This article is contributed. See the original author and article here.
Clickstream analysis is the process of collecting, analysing and reporting aggregated data about user’s journey on a website. User’s interactions with websites are collected, with applications like Adobe analytics and Tealium. Bringing clickstream data into a centralised place and combining it with other data sources for rich analytics is often required.
Typically clickstream data can reach around 2-3TB/day in size. Using Relational databases to analyse such data might not be suitable or cost effective.
Azure Data Explorer is a fast, fully managed data analytics service for real-time analysis on large volumes of Telemetry, Logs, Time Series data streaming from applications, websites, IoT devices, and more.
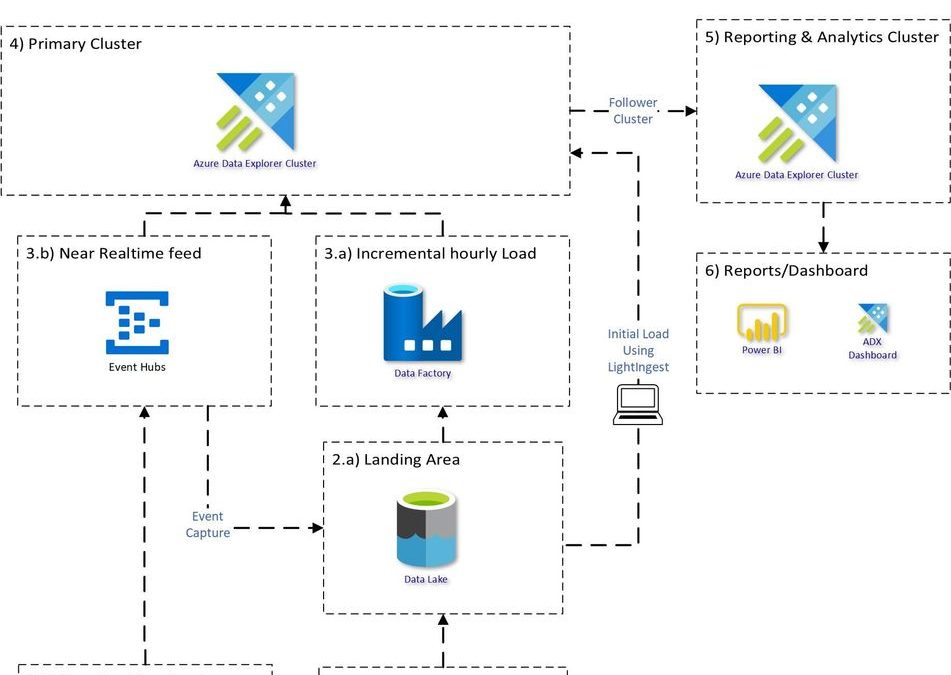
Proposed Architecture:
An end to end proposed architecture how you can use Azure Data Explorer to bring Clickstream historical and incremental data into Azure Data Explorer and analyse, aggregate and visualise the data.

Source System:
1.a) Adobe Analytics dataset usually contains about 1000+ fields. Adobe Analytics provides Data feed functionality which can be used to extract the data to Azure Data Lake Store. Data can be extracted with different configurations:
- Frequency: daily or hourly
- Format: .zip or .gz format
- Files: Single vs Multiple
1.b) Tealium datasets are extracted in JSON structure with 100’s of nested fields. The data can be sent to Azure Event hub in near realtime.
Bringing Data into ADX:
Creating the table structure and mapping for 1000+ column is a cumbersome task, it can be made easy with 1 Click Ingestion.
There are multiple ways to load the data.
3) Historical Load using Lightingest:
LightIngest is a command-line utility for ad-hoc data ingestion into Azure Data Explorer.
Simplest and efficient way to load all the historical data, with just one command.
LightIngest.exe "https://ingest-<<ClusterName.ClusterRegion>>.kusto.windows.net;Fed=True" -database:<<DatabaseName>> -table:<<TableName>> -source:" https://<<StorageName>>.blob.core.windows.net/<<ContainerName>>;<<StorageAccountKey>> " -prefix:"<<FolderPath>>" -pattern:*.tsv.gz -format:tsve
Although adobe files are in TSV format but due to special characters in the files, you should use the format TSVE in ADX.
Similarly, for Tealium historical load, use Json format.
Incremental Load:
3.a)
For Adobe batch file loading subscribe to eventgrid.
Alternatively, ADF is useful for loading because you can easily control the loading flow, and manage all your ETL or ELT pipelines from a single tool. Example pipeline (Template attached)

.ingest command:
.ingest into table @{pipeline().parameters.tableName} (h'abfss://@{variables('containerName')}@{pipeline().parameters.storageName}.dfs.core.windows.net/@{variables('folderPath')}/@{pipeline().parameters.fileName};@{activity('GetAccountKeyFromKV').output.value}') with (format='tsve',ingestIfNotExists = '["@{pipeline().parameters.fileName}"]', tags = '["ingest-by:@{pipeline().parameters.fileName}"]',creationTime='@{variables('inputFileDateTime')}')
3.b) For Tealium real time streaming connect Eventhub to ADX table:
4) Expected Compression ratio:
Source | Data Size | Input Format | ADX Mapping Format | Expected Data Size in ADX |
Adobe Analytics | XX – TB | TSV | TSVE | XX/10 TB (10x Compression) |
Tealium | XX – TB | JSON | JSON | XX/3.5 TB (3.5x Compression) |
5) Querying & Analytical workload:
The Analytical work requires more compute but is usually required at working hours. Using a follower cluster will make it easy to pause/resume and optimise for read workload. This will be useful for charge back to different groups and will provide workload isolation.
Cluster pause/resume can be done using Logic app or Azure Automation.
Estimated Cluster Size:
The cluster size will depend on the daily data ingestion and how many days needs to be retained in hot cache. You can estimate your cluster size based on your requirements.
Costing for 2TB daily load with 10x compression.

You can monitor your workload and adjust your cluster accordingly.
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments