This article is contributed. See the original author and article here.
If you’ve been working with Azure OpenAI for a while, chances are you’ve heard of Semantic Kernel. It is a library implemented in multiple programming languages that can handle prompt templates, manage conversation state, integrate with plugins and many other features essential to building an advanced LLM-infused application. But how exactly do you “deploy” Semantic Kernel?
Being a software library, Semantic Kernel can be deployed to any compute option capable of running Python, C# or Java. You’ve probably seen sample repositories with Jupyter notebooks you can use to explore the functionality. But in most cases you can’t give your end-users a notebook! In this article, we’ll give you an example and a solution accelerator that you can use to bring your AI application to production faster.
Solution Architecture
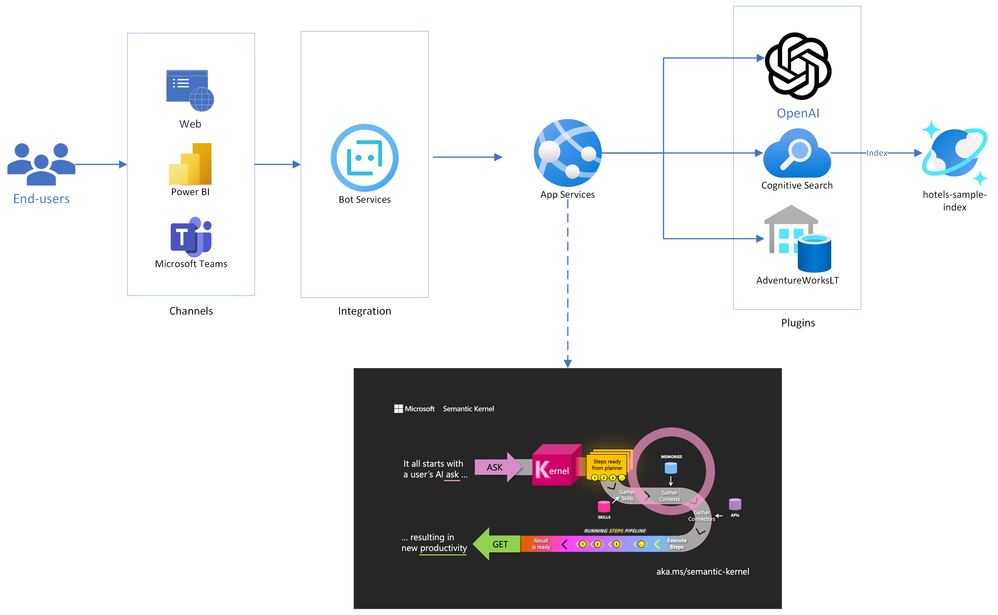
Below is the architecture diagram for the solution accelerator we put together. You can also pull the source code and deploy it yourself from our Github repo!
As you can see in the diagram, Semantic Kernel is at the core of the solution, and will act as the orchestrator of the chat experience. It is deployed into an App Services instance, which will also be running the Bot Framework SDK. This enables our bot to be deployed across multiple channels, including web pages, Teams, and even third-party chat platforms like Slack.
The flow of chat messages is as follows:
- End-users connect to a messaging channel your bot is published to, such as Web or Teams;
- Messages get processed through Azure Bot Services, which communicates with a .NET application running on App Services.
- The .NET application runs a Semantic Kernel Stepwise Planner at its core. The planner elaborates a series of steps to process the user’s request, and then executes it.
- Each step of the plan is formulated through Azure OpenAI, and the executed against Cognitive Search (traditional RAG pattern), Azure SQL (structured data RAG) or any other externally connected plugins.
- Now with the data gathered from plugins, the question is resubmitted to Azure OpenAI, where a final answer is formulated and presented to the end user. This concludes a conversation turn.
Built-in use cases
1. Traditional Retrieval-Augmented Generation (RAG)
To test out the traditional RAG pattern, we integrated a sample from the Azure Cognitive Search product called hotels-sample. It’s an index containing names, descriptions and other information about hotels, which you can search and filter through to explore the service.
First, we implemented the SearchPlugin class:

Notice how Semantic Functions – the functionality that Semantic Kernel can call upon – are structured. Each Semantic Function and each of its arguments must be annotated with a human-readable description. This description will then be passed to the LLM so it can decide when to utilize that function, and pass in the right parameters. You can check out the source code in our repo, but this function is basically submitting a search to the Azure Cognitive Search index.
With debugging enabled, we can see each step of how the interaction happens:

1. Thought: GPT-4 receives the question and determines it needs to use the SearchPlugin to respond.
2. Action: In the same step, GPT-4 formulates an action call with the appropriate parameters. The action is constructed in JSON format.
3. Observation: The plugin returns some hotel names and descriptions.
4. Final Answer: GPT-4 determines it now has all the information it needs, and provides an answer to the end user. Typically, this would be the only response the user sees!
This process of Thought-Action-Observation may repeat multiple times until the model obtains the required information. We’ll see an example of that in the next scenario.
2. Structured Data Retrieval-Augmented Generation
Much like Azure Cognitive Search, a SQL Database can be consumed by Semantic Kernel using the same technique. Again, we start by implementing a Plugin:

This is slightly more complex – we added three Semantic Functions:
- GetTables: Gets all tables in the database;
- GetSchema: Gets the schema for a specific table;
- RunQuery: Runs a query on the database;
We then expect the Semantic Kernel Planner to combine these as needed to reach a response. Let’s see an example, again with the debugging enabled to view intermediate steps:


This time, the conversation flow goes like this:
- Thought: GPT-4 receives the question and determines it needs to use the SQLPlugin to respond.
- Action: The first action required is to list tables to get the right table name for customers
- Observation: The plugin returns the table names in the database.
- Thought: Now knowing the correct table name, GPT-4 can formulate a query to get the number of customers
- Action: The action is to run a COUNT query on the SalesLT.Customer table
- Observation: The plugin returns the count of customers
- Final Answer: GPT-4 determines it now has all the information it needs, and provides the number of customers to the end user. Again, in a production scenario, this is the only answer the end-user would see.
3. Upload and analyze documents
The third and final common scenario we added to the accelerator is the upload of documents. Users can use the built-in upload function to send PDF files, and the bot will break them down and use Vector search to find relevant information.
Once again, starting with the plugin implementation:

And moving on to the Web Chat:


Conclusion
Semantic Kernel is a very powerful and extensible tool, but deployment can be a challenge if you don’t know where to start. In this article, we provided a solution accelerator template you can use to quickly get to production, and create your own plugins and extensions.
Also please note that you’re responsible for what plugins you place in the hands of your end users! Imagine what would happen if a user asked “please drop the AdventureWorksLT database”. For that reason, you need to make sure your application has the precise role assignments to enable the actions it needs to perform, while limiting anything that should be out of its reach. Always keep security first!
In case you missed the GitHub repository link, here it is! Make sure to drop a star if it helped you!
https://github.com/Azure/semantic-kernel-bot-in-a-box
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments