The Data Lakehouse, the Data Warehouse and a Modern Data platform architecture
This article is contributed. See the original author and article here.
I am encountering two overriding themes when talking to data architects today about their data and analytics strategy – which take very different sides, practically at the extreme ends of the discussion about the future design of the data platform.
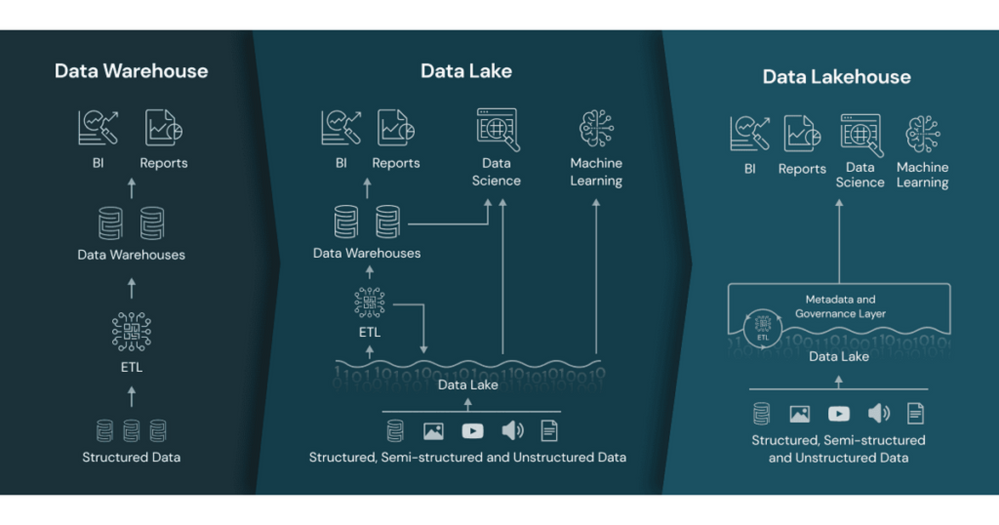
- The Data Lakehouse. The focus here is how traditional Data Lakes have now advanced so that the capabilities previously provided by the Data Warehouse can now be replicated within the Data Lake. The Data Lakehouse approach proposes using data structures and data management features in a data lake that are similar to those previously found in a data warehouse:
- Snowflake as your data platform. Snowflake has quickly become a major player in the data warehousing market, making use of its cloud native architecture to drive market share. They have taken this a step further now though and are now pushing the concept of “Make Snowflake Your Data Lake”

So on one-hand, the Data Lakehouse advocates says “There is no longer a need for a relational database, do it all in the data lake”, while Snowflake is saying “Build your data lake in a relational database”. Is there really such a stark divergence of views about how to architect a modern data platform?
While both of these architectures have some merit, a number of questions immediately spring to mind. Both of these are driven with a focus on a single technology – which immediately should ring alarm bells for any architect. Both concepts also bring baggage from the past:
- the Data Lakehouse pitch feels uncomfortably close to the “Hadoop can do it all” hype from 10 years ago, which led to vast sums being spent by organisations jumping onto this big data bandwagon; they believed the hype, invested huge amount of money into this wonder platform, only to find that it wasn’t as effective as it promised and that many of the problems with the “data warehouse” were actually due to their processes and governance that were simply replicated in the new technology.
- some of the Snowflake marketing seems to be morphing into similar concepts of the Enterprise Data Warehouse vendors of 20-30 years ago – the concept of a single data repository and technology being all you need for all your enterprise data needs – which follows a very legacy logical architecture for a product that so heavily hypes its modern physical architecture.
So how do we make sense of these competing patterns? Why is there such a big disparity between two approaches, and is there really such a major decision needed between open (spark/delta) v proprietary code (snowflake/relational) bases and repositories ? I believe that if you drill into the headline propositions, the reality is that any architecture isn’t an “either/or” but a “better together” and that a pragmatic approach should be taken. As such, whenever starting any conversation today, I tend to lead with three areas of assessment:
- What data do you have and what are your big data, BI and advanced analytical requirements? An organisation that requires mainly machine learning and anomaly detection against semi-structured data requires a very different approach to one that has more traditional BI and next best action needs driven from structured data. Also consider what works well for your data; if it is mostly structured and sourced from relational systems, why not keep it that way rather than putting it into a semi-structured form in a Lake and then layering structures back over the top; alternatively for semi-structured or constantly changing data, why force this into a relational environment that wasn’t designed for this type of data and which then requires the data to be exported out to the compute?
- What skills base do you have in IT and the business? If your workforce are relational experts and have great SQL skills, it could be a big shift for them to become Spark developers; alternatively if your key resources are teams of data scientists used to working in their tools of choice, they are unlikely to embrace a relational engine and will end up exporting all the data back out into their preferred environments.
- Azure – and any modern cloud ecosystem – is extremely flexible, it redefines the way modern compute architectures work by completely disconnecting compute and storage and provides the ability to build processes that use the right tool for the right job on a pay for what you use basis. The benefits are huge – workloads can be run much faster, more effectively and at massively reduced costs compared to “traditional” architectures, but it requires a real paradigm shift in thinking from IT architects and developers to think about using the right technology for the job and not just following their tried and tested approaches in one technology.
The responses to these 3 areas, especially 1 and 2, should determine the direction of any data platform architecture for your business. The concepts from item 3 should be front and centre for all architects and data platform decision makers though, as getting the best from your cloud investment requires new ways of thinking. What surprises me most today is that many people seem reticent to change their thinking to take advantage of these capabilities – often through a combination of not understanding what is possible, harking back to what they know, and of certain technology providers pushing the concept of “why do you need this complexity when you can do everything in one (our) tool”. While using multiple tools and technologies may seem like adding complexity if they don’t work well together, the capabilities of a well-integrated ecosystem will usually be easier to use and manage than trying to bend a single technology to do everything.
Why does Microsoft propose Azure Synapse Analytics in this area? We believe that this hybrid approach is the right way forward – that enabling efficient and effective BI, Analytics, ML and AI is possible when all your data assets are connected and managed in a cohesive fashion. A true Enterprise Data platform architecture enables better decisions and transformative processes, enabling a digital feedback loop within your organization and provide the foundation for successful analytics. One constant area of feedback we received from customers though was that while building a modern data platform was the right strategy, they wanted it to be easier to implement. IT architects and developers wanted to spend less time worrying about the plumbing – integrating the components, getting them to talk to each other – and more time building the solution. We thus set out to rearchitect and create the next generation of query processing and data management with Synapse to meet the needs of the modern, high scale, volume, velocity, and variety of data workloads. As opposed to limiting customers only to one engine, Synapse provides SQL, Spark, and Log Analytics engines within a single integrated development environment, a cloud-native analytics service engine that converges big data and data warehousing to achieve limitless scale on structured, semi-structured, and un-structured data. Purpose built engines optimized for different scenarios enable customers to yield more insights faster and with fewer resources and less cost.

Azure Synapse Analytics is a limitless analytics service with a unified experience to ingest, explore, prepare, manage and serve data for immediate BI and machine-learning needs. So Azure Synapse Analytics isn’t a single technology, but an integrated combination of the different tools and capabilities you need to build your modern data platform, allowing you to choose the right tool for each job/step/process while removing the complexity of integrating these tools.
While Synapse can provide this flexible modern data platform architecture in a single service, the concept is open. Synapse provides Spark and dedicated SQL pool engines, but alternatively Databricks and Snowflake could replace these components within this architecture. Alternatively any combination of Synapse, other first-party, third-party, or open-source components can be used to create the modern data platform, the vast majority of which are supported within Azure.
This open combination of individual technologies should be combined within a Modern Data platform architecture to give you the ability to build the right modern data platform for your business. Take advantage of the flexibility of Azure and use the best tools and techniques to construct the most effective data platform for your business.



Recent Comments