by Contributed | May 26, 2021 | Technology
This article is contributed. See the original author and article here.
Sync Up is your monthly podcast hosted by the OneDrive team taking you behind the scenes of OneDrive, shedding light on how OneDrive connects you to all your files in Microsoft 365 so you can share and work together from anywhere. You will hear from experts behind the design and development of OneDrive, as well as customers and Microsoft MVPs. Each episode will also give you news and announcements, special topics of discussion, and best practices for your OneDrive experience.
So, get your ears ready and Subscribe to Sync up podcast!
Our guest today is Chenying Yang, a senior Program Manager on OneDrive focusing on making OneDrive Sync great across consumer and enterprise. OneDrive Sync Admin Reports empowers IT admins with actionable insights about the adoption and health of the sync client. These reports give visibility into who in your company is running the OneDrive Sync app, how is Known Folder Move rollout going, as well as surfacing any errors that end users might be experiencing so you can proactively address them. You’ll also learn the team’s favorite go-to beverages to wind up or wind down.
Tune in!
Meet your show hosts and guests for the episode:
Jason Moore is the Principal Group Program Manager for OneDrive and the Microsoft 365 files experience. He loves files, folders, and metadata. Twitter: @jasmo
Ankita Kirti is a Product Manager on the Microsoft 365 product marketing team responsible for OneDrive for Business. Twitter: @Ankita_Kirti21
Chenying Yang is a senior Program Manager on OneDrive focusing on making OneDrive Sync great across consumer and enterprise
Twitter: @CYatSeattle
Quick links to the podcast
Links to resources mentioned in the show:
Be sure to visit our show page to hear all the episodes, access the show notes, and get bonus content. And stay connected to the OneDrive community blog where we’ll share more information per episode, guest insights, and take any questions from our listeners and OneDrive users. We, too, welcome your ideas for future episodes topics and segments. Keep the discussion going in comments below.
As you can see, we continue to evolve OneDrive as a place to access, share, and collaborate on all your files in Office 365, keeping them protected and readily accessible on all your devices, anywhere. We, at OneDrive, will shine a recurring light on the importance of you, the user. We will continue working to make OneDrive and related apps more approachable. The OneDrive team wants you to unleash your creativity. And we will do this, together, one episode at a time.
Thanks for your time reading and listening to all things OneDrive,
Ankita Kirti – OneDrive | Microsoft
by Contributed | May 26, 2021 | Technology
This article is contributed. See the original author and article here.
This week at Microsoft’s annual Build conference, we made two announcements related to Azure Durable Functions: Two new backend storage providers, and the General Availability of Durable Functions for PowerShell. In this post, we’ll go into more details about the new capabilities that Durable Functions brings to PowerShell developers.
Stateful workflows with Durable Functions
Durable Functions is an extension to Azure Functions that lets you write stateful workflows in a serverless compute environment.
Using a special type of function called an orchestrator function, you can write PowerShell code to describe a stateful workflow that orchestrates other PowerShell Azure Functions that perform activities in the workflow. Using familiar PowerShell language constructs such as loops and conditionals, your orchestrator function can execute complex workflows that consist of activity functions running in sequence and/or concurrently. An orchestration can be started by any Azure Functions trigger. Additionally, it can wait for timers or external input and handle errors using try/catch statements.
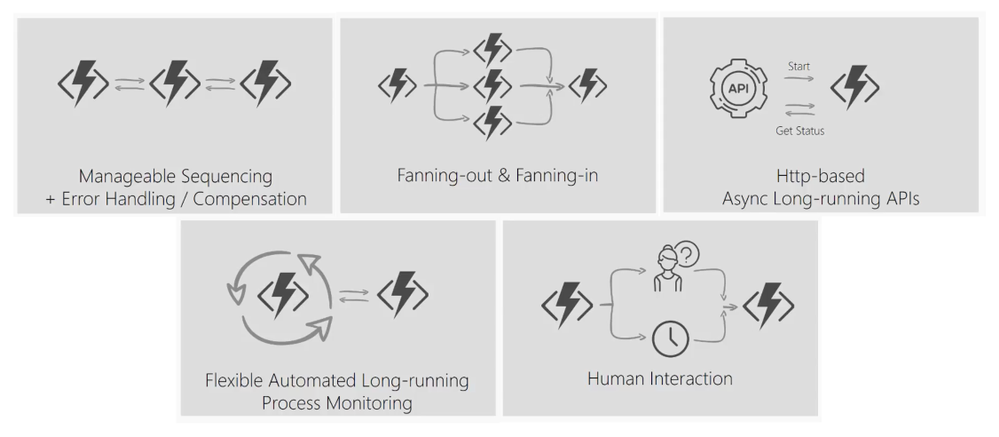
Some patterns supported by Durable Functions
Uses for Durable Functions in PowerShell
With a large ecosystem of modules, PowerShell Azure Functions are extremely popular in automation workloads. Many modules integrate with managed identity—making PowerShell Azure Functions especially useful for managing Azure resources and calling the Microsoft Graph. Durable Functions allows you to extend Azure Functions’ capabilities by composing multiple PowerShell Azure Functions together to perform complex automation workflow scenarios.
Here are some examples of what you can achieve with Durable Functions and PowerShell.
Automate resource provisioning and application deployment
PowerShell Azure Functions are commonly used to perform automation of Azure resources. This can include provisioning and populating resources like Storage accounts and starting and stopping virtual machines. Often, these operations can extend beyond the 10-minute maximum duration supported by Azure Functions in the Consumption plan.
Using Durable Functions, you can decompose your sequential workflow into a Durable Functions orchestration that consists of multiple shorter functions. The orchestration can last for hours or longer, and you write it in PowerShell. It can include logic for retries and custom error handling. In addition, Durable Functions automatically checkpoints your progress so if your orchestration is interrupted for any reason, it can automatically restart and pick up where it left off.
param($Context)
$Group = Invoke-ActivityFunction -FunctionName 'CreateResourceGroup'
$VM = Invoke-ActivityFunction -FunctionName 'CreateVirtualMachine' -Input $Group
do {
$ExpiryTime = New-TimeSpan -Seconds 10
$TimerTask = Start-DurableTimer -Duration $ExpiryTime
$VMStatus = Invoke-ActivityFunction -FunctionName 'CreateVirtualMachine' -Input $VM
}
until ($VMStatus -eq 'started')
Invoke-ActivityFunction -FunctionName 'DeployApplication' -Input $VM
Invoke-ActivityFunction -FunctionName 'RunJob' -Input $VM
Invoke-ActivityFunction -FunctionName 'DeleteResourceGroup' -Input $Group
Orchestrate parallel processing
Durable Functions makes it simple to implement fan-out/fan-in. Many workflows have steps that can be run concurrently. You can write an orchestration that fans out processing to many activity functions. Using the power of the Cloud, Durable Functions automatically schedules the functions to run on many different machines in parallel, and it allows your orchestrator to wait for all the functions to complete and access their results.
param($Context)
# Get a list of work items to process in parallel.
$WorkBatch = Invoke-ActivityFunction -FunctionName 'GetWorkItems'
# Fan out
$ParallelTasks =
foreach ($WorkItem in $WorkBatch) {
Invoke-ActivityFunction -FunctionName 'ProcessItem' -Input $WorkItem -NoWait
}
$Outputs = Wait-ActivityFunction -Task $ParallelTasks
# Fan in
Invoke-ActivityFunction -FunctionName 'AggregateResults' -Input $Outputs
Audit Azure resource security
Any of Azure Functions’ triggers can start Durable Functions orchestrations. Many events that can occur in an Azure subscription, such as the creation of resource groups and Azure resources, are published to Azure Event Grid. Using the Event Grid trigger, you can listen for resource creation events and kick off a Durable Functions orchestration to perform checks to ensure permissions are correctly set on each created resource and automatically apply role assignments, add tags, and send notifications.
 Create an Azure Event Grid subscription that invokes a PowerShell Durable Function
Create an Azure Event Grid subscription that invokes a PowerShell Durable Function
Try PowerShell Durable Functions
PowerShell Durable Functions are generally available and you can learn more about them by reading the documentation or by trying the quickstart.
by Contributed | May 26, 2021 | Technology
This article is contributed. See the original author and article here.
Create three scripts scripts:
SELECT ‘ALTER TABLESPACE ‘||tablespace_name||’ OFFLINE NORMAL;’ from DBA_TABLESPACES;
SELECT ‘ALTER DATABASE RENAME FILE ”’||NAME|| ”’ TO ‘||NAME||’;’ from V$DATAFILES;
SELECT ‘ALTER TABLESPACE ‘||tablespace_name||’ ONLINE;’ from DBA_TABLESPACES;
Now I could update this with the location path for where I want my new files and then proceed to shutdown the database, copy the files after I run the first script for each tablespace, then update the metadata for the datafile location and then bring it back online.
So the steps would be-
- Take the tablespace offline.
- Copy the file to the new location.
- Update the metadata to point to the new location
- Put the tablespace online.
AS this database isn’t active, I can do this…but with ASM…I have two choices that are the common path for copying datafiles to a new diskgroup:
1. RMAN copy
2. DBMS_FILE_TRANSFER
Due to a design challenge in the path naming, etc., I wasn’t able to use DBMS_FILE_TRANSFER and had to use RMAN, but it also meant I had to put the database in archive log mode to choose this second option.
Example of a file copy using DBMS_FILE_TRANSFER:
BEGIN
DBMS_FILE_TRANSFER.COPY_FILE(
source_directory_object => ‘+DATA_DG1/oradata/DB1’,
source_file_name => ,’edata_01.dbf’
destination_directory_object => ‘SDATA’,
destination_file_name => ‘edata_01.dbf’);
END;
There’s a lot more to do with either when ASM is involved. With the logical design of the physical datafiles, all changes have to be done via Multiple tools:
- Present the storage to ASM
- Create the disk
- Create the diskgroup
Take the inventory as we would above, then I need to put the database in archivelog mode to use RMAN:
RMAN> report schema;
List of Permanent Datafiles
===========================
File Size(MB) Tablespace RB segs Datafile Name
—- ——– ——————– ——- ————————
1 1920 SYSTEM YES +DATA_DG1/oradata/DB1/system01.dbf
2 2850 SYSAUX NO +DATA_DG1/oradata/DB1/sysaux01.dbf
3 373760 UNDOTBS1 YES +DATA_DG1/oradata/DB1/undotbs01.dbf
4 250 USERS NO +DATA_DG1/oradata/DB1/users01.dbf
5 6213231 SDATA NO +DATA_DG1/oradata/DB1/sdata_01.dbf
6 68817 WDATA NO +DATA_DG1/oradata/DB1/wdata_01.dbf
7 5120 IDATA NO +DATA_DG1/oradata/DB1/idata_01.dbf
8 1024 EDATA NO +DATA_DG1/oradata/DB1/edata_01.dbf
9 2048 XDB NO +DATA_DG1/oradata/DB1/xdb.dbf
List of Temporary Files
=======================
File Size(MB) Tablespace Maxsize(MB) Tempfile Name
—- ——– ——————– ———– ——————–
1 373760 TEMP 67108863 +DATA_DG1/oradata/DB1/temp01.dbf
What’s required for RMAN with ASM datafile copies for a new diskgroup?
- Backup the datafile as a copy, format it with the new diskgroup.
- Offline the datafile
- Switch the datafile to the copy, which is pointed to the new diskgroup
- Recover the datafile copy
- Online the datafile
- Delete the previous datafile, (now viewed as the copy)
Unless you format your datafile backups with additional configurations, there’s very little dynamic SQL that can assist in getting this automated for you, as your new files will have the dynamic generated file extension for ASM. In our example below, we’ll use the Users tablespace datafile, which is datafile #4:
BACKUP AS COPY
DATAFILE 4
FORMAT “+SDATA”;
SQL “ALTER DATABASE DATAFILE ”+DATA_DG1/oradata/DB1/users01.dbf” OFFLINE”;
SWITCH DATAFILE “+DATA_DG1/oradata/DB1/users01.dbf” to COPY;
RECOVER DATAFILE “+DATA_DG1/oradata/DB1/users01.259.1073503311”;
SQL “ALTER DATABASE DATAFILE ” +DATA_DG1/oradata/DB1/users01.259.1073503311” ONLINE”;
DELETE DATAFILECOPY “+DATA_DG1/oradata/DB1/users01.dbf”;
Notice that some of the syntax involved quotes and others involve double, single ticks. You need to make sure you use the correct ones for the push of a SQL statement via RMAN vs. the commands to identify the ASM datafile path.
Unlike a Linux/Unix MV command, RMAN ends up making three copies of the file instead of two, which means you need a little bit more space, (also depends on you settings for ASM redundancy, too):
1. Original
2. The copy in the new Diskgroup
3. A third used for the substantiated file to bring online before it drops the older copy.
With the time that it takes to back up and move files, for any tablespaces that didn’t have anything in them and for temp and undo, it was simpler to just create new ones that run through the steps to move a datafile that didn’t have anything in it.
All this reminded me was why I’m a performance DBA and not a backup and recovery DBA…. :)
CREATE TEMPORARY TABLESPACE TEMP2 TEMPFILE
‘+SDATA’ SIZE 100M AUTOEXTEND ON NEXT 1024M MAXSIZE UNLIMITED
TABLESPACE GROUP ”
EXTENT MANAGEMENT LOCAL UNIFORM SIZE 1M;
CREATE UNDO TABLESPACE UNDOTBS2 DATAFILE
‘+SDATA’ SIZE 100M AUTOEXTEND ON NEXT 1024M MAXSIZE UNLIMITED
RETENTION NOGUARANTEE;
ALTER SYSTEM SET UNDO TABLESPACE=UNDOTBS2;
ALTER DATABASE SET DEFAULT TEMPORARY TABLESPACE=TEMP2;
In the end I ended up with the following RMAN schema report:
List of Permanent Datafiles
===========================
File Size(MB) Tablespace RB segs Datafile Name
—- ——– ——————– ——- ————————
1 1920 SYSTEM YES +SDATA/DB1/DATAFILE/system01.263.1073698411
2850 SYSAUX NO +SDATA/DB1/DATAFILE/sysaux01.265.1073712889
4 250 USERS NO +SDATA/DB1/DATAFILE/users01.264.1073711908
5 6213231 SDATA NO+SDATA/DB1DATAFILE/sdata_01.262.1073711893
6 68817 WDATA NO +SDATA/DB1/DATAFILE/wdata.259.1073503311
7 5120 IDATA NO +SDATA/DB1/DATAFILE/idata.258.1073502989
8 1024 EDATA NO +SDATA/DB1/DATAFILE/edata.257.1073502623
9 2048 XDB NO +SDATA/DB1/DATAFILE/xdb.256.1073501461
10 1024 UNDOTBS2 YES +SDATA/DB1/DATAFILE/undotbs2.260.1073514289
List of Temporary Files
=======================
File Size(MB) Tablespace Maxsize(MB) Tempfile Name
—- ——– ——————– ———– ——————–
1 373760 TEMP 67108863 +DATA_DG1/oradata/DB1/temp01.dbf
2 1024 TEMP2 65535 +SDATA/DB1/TEMPFILE/temp2.262.1073514495
Only the one tempfile exists in the old diskgroup and it’s no longer used by anything or anyone. All temp usage has been switched over to the TEMP2 tablespace that has the new tempfile residing in +SDATA diskgroup.
by Contributed | May 26, 2021 | Technology
This article is contributed. See the original author and article here.
select 'ALTER TABLESPACE '||tablespace_name||' OFFLINE NORMAL;' from DBA_TABLESPACES;
select 'ALTER DATABASE RENAME FILE '''||NAME|| ''' TO '||NAME||';' from V$DATAFILES;
select 'ALTER TABLESPACE '||tablespace_name||' ONLINE;' from DBA_TABLESPACES;
by Contributed | May 26, 2021 | Technology
This article is contributed. See the original author and article here.
This week at Microsoft’s annual Build conference we made two announcements related to Azure Durable Functions: Two new backend storage providers, and the GA of Durable Functions for PowerShell. In this post, we’ll go into more details about the new storage providers and what they mean for Durable Functions developers.
New Storage Providers
Azure Durable Functions now supports two new backend storage providers for storing durable runtime state, “Netherite” and Microsoft SQL Server (including full support for Azure SQL Database). These new storage options allow you to run at higher scale, with greater price-performance efficiency, and more portability compared to the default Azure Storage configuration. Any of these three storage providers can now be configured without making any code changes to your existing apps.
To learn more, read the Durable Functions storage providers documentation, which also contains a side-by-side comparison of all three supported storage providers.
Durable Functions enables you to write long-running, reliable, event-driven, and stateful logic on the serverless Azure Functions platform using every day imperative code. Since its GA release in 2018, the Durable Functions extension transparently saved execution state into an Azure Storage account, ensuring that functions could recover automatically from any infrastructure failure. The convenience and ubiquity of Azure Storage accounts made it easy to get up-and-running in production with Durable Functions apps in a matter of minutes.
Limitations of the Azure Storage provider
Azure Storage is and will continue to be the default storage provider for Durable Functions. It uses queues, tables, and blobs to persist orchestration and entity state. It also uses blobs and blob leases to manage partitions across a distributed set of nodes. While the Azure Storage provider is the most convenient and lowest-cost option for persisting runtime state, it also has some notable limitations that may prevent it from being usable in certain scenarios.
- Azure Storage has limits on the number of transactions per second for a storage account, limiting the maximum scalability of a Durable Function app.
- Azure Storage has strict data size limits for queue messages and Azure Table entities, requiring slow and expensive workarounds when handling large payloads.
- Azure Storage costs can be hard to predict since they are per-transaction and have very limited support for batching.
- Azure Storage can’t easily support certain enterprise business continuity requirements, such as backup/restore and disaster recovery without data loss.
- Azure Storage can’t be used outside of the Azure cloud.
After speaking with customers who were impacted by some of these limitations, it became clear to us that we needed to invest in alternative storage providers to ensure the needs of all Durable Functions customers could be met.
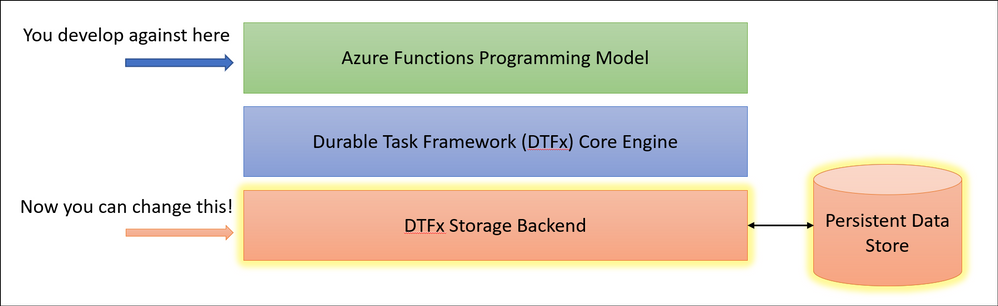
Fortunately, the architecture of Durable Functions and the underlying Durable Task Framework made it simple for us to enable swapping out backend storage providers without requiring customers to make any code changes. Starting in Durable Functions v2.4.3, we allow you to swap providers by adding a new extension and making a simple configuration change in your host.json file.
Introducing “Netherite” for maximum orchestration throughput
If you’re a fan of Minecraft, you’ll recognize that “Netherite” is the name of a rare material that is more durable than diamond, can float in lava, and cannot burn. The Netherite storage provider aspires to have similar qualities, but in the context of Durable Functions. It was designed and developed in collaboration with Microsoft Research. It combines the high-throughput messaging capabilities of Azure Event Hubs with the FASTER database technology on top of Azure Page Blobs. The design of Netherite enables significantly higher-throughput processing of orchestrations and entities compared to other Durable storage providers. In some benchmark scenarios, throughput was shown to increase by more than an order of magnitude when compared to the default Azure Storage provider!

The orchestrator used in the above test is a simple function-chaining sample with 5 activity calls running on the Azure Functions Elastic Premium plan:

The significant increase in throughput shown in the above chart can be achieved using a single Azure Event Hubs throughput unit (1 TU), costing approximately $22/month USD (~€18) on the Standard plan (at the time of writing). Much of this performance gain can be attributed to advanced techniques, such as asynchronous snapshotting and speculative communication, as described in the Serverless Workflows with Durable Functions and Netherite research paper.
For more information and getting-started instructions for the Netherite provider, see the Netherite documentation.
Microsoft SQL for maximum control and portability
While the Netherite provider was designed for maximum throughput, the Microsoft SQL (MSSQL) provider for Durable Functions was designed for the needs of the enterprise, including the ability to decouple from the Azure cloud.
Microsoft SQL can run anywhere, including on-premises servers, Edge devices, Linux Docker containers, on the Azure SQL Database serverless tier, and even on competitor cloud providers like AWS and GCP. This means you can run Durable Functions anywhere that Azure Functions can run, including your own Azure Arc-enabled Kubernetes clusters. In fact, the Azure Functions Core Tools and the Azure Arc App Service extension have been updated to support automatically configuring Durable Function apps on a Kubernetes cluster with the MSSQL KEDA scaler for elastic scale-out.

In addition to portability, you also get many other benefits of using Azure SQL database or Microsoft SQL for storing runtime state, including its long-established support for backup/restore, business continuity (high availability and disaster recovery), and data encryption.
The design of the Microsoft SQL storage provider for Durable Functions also makes it easy to integrate with existing SQL-based applications. When your function app starts up, it automatically provisions a set of tables, SQL functions, and stored procedures in the target database within a “dt” schema (“dt” stands for Durable Tasks). You can easily monitor your orchestrations and entities by running SELECT queries against these tables. You can also start new orchestrations using T-SQL and invoking the dt.CreateInstance stored procedure. This is especially useful if you want to extend an existing line-of-business application that already use SQL Server or Azure SQL Database by incorporating database triggers.
For more information and getting-started instructions for the Microsoft SQL provider, see the Durable Task SQL Provider documentation.
Concluding thoughts
We’re really excited about the new possibilities for customers building solutions using Durable Functions. With the availability of the two new storage backends, we hope to see new types of serverless apps get built which may not have been possible before. To be clear, the default Azure Storage provider option isn’t going anywhere, and we’ll continue to promote it as the easiest and lowest cost option for Durable Functions. Customers simply have new options which weren’t previously available.
So which one should you choose? I made a simple graphic to help you decide.

You can find a more comprehensive comparison of the three storage providers here.
As always, the development for Durable Functions happens in the open on GitHub and the new backends are no exception. You can find the Netherite provider at microsoft/durabletask-netherite and the Microsoft SQL provider at microsoft/durabletask-mssql. We encourage you to open issues in these repos and contribute PRs if you have ideas for how we can make them better (we’ve already accepted a few external contributions). Also, don’t forget to give us a :glowing_star: and subscribe for notifications of new releases using the “Watch” button.
by Contributed | May 26, 2021 | Technology
This article is contributed. See the original author and article here.
It’s Build week at Microsoft and I’m excited to see developers, students, and startups from around the world participate in all the great virtual sessions. During the past year, the pandemic accelerated existing trends in remote work. Even though people have recently started to transition back to the office, we expect that hybrid work will become a norm that fundamentally changes the cybersecurity landscape. As a result, most of our customers have embarked on a journey toward the modern Zero Trust security approach.
Zero Trust is a holistic security strategy that follows three simple principles – verify explicitly, use least privileged access, and assume breach. Each organization’s journey is unique and every single step of this journey can make the entire organization more secure. Every team and individual plays a role to make their organization more secure. If salute developers for their critical role in the successful implementation of Zero Trust strategies, like building trustworthy apps that follow Zero Trust principles. Applications should be ready for changes to work seamlessly when organizations start to roll out Zero Trust into their environments. To support these efforts, we have released innovative capabilities on the Microsoft identity platform that enable developers to lead the way in Zero Trust adoption. Let’s dive into the capabilities that can help you build Zero Trust-ready apps.
First Zero Trust principle: Verify explicitly
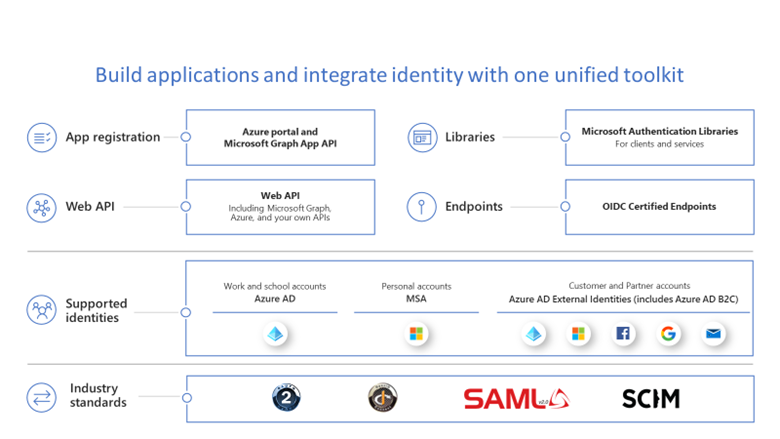
This principle recommends that apps authenticate and authorize based on all available data points, such as user identity, location, device health, and anomalies. It would be a tall order for developers to implement this principle on their own, but using the Microsoft identity platform would definitely get apps to achieve this.
Developers should maximize their chance of low-friction customer adoption in Zero Trust environments. With the Microsoft identity platform, developers can enable customers or IT teams to utilize built-in security capabilities for adhering to “Verify explicitly” principle.
For example, Conditional Access policies enable IT administrators to limit app access to only users who meet criteria specified by security. With Conditional Access authentication context, customers can leverage more granular step-up authentication available within Conditional Access policies. Also, Continuous Access Evaluation for Microsoft Graph lets Azure AD evaluate active user sessions in near real time and help IT revoke access to resources when events like device loss transpire.
We also recommend that developers use the Microsoft Authentication Libraries (MSAL) and choose modern protocols like OpenID Connect and OAuth2 to easily integrate with a great single sign-on experience and the latest innovations in identity. Also getting them publisher-verified will make it easier for customers and users to understand the authenticity of their applications. With Publisher Verification, developers can demonstrate that an application comes from a trusted publisher.
Second Zero Trust principle: Use least privileged access
According to this principle, apps and users should work with just the right amount of privileges and permissions needed to conduct their business. Some applications may be over-privileged, resulting in the blast radius being larger than it should be during a compromise.
One example is the types of permission an application requests to call Microsoft Graph, the gateway to a tremendous amount of data in Microsoft Cloud. Applications request and consent to permissions to access data in Microsoft Graph, and users or admins must grant consent. Hence, it is critical to use the principle of least privilege when integrating apps with Microsoft Graph. We recommend that developers use a tool like Graph Explorer to choose the least privilege permission for the API they plan to use. Developers can request additional permissions when an app needs them using the incremental consent feature.

Another capability developers can provide to IT by integrating their apps with the Microsoft identity platform is to define app roles, such as for administrators, readers or contributors. To help customers adhere to the principle of using least privilege access, it is critical to make apps be ready to use Azure AD’s Privileged Identity Management (PIM) feature. With PIM, IT can provide just-in-time and time-bound access to sensitive app roles.
Zero Trust principle 3: Assume breach
This principle encourages app developers to assume that users are accessing apps on open networks and that breaches can affect their applications.
To minimize the blast radius, we recommend that developers keep all key secrets and credentials out of their code. Instead, consider using Azure Key Vault and Managed identities for secret rotations. These tools let IT administrators remove or rotate secrets without taking the application down or redeploying the app. To enable this, developers need to move the secret to the Azure Key Vault and access them via Managed identities.
How to build Zero Trust-ready apps
To learn more, check out the new developer and ISV guidance we’ve published to the Zero Trust Resource Center. It includes new development and integration resources for developing Zero Trust-ready apps.
Join us virtually or live, or watch on-demand
No matter where you are in the world, you can join us at Build 2021. There are plenty of live and pre-recorded sessions. To register, attend, and interact with us during these sessions, see below:
Breakout sessions
- BRK234: Build a Zero Trust-ready app starting with the Microsoft identity platform.
- BRK244: Learn three new ways to enrich your productivity apps with Microsoft Graph tools and data.
Technical session
- TS04: Enable the next generation of productivity experiences for hybrid work.
Community connections
- Ask the Experts: Build a Zero Trust-ready app (3 PM PT on 5/26, 5 AM PT on 5/27).
- Ask the Experts: Build B2C apps with External Identities.
- Product roundtable: Use managed identities in Azure to securely connect to cloud services.
- 1:1 Consults: Meet with an expert on the Microsoft identity platform.
On-demand sessions
- Best practices to build secure B2C apps with Azure Active Directory External Identities.
- Down with sign-ups, just sign-in (Decentralized Identities)
Best regards,
Alex Simons (@Alex_A_Simons)
Corporate VP of Program Management
Microsoft Identity Division
Learn more about Microsoft identity:

Recent Comments