TransactionHistoryArchive_TransactionID] PRIMARY KEY CLUSTERED
(
[TransactionID] ASC
)
Like in some situation in real environments, the ProductID column type in one of the tables is different than the other, usually due to a bad design.
I changed the ProductID from int to varchar to simulate the issue, and on both tables I created the index that covers the ProductID column:
create index ix_transaction_history_productid on [Production].[transactionhistory] (productid)
create index ix_transaction_historyArchive_productid on [Production].[transactionhistoryarchive] (productid) include (transactiondate)
Even though, if you are running an inner join query like the one below:
SELECT H.ProductID, a.TransactionDate
FROM [Production].[TransactionHistory] H inner join [Production].[TransactionHistoryArchive] A
on H.productid= A.productid where h.productid = 2
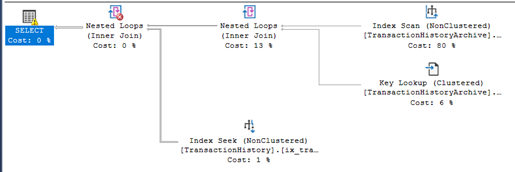
The execution plan is using index scan and not index seek.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
(450 rows affected)
Table ‘TransactionHistory’. Scan count 10, logical reads 20, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Table ‘TransactionHistoryArchive’. Scan count 1, logical reads 641, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
SQL Server Execution Times:
CPU time = 31 ms, elapsed time = 30 ms.
Another example, if you run an inner join without the where clause:
SELECT H.ProductID, a.TransactionDate
FROM [Production].[TransactionHistory] H inner join [Production].[TransactionHistoryArchive] A
on H.productid= A.productid
there will be index scans for both tables (Index Scan and Hash Join, hash is used usually when the two tables are Huge and unsorted.):

If you select the table by two different values (different types) , numeric and text values, the query optimizer will choose a scan operation if the parameter type of the predicate is different than the column:
SELECT A.TransactionDate
FROM [Production].[TransactionHistoryArchive] A
where A.productid = 2
SELECT A.TransactionDate
FROM [Production].[TransactionHistoryArchive] A
where A.productid = '2'

Obviously, the solution is to change the data type of column ProductID in one of the tables to avoid table scans and type conversion.
But you must put in consideration the following:
- The impact of the change on application and ETL packages. Some will fail and some will need to be updated or become having a slower performance.
A small change on database side may cause a lot of code modifications and updates on Applications.
- The database design, like table relations and foreign keys..etc.:

- The bad design and overall performance issues will appear more when the applicationdatabase is live and tables are growing and become huge in size, in testing phases it may not appear.
But you may consider another solution, it will require a small update on database side and mostly requires no code update on TSQL scripts or on application:
- Create a new persisted computed column on the table:
alter table [Production].[transactionhistoryarchive] add productid_CC as convert(int, productid) persisted - Create an index on the new computed column:
create index ix_transaction_historyArchive_productid_CC on [Production].[transactionhistoryarchive] (productid_CC) include (transactiondate)
with the help of the computed column and it is index, lets try the same queries without doing any changes on them:
SELECT H.ProductID, a.TransactionDate
FROM [Production].[TransactionHistory] H inner join [Production].[TransactionHistoryArchive] A
on H.productid= A.productid where h.productid = 2
the execution plan, the query optimized is using index seek for both tables, and number of logical reads decreased:

SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
(450 rows affected)
Table ‘TransactionHistory’. Scan count 10, logical reads 20, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Table ‘TransactionHistoryArchive’. Scan count 1, logical reads 3, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
Now the query optimizer is using index seeks; it is smart enough to implicitly use the index created on the computed column even if the computed column ProductID_CC is not explicitly mentioned.
It will be used for queries that have productID in the where clause or use it in physical operations like joins.
And again If you select the table by two different values (different types) , numeric and text values, the query optimizer will choose the seek operation:
SELECT A.TransactionDate
FROM [Production].[TransactionHistoryArchive] A
where A.productid = 2
SELECT A.TransactionDate
FROM [Production].[TransactionHistoryArchive] A
where A.productid = '2'


And the inner join query without where clause, now is using adaptive join instead of Hash:
SELECT H.ProductID, a.TransactionDate
FROM [Production].[TransactionHistory] H inner join [Production].[TransactionHistoryArchive] A
on H.productid= A.productid

Note that to create an index on computed column, the column must be deterministic:
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments