
by Contributed | Sep 23, 2020 | Azure, Technology, Uncategorized
This article is contributed. See the original author and article here.
Welcome to another release of the Azure CLI! In this release, we will be sharing with you the latest feature improvements that will help boost in tool productivity. This includes:
- A newly refined error messages that is more human readable and legible.
- A new in-tool upgrade mechanism so you no longer must leave the tool to keep every dependency in sync and intact.
- A way to remember contextual information between Az CLI commands. This helps reduce the command length by eliminating parameters that are repeated in sequential CLI commands.
- A new –query-examples option that provide you contextual JMES query recommendations to help you get started with command querying.
You can download the latest official release from the Azure CLI page or the dev build from the GitHub Azure CLI homepage
New human readable error outputs with AI powered recommendations:
When we talk to CLI customers, we often hear that understanding output errors is difficult.
As our first approach, we looked at client-side syntactical errors. We found that these are primarily caused by misspelling commands or typing in commands which do not exist for a particular resource. In partnership with our User Experience and Design teams we landed on a new 3 line output model of:
- What happened?
- Try this…
- Learn more…
We think that the additional information provided by ‘Try this’ and ‘Learn more’ can effectively guide you towards the correct commands and parameters.
In the screenshots below, you can see that the new error output is much cleaner and simpler; most importantly, it’s now human readable. In the case where the error message alone doesn’t provide sufficient context to unblock you on the issue, we hope you can leverage the follow up in tool recommendations that are made readily available to you:

Figure 1: Examples of new error output with contextual recommendations

Figure 2: Coming Soon: Prototype with better colorization and templating design
Convenient in tool az upgrade:
Az upgrade is another new feature that further enhances your in-tool convenience. The command name itself elaborates on what it does — enabling you to upgrade to the latest CLI version without having to leave the tool. To try it out, simply type in az upgrade in your terminal and the tool will auto-upgrade your core CLI version and all of your installed extensions to the latest version on your behalf, while checking and maintaining all the package dependencies.
Under the hood, az upgrade uses the package manager commands to perform the updates. Currently there are different commands you need to remember depending upon your operating system and package manager, for instance, sudo apt-get update && sudo apt-get install –only-upgrade -y azure-cli for deb packages on Ubuntu, sudo yum update azure-cli for RPM packages on CentOS, and brew update && brew upgrade azure-cli for homebrew packages on macOS. Now you can simply use a single az upgrade command regardless of the platform you are using the Azure CLI.

Figure 3: UX of the new in tool az upgrade
Once you are on the latest version of the Azure CLI, you can also enable automatic upgrade. To enable it simply apply the single configuration option via az config auto-upgrade.enable = yes. That way you’ll never have to worry about keeping up with the latest version of the tool. The Azure CLI will check new versions and prompt you with an update after any command finishes running once the update is available.
The prompt message and output messages during upgrade may interrupt your command result if it is assigned to some variable or in an automated flow. To avoid interruption, you can use az config auto-upgrade.prompt = no to allow the update to happen automatically without confirmation and only show warnings and errors during the upgrade. By default, all installed extensions will also be updated. You can disable extension update via az config auto-upgrade.all = no.
Note: Please wait for az upgrade to complete before proceeding to the next set of commands, else the new versions of the CLI (+extensions) may have breaking changes.
Advanced contextual support with az config param-persist:
We recently released a new way to set configuration options so that it’d be simpler and more intuitive as you work with the tool. We further extended its capabilities with yet another experimental feature named az config param-persist. Similar to how one could use the basic config/configure commands to set global static defaults, az config param-persist is a specific configurable mode that implicitly sets defaults in your current working directory for which the values would persist – this eliminates the need for you to re-specify arguments in CLI commands once they’ve been declared. Below is a before vs. after feature comparison:

Figure 4: before & after view of az config param-persist
With param-persist enabled on the right, we can see that once the values of resource group, location, and storage account have been specified in previous commands, they can now be omitted from subsequent commands, thereby reducing the number of potential error points when you interact with the tool. We currently support param-persist on a core set of parameters including resource group and vnet across all services as well as location, resource name, storage account support on functions and webapp. If you’re interested in helping us shape its future outlook – whether it be command naming, feature coverage, additional capabilities, and such; please do not hesitate to share your feedback here.
Helping you get started with JMES with –query-examples
The Azure CLI supports a mechanism to return specific fields out of the returned JSON object. This uses JMESPath to specify the query. While powerful, these queries can be complicated to write. Our last improvement is a new contextual –query-examples capabilities. This is a flag that could be appended to any az <resource> show or list commands for list of JMES query recommendations. This includes examples to query for a specific key, filter the output based on a set of conditions, and query for a set of commonly used functions. When you come across a specific query of interest, please be sure to wrap them in the double quotation marks (“ ”) and append them after the –query flag when performing the actual query. Below are some examples in action:

Figure 5: Example usage of –query-examples with az group list

Figure 6: Example of filtering/limiting recommendations that contain the texts ostype or resourcegroup
Once again, you can further config it with az config to i) limit the max num of inline recommendations with az config set query.max_examples; and ii) define the max length of help string and query string with az config set query.help_len and az config set query.examples_len.
One thing to note: –query and –query-examples provide 2 distinct functionalities. –query enables you to filter for specific info on the command output whereas –query-examples provide you contextual query recommendations. This is an experimental feature and we would love your feedback here.
Follow up with us
We’d love for you to try out these new experiences and share your feedback on their usability and applicability for your day-to-day use cases. All of the above features are here to lower your in tool friction and improve your productivity. If you’re interested, here is where you can learn more about new features in the ever improving Azure CLI.
Thank you
The CLI team
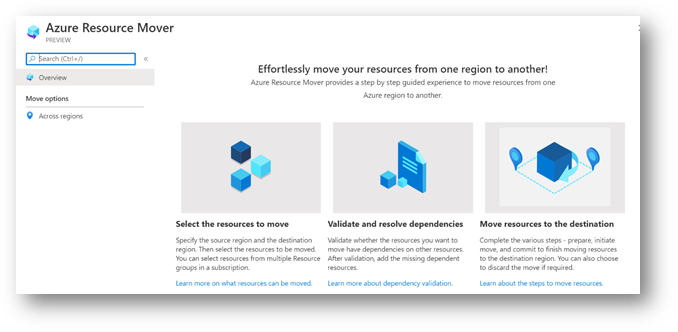
by Contributed | Sep 23, 2020 | Azure, Technology, Uncategorized
This article is contributed. See the original author and article here.
With over 60+ announced Azure regions across the world, more than any other cloud provider, we aim to provide customers with options to select the region that best suits their needs – whether that need is based on data residency or compliance requirements, service offerings, technical and regulatory considerations, or just being closer to their customers. As we increase the number of new regions across the globe, and expand resiliency options with new Azure Availability Zones, we recognize the need to provide customers with the ability to move their IT resources to regions of their choice.
At Microsoft Ignite this week, we are announcing Azure Resource Mover, a new free service in preview that enables customers to move multiple resources across public Azure regions to support their ever-evolving business needs. Azure Resource Mover greatly reduces customer time and effort needed to move resources across regions by providing a built-in dependency analysis, planning, and testing that ensures the resources are prepared to move and then successfully moved to the desired region. Azure Resource Mover also provides a seamless and consistent single pane of glass experience that allows move orchestration for a range of Azure resources (Azure VMs, Azure Virtual Network, Azure SQL DBs etc.).
“The automation and single-click move capability of the Azure Resource Mover allowed us to significantly reduce the time and effort needed to move IT resources across regions,” said Adam Iqbal, capital markets Azure project lead at Accenture. “The ability to rename resources and customize IP addresses in the target location are other important features that helped to streamline and simplify the process.”
Azure Resource Mover, available through the Azure portal, PowerShell, and SDKs with any Azure subscription, can be used to support a number of key business needs such as:
- Take advantage of new Azure region expansions to be closer to their end customers to reduce latency
- Increase availability and resiliency of their applications by moving to regions with Azure Availability Zones
- Meet the data residency and compliance requirements necessary for operating their businesses
- Consolidate workloads into single regions to support mergers and acquisitions
Over the last year we have announced new datacenter regions in Qatar, Israel, Mexico, Spain, Poland, Italy, New Zealand and our latest addition in the United States with West US 3 in Arizona. With Azure Resource Mover, customers have the ability to plan ahead and take advantage of these new regions whether that is to meet compliance or data residency requirements or better serve their customers.

Moving between Azure regions with confidence
Azure Resource Mover streamlines the move process by identifying and analyzing any dependencies needed to plan the move. Customers can plan and test ahead as many times as needed so that when fully prepared, the move can be staged to happen during a planned scheduled downtime event. This enables customers to have full confidence when planning large scale moves.
Customers can rest assured that all moves are orchestrated within the highly secure and encrypted Azure environment and Azure Resource Mover provides the user with the validation that the move is final prior to committing the move to the target region. The resources at the source region are left intact until the final move is completed so customers.
Moving multiple resources simultaneously through a single pane of glass that abstracts the underlying technology elements and following a consistent experience significantly reduces touchpoints, so there is less time spent learning various required for the move and can reduce overall time for the move from months to weeks or days depending on amount of data.
We continue to hear from customers of the importance of having the flexibility to take advantage of Azure regions. We have designed Azure Resource Mover with customer feedback and experience in mind and invite customers to learn more about Azure Resource Mover here and leverage our technical documentation on how to get started. Azure Resource Mover currently supports moving resources from any public region to any other public region. The support to move across sovereign clouds will be available in the coming months.
by Contributed | Sep 23, 2020 | Azure, Technology, Uncategorized
This article is contributed. See the original author and article here.
Today, we are proud to announce the public preview of the Azure Schema Registry in Azure Event Hubs.
In many event streaming and messaging scenarios, the event/message payload contains structured data that is either being de-/serialized using a schema-driven format like Apache Avro and/or where both communicating parties want to validate the integrity of the data with a schema document as with JSON Schema.
For schema-driven formats, making the schema available to the message consumer is a prerequisite for the consumer being able to deserialize the data, at all.
The Azure Schema Registry that we are offering in public preview as a feature of Event Hubs provides a central repository for schema documents for event-driven and messaging-centric applications, and enables applications to adhere to a contract and flexibly interact with each other. The Schema Registry also provides a simple governance framework for reusable schemas and defines the relationship between schemas through a grouping construct.
With schema-driven serialization frameworks like Apache Avro, externalizing serialization metadata into shared schemas can also help to dramatically reduce the per-message overhead of type information and field names included with every data set as it is the case with tagged formats such as JSON. Having schemas stored alongside the events and inside the eventing infrastructure ensures that the metadata required for de-/serialization is always in reach and schemas cannot be misplaced.
What do I need to know about the Azure Schema Registry support in Event Hubs?
Event Hubs adds the new schema registry support as a new feature of every Event Hubs Standard namespace and in Event Hubs Dedicated.
Inside the namespace, you can now manage “schema groups” alongside the Event Hub instances (“topics” in Apache Kafka® API parlance). Each of these schema groups is a separately securable repository for a set of schemas. Schema groups can be aligned with a particular application or an organizational unit.
The security boundary imposed by the grouping mechanism help ensures that trade secrets do not inadvertently leak through metadata in situations where the namespace is shared amongst multiple partners. It also allows for application owners to manage schemas independent of other applications that share the same namespace.
Each schema group can hold multiple schemas, each with a version history. The compatibility enforcement feature which can help ensure that newer schema versions are backwards compatible can be set at the group level as a policy for all schemas in the group.
An Event Hubs Standard namespace can host 1 schema group and 25 schemas for this public preview. Event Hubs Dedicated can already host 1000 schema groups and 10000 schemas.
In spite of being hosted inside of Azure Event Hubs, the schema registry can be used universally with all Azure messaging services and any other message or events broker.
For the public preview, we provide SDKs for Java, .NET, Python, and Node/JS that can de-/serialize payloads using the Apache Avro format from and to byte streams/arrays and can be combined with any messaging and eventing service client. We will add further serialization formats with general availability of the service.
The Java client’s Apache Kafka client serializer for the Azure Schema Registry can be used in any Apache Kafka® scenario and with any Apache Kafka® based deployment or cloud service.
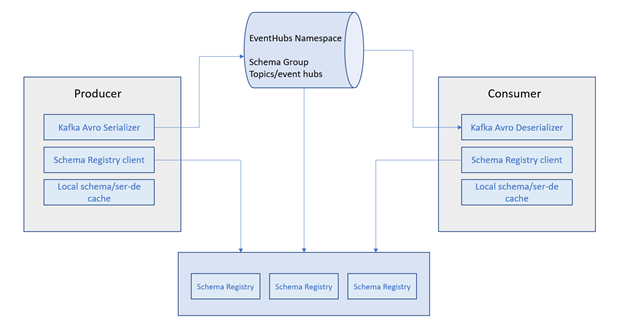
The figure below shows the information flow of the schema registry with Event Hubs using the Apache Kafka® serializer as an example:
 Azure Schema Registry
Azure Schema Registry
How does the Azure Schema Registry integrate with my application?
First, you need to create an Event Hubs namespace, create a schema group, and seed the group with a schema. This can either be done through the Azure portal or through a command line client, but the producer client can also dynamically submit a schema. These steps are explained in detail in our documentation overview.
If use Apache Kafka® with the Java client today and you are already using a schema-registry backed serializer, you will find that it’s trivial to switch to the Azure Schema Registry’s Avro serializer and just by modifying the client configuration:
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
com.microsoft.azure.schemaregistry.kafka.avro.KafkaAvroSerializer.class);
props.put("schema.registry.url", azureSchemaRegistryEndpoint);
props.put("schema.registry.credential", azureIdentityTokenCredential);
You can then use the familiar, strongly typed serialization experience for sending records and schemas will be registered and made available to the consumers as you expect:
KafkaProducer<String, Employee> producer =
new KafkaProducer<String, Employee>(props);
producer.send(new ProducerRecord<>(topic, key, new Employee(name)));
The Avro serializers for all Azure SDK languages implement the same base class or pattern that is used for serialization throughout the SDK and can therefore be used with all Azure SDK clients that already have or will offer object serialization extensibility.
The serializer interface turns structured data into a byte stream (or byte array) and back. It can therefore be used anywhere and with any framework or service. Here is a snippet that uses the serializer with automatic schema registration in C#:
var employee = new Employee { Age = 42, Name = "John Doe" };
string groupName = "<schema_group_name>";
using var memoryStream = new MemoryStream();
var serializer = new SchemaRegistryAvroObjectSerializer(client, groupName, new SchemaRegistryAvroObjectSerializerOptions { AutoRegisterSchemas = true });
serializer.Serialize(memoryStream, employee, typeof(Employee), CancellationToken.None);
Open Standards
Even through schema registries are increasingly popular, there has so far been no open and vendor-neutral standard for a lightweight interface optimized for this use-case.
The most popular registry for Apache Kafka® is external to the Kafka project and vendor-proprietary, and even though it still appears to be open source, the vendor has switched the license from the Apache license to a restrictive license that dramatically limits who can touch the code, and to run the registry in a managed cloud environment. Cloud customers are locked hard into that vendor’s cloud offering, in spite of the open-source “community” façade.
Just as with our commitments to open messaging and eventing standards like AMQP, MQTT, JMS 2.0 and CloudEvents, we believe that application code that depends on a schema registry should be agile across products and environments and that customer should be able to use the same client code and protocol even if the schema registry implementation differs.
Therefore, Microsoft has submitted the interface of the Azure Schema Registry to the Cloud Native Foundation‘s “CloudEvents” project in June 2020.
The purpose of the submission is the joint standardization in the CloudEvents Working Group (WG) to ensure that the same interface can be implemented by many vendors and that clients can uniformly access their “nearest” schema registry, because the CloudEvents WG exists to jointly develop interoperable federations of eventing infrastructure. The schema registry interface is not restricted to or in any way dependent on the CloudEvents specification, but in the other direction, the CloudEvents dataschema and datacontenttype attributes already anticipate the use of a schema registry for payload encoding.
The schema registry definition in CNCF CloudEvents is expected to still evolve in the working group, and we are committed to providing a compliant implementation with the 1.0 release within a short time of it becoming final.
Notes:
- The Schema Registry feature is currently in preview and is available only in standard and dedicated tiers, not in the basic tier.
- This preview is initially available in the West Central US region and is expected to be available in all other global regions by September 29, 2020.
Next Steps
Learn more about the Azure Schema Registry in Event Hubs in the documentation.
by Contributed | Sep 23, 2020 | Azure, Technology, Uncategorized
This article is contributed. See the original author and article here.
Running SQL Server on Azure Virtual Machines provides a suite of free manageability capabilities that are available only on Azure, and which make it easier to run in a cost effective, secured and optimized manner. Microsoft introduced the Azure SQL family of database services to provide customers with a consistent, unified experience across an entire SQL portfolio and a full range of deployment options from edge to cloud. As a SQL Server customer, you can migrate your SQL workloads to SQL Server on Azure Virtual Machines while making the most of your current SQL Server license investments and benefit from the manageability benefits that SQL Server virtual machines offer today. Running SQL Server on an Azure virtual machine provides the best lift-and-shift experience for workloads where OS-level access is required.
A SQL Server instance on an Azure Virtual Machine is the cloud equivalent of an on-premises SQL Server, running your mission critical applications on Azure. Azure offers unique Windows Server and SQL Server licensing benefits through Azure Hybrid Benefit, giving you the ability to run the same SQL Server with a better total cost of ownership (TCO), with low effort and great performance. Azure also offers that ability for you to automatically manage your Windows Servers using our recently announced Azure Automanage preview offering. Read more about it here.
How can you leverage these benefits?
All of the security, manageability and cost-optimization benefits mentioned above are enabled through the SQL Server IaaS Agent Extension. To ensure that you’re receiving full manageability benefits, this extension can be installed on a SQL Server virtual machine that is already running or any new SQL Server virtual machine that you create in the future.
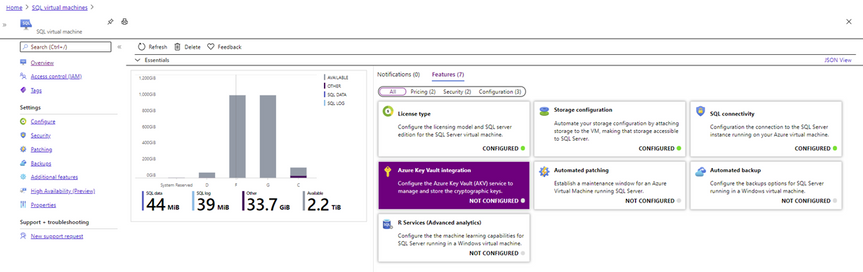
The screenshot below shows the different manageability options that are enabled when the SQL Server IaaS extension is enabled.
 SQL IaaS Extension Capabilities
SQL IaaS Extension Capabilities
Optimize Cost
The SQL Server IaaS extension enables administrators to reduce cost and manage inventory with less effort. There are a number of cost optimization capabilities that a SQL Server administrator can leverage with SQL Server virtual machines which are made possible through our “License type” feature. As an administrator, you will have the ability to:
- See all your SQL Server virtual machine deployments in a single dashboard to make inventory management easier
- Get a snapshot of how many SQL Server on Azure Virtual Machines are leveraging Azure Hybrid Benefit
- Switch between Pay-as-you-go and Azure Hybrid Benefit licensing models to optimize the use of your licenses in the cloud
- Leverage FREE passive SQL Server core benefits that enable using Azure as a Disaster Recovery site for your on-premises SQL Server at no additional license cost for customers with Software Assurance or SQL Server subscription licenses
- Leverage FREE passive SQL Server core benefits for High Availability and Disaster Recovery scenarios for primary replicas hosted in Azure for customers with Software Assurance or SQL Server subscription licenses
- Run SQL Server Reporting Services virtual machines with Pay-as-you-go licensing or Azure Hybrid Benefits
The License type for a SQL Server virtual machine provides three options: Pay As You Go, Azure Hybrid Benefit and Disaster Recovery (as seen in the screenshot below). The Disaster Recovery toggle gives you the ability to leverage the free Disaster Recovery license type benefit without having to track the deployments separately, making license management and inventory a lot easier.
 Configure hybrid DR using free SQL Server VM licenses
Configure hybrid DR using free SQL Server VM licenses
This benefit applies to all releases of SQL Server starting from SQL Server 2008 to SQL Server 2019 as long as you are using licenses covered with Software Assurance or subscription licenses. You can learn more about these benefits here.
As a SQL Server user, you will have the ability in the near future to deploy a SQL Server Reporting Services virtual machine for your BI reporting requirements and also leverage a flexible licensing model through Pay-as-you-go and Azure Hybrid Benefit licensing. Also, you can deploy your Power BI Report Server virtual machines with Azure Hybrid Benefit licenses which makes it easier to rehost your relational and reporting workloads into Azure.
Enhance Security
Security is a key area of interest for any database administrator who is responsible for securing and protecting business data stored in a SQL Server database. Sometimes compliance requirements drive security needs like encryption of data at rest. SQL Server on Azure Virtual Machines make security management easier through patching and easily implement encryption features for better security and compliance.
The Automated Patching feature allows a SQL Server administrator to select a maintenance window schedule for applying Important Windows Server and SQL Server updates that are distributed through the Windows Update channel. You have the ability to select the maintenance window duration and the start of the window.
 Patch your Azure SQL VM using scheduled windows
Patch your Azure SQL VM using scheduled windows
The SQL connectivity feature allows you to do the following:
- Set the port for the SQL Server instance to ensure that you are able to listen on another port other than a well-known port.
- Configure the connectivity rules to make it as restrictive like allowing local connectivity only or opening it up to public internet for external applications and clients to connect to the SQL Server instance (see screenshot below).
- Enable SQL Authentication for the SQL Server instance if your applications and users require this authentication method.
- Configure Azure Key Vault for the SQL Server instance to leverage Key Vault for Transparent Database Encryption, Column Level Encryption and Always Encrypted features of SQL Server to enable encryption of data at rest and in motion.
Increase Uptime
SQL Server virtual machines provide various management capabilities to make configuration of the environment a lot easier for business continuity and disaster recovery scenarios.
The new High Availability feature allows you to create a new cluster or onboard an existing cluster, and then create the availability group, listener, and internal load balancer.
 Configure High Availability easily with Azure SQL VM
Configure High Availability easily with Azure SQL VM
Additionally, SQL Server on Azure Virtual Machines also help you reduce your cost of deploying a highly available environment if you have Software Assurance or you are using SQL Server subscription licenses. Let us consider an example where you were running a SQL Server virtual machine topology having one primary replica, one synchronous passive secondary replica and one asynchronous passive replica. You would need to license only the primary replica. It is assumed that the number of cores on all three replicas are the same. The example below uses Always On Availability Group as the High Availability and Disaster Recovery feature, but you can leverage this benefit with other SQL Server features like Failover Cluster Instances, Log Shipping, Database Mirroring and Backup and Restore. More details available here.
The Automated Backup feature allows you to setup SQL Server backups with various options like encrypting backups, set a retention period, backup system databases, configuring a manual backup schedule or setting up an automated backup. This is great for SQL Server virtual machines where you don’t want to attach a backup software but just backup all the databases on the instance to support point-in-time restore for creating copies of the database environment or to recover from user errors.
Manageability
SQL Server on Azure Virtual Machines provides a number of free manageability benefits which make administration tasks for a SQL Server instance a lot easier. In addition to that a number of best practices are surfaced through the wizards to make SQL Server virtual machines run with the most optimal configurations.
SQL Server on Azure Virtual Machines provides the ability to simplify storage configuration while setting up the virtual machine through the use of pre-configured storage profiles as seen in the screenshot below. This ensures that you are picking the right storage configuration for your data, log and tempdb files. You can read more about it here.
 Configure storage settings for your Azure SQL VM
Configure storage settings for your Azure SQL VM
Once the SQL Server virtual machine is running, you have the option of increasing the storage capacity of your disks and the wizard will help you determine if you are picking a configuration setting which could be the victim of a capacity limit (see highlighted section in screenshot below).
 Configure your storage settings on Azure SQL VM
Configure your storage settings on Azure SQL VM
You also have the ability to manage your SQL Server virtual machines through the SQL Server IaaS extension through the use of Azure CLI or PowerShell. Azure Runbooks or Azure Automation scripts can be created to leverage these benefits at scale across a fleet of SQL Server virtual machines.
If you leverage in-database Machine Learning for your SQL Server instances, SQL Server virtual machines provide the ability to configuring advanced analytics for your instance.
Next Steps
Running SQL Server in an Azure virtual machine gives you the same capabilities and experience you are used to with on-premises SQL Server, plus the additional ease of use and management benefits available only on Azure. Ensure that your virtual machines are running the SQL Server IaaS Extension to enable all these benefits, and check out the following links for more information about running SQL Server in Azure virtual machines.
by Scott Muniz | Sep 23, 2020 | Azure, Technology, Uncategorized
This article is contributed. See the original author and article here.
Azure Synapse Analytics brings the worlds of data integration, big data, and enterprise data warehousing together into a single service for end-to-end analytics, at cloud scale. This week at Microsoft Ignite we announced several features that bring accelerated time to insight via new built-in capabilities for both data exploration and data warehousing.
As we dive into each new feature, we will use the terminology below to identify where the feature is applicable. For the SQL capabilities in Azure Synapse Analytics, the main resource used is called a SQL pool. This resource has two consumption models: serverless and dedicated. The serverless model provides transparent compute consumption and is billed per data processed. The dedicated model allows use of dedicated compute, comes with capacity model and is billed per DWU-consumed. This new terminology will appear in the product soon.

Accelerate time to insight with:
-
Power BI performance accelerator for Azure Synapse Analytics (private preview)
Last year when we announced Azure Synapse Analytics, we promised to bring Microsoft’s data and BI capabilities together to deliver optimized experiences for our users. Today, we continue expanding on that promise with the announcement of the Power BI performance accelerator for Azure Synapse Analytics, a new self-managed process that enables automatic performance tuning for workloads and queries ran in Power BI.
As Power BI users run their queries and reports, the performance accelerator monitors those queries behind the scenes and optimizes their execution thus significantly improving query response times over the latest data. It analyzes all Power BI queries holistically and intelligently creates materialized views within the SQL engine while recognizing common query joins and aggregations patterns. As Power BI queries continue to execute, queries are automatically sped up and users observe increased query performance leading to quicker business insights. With new data being ingested into SQL tables, materialized views are automatically refreshed and maintained. Best of all, as more and more queries are being executed, the performance accelerator optimizes and adjusts the deployed materialized views to fine tune view design, all while reducing query execution times.
This feature can be enabled with a few clicks within the Synapse Studio. You can simply choose the frequency for executing the process and set the maximum storage to manage the size of the system-generated materialized views and it’s ready to start optimizing your Power BI workload.

The Power BI performance accelerator for Azure Synapse Analytics delivers a zero-management experience. It helps system administrators manage materialized views while allowing Power BI users to gain quick and up-to-date business insights.
This feature applies to dedicated model. To participate, submit your request here.
-
Azure Synapse Link for Azure Cosmos DB now includes Synapse SQL (public preview)
Azure Synapse Link connects operational data stores with high performance analytics engines in Azure Synapse Analytics. Using Synapse Link, customers can perform near real-time analytics directly over their data managed in Azure Cosmos DB without impacting the performance of their operational workloads.
Today, we are announcing the public preview of Azure Synapse Link for Azure Cosmos DB using Synapse SQL. This functionality is now available to all customers and is deployed worldwide. Customers can now use a serverless SQL pool in Azure Synapse Analytics to perform interactive analytics over Azure Cosmos DB data enabling quick insights and exploratory analysis without the need to employ complex data movement steps. Thanks to the rich T-SQL support for analytical queries and automatic schema discovery for data, it has never been easier to explore operational data by running ad-hoc and advanced analytical queries. Best of all, due to the rich and out-of-the-box ecosystem support, tools such as Power BI – and others – are just a few clicks away.

This feature applies to serverless model. To learn more, visit the Azure Synapse Link for Azure Cosmos DB documentation.
Note: this functionality will become available in the next few weeks.
-
Enhanced support for analyzing text delimited files (public preview)
Despite the availability and popularity of columnar file formats optimized for analytics, such as Parquet and ORC, most newly generated and legacy data is still in text delimited formats. With this in in mind, we are continuously improving the experience for delimited text data. To support immediate and interactive data exploration for this text data, the following enhancements are being introduced:
– Fast parser: The new delimited text parser (CSV version 2.0) provides significant performance improvement, ranging from 2X (querying smaller files) to up to 10X or more (querying larger files). This new performance improvement, based on novel parsing techniques and multi-threading, is available to all existing and newly provisioned Azure Synapse workspaces.
– Automatic schema discovery: With automatic schema discovery, OPENROWSET function can be used with CSV files without a need to define expected schema. As the system automatically derives the schema based on the data being queried, users can focus on the needed data insights leading to faster and easier data exploration.
– Transform as CSV: We have extended support for the CREATE EXTERNAL TABLE AS SELECT statement to enable storing query results in the delimited text format. This functionality enables multi-stage data transformation to be performed while keeping the data in delimited text format throughout its lifecycle.

This feature applies to serverless model. To learn more, visit the Azure Synapse SQL documentation.
Improve data loading performance and ease of use with:
-
COPY command (Generally Available)
Loading data into your data warehouse may not always be the easiest task. Defining the proper table structure to host your data, data quality problems, handling incorrect data and errors, and ingestion performance are among some of the typical issues customers face. We designed the COPY command to tackle these problems. The COPY command has become the default utility for loading data into data warehouses within Azure Synapse Analytics. In addition to bringing the COPY command into General Availability state, we have also added the following features:
– Automatic schema discovery: The whole process of defining and mapping source data into target tables is a cumbersome process, especially when tables contain large numbers of columns. To help with this, we are introducing built-in auto-schema discovery and an auto-table creation process (auto_create_table option in preview within COPY). When used, the system automatically creates the target table based on the schema of the Parquet files.
– Complex data type support: COPY command now supports loading complex data types stored in Parquet files which eliminates the previous need to manage multiple computes. When used together with the automatic schema discovery option, complex data types will automatically be mapped to nvarchar columns.
These new functionalities are also supported in partner products as well. Azure Stream Analytics, Azure Databricks, Informatica, Matillion, Fivetran, and Talend are among the products and services that support the new COPY command.
This feature applies to dedicated model. To learn more, visit the COPY documentation.
-
Fast streaming ingestion (Generally Available)
With the rise of IoT devices, both the amount and velocity of the data produced has increased dramatically. To make that data available for analysis and to reduce the time it takes to load and query this data within your data warehouse environments, we are announcing the General Availability of high throughput streaming data ingestion (and inline analytics) to dedicated SQL pools in Azure Synapse using Azure Stream Analytics. This new connector can handle ingestion rates exceeding 200MB/sec while ensuring very low latencies.
With Azure Stream Analytics, in addition to high throughput ingress, customers can use SQL to run in-line analytics such as JOINs, temporal aggregations, filtering, real-time time inferencing with pre-trained ML models, pattern matching, geospatial analytics and much more. It supports common formats such as JSON, and custom de-serialization capabilities to ingress and analyze any custom or binary streaming data formats. More details can be found in the announcement blog.
This feature applies to dedicated model. To learn more about high throughput streaming ingestion, visit our documentation.
Secure your sensitive data using:
-
Column-level Encryption (public preview)
As data gets moved to the cloud, securing your data assets is critical to building trust with your customers and partners. Azure Synapse Analytics already provides a breadth of options that can be used to handle sensitive data in a secure manner. We are expanding that support with the introduction of Column Level Encryption.
Column-level encryption (CLE) helps you implement fine-grained protection of sensitive data within a table (server-side encryption). With CLE, customers gain the ability to use different protection keys for different columns in a table, with each key having its own access permissions. The data in CLE-enforced columns is encrypted on disk, and remains encrypted in memory, until the DECRYPTBYKEY function is used to decrypt it. Azure Synapse Analytics supports using both symmetric and asymmetric keys.
This feature applies to dedicated model. To learn more, visit the Column Level Encryption documentation.
Improve productivity with expanded T-SQL support:
-
MERGE support (public preview)
During data loading processes, often there is a need to transform, prepare, and consolidate data from different and disparate data sources into a target table. Depending on the desired table state, data needs to be either inserted, updated, or deleted. Previously, this process could have been implemented using the supported T-SQL dialect. However, the process required multiple queries to be used which was costly and error prone. With the new MERGE support, Azure Synapse Analytics now addresses this need. Users can now synchronize two tables in a single step, streamlining the data processing using a single step statement while improving code readability and debugging.
This feature applies to dedicated model. For more details, see our MERGE documentation.
Note: this functionality will become available in the next few weeks.
-
Stored procedures support (public preview)
Stored procedures have long been a popular method for encapsulating data processing logic and storing it in a database. To enable customers to operationalize their SQL transformation logic over the data residing in their data lakes, we have added stored procedures support to our serverless model. These data transformation steps can easily be embedded when doing data ingestion with Azure Synapse, and other tools, for repeatable and reliable execution.
This feature applies to serverless model.
Note: this functionality will become available in the next few weeks.
-
Inline Table-Valued Functions (public preview)
Views have long been the go-to method for returning queryable table results in T-SQL. However, views do not provide the ability to parameterize their definitions. While user-defined functions (UDFs) offer the power to customize results based on arguments, only those that return scalar values had been available in Synapse SQL. By extending support for inline table-valued functions (TVFs), users can now return a table result set based on specified parameters. Query these results just as you would any table and alter its definition as you would a scalar-valued function.
This feature applies to both serverless and dedicated models. For more details, visit the CREATE FUNCTION documentation.
Note: this functionality will become available in the next few weeks, post deployment.
Try Azure Synapse Analytics today
by Contributed | Sep 23, 2020 | Azure, Technology, Uncategorized
This article is contributed. See the original author and article here.
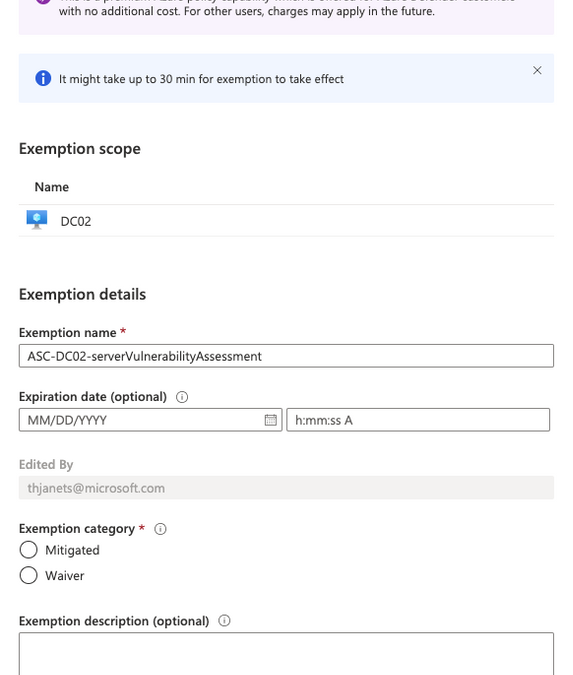
Resource exemption will allow increased granularity for you to fine-tune recommendations by providing the ability to exempt certain resources from evaluation. With Azure Security Center’s Cloud Security Posture Management (CSPM) capabilities, we are offering a broad set of recommendations and security controls, that might be relevant for most, but not all customers. The only way to remove recommendations from the ASC dashboard and prevent them from influencing your Secure Score was to disable the whole related policy in the Azure Security Center Policy Initiative. That way, all resources were affected, meaning that once you switched off a policy, the particular recommendation that was derived from it, was never shown again for any resource. Now, with the new resource exemption capability, you can select which resource should no longer be evaluated against a particular recommendation, whereas others still are. It allows you to exempt a resource in case the resource is already healthy because it was resolved by other means that ASC does not identify, or because you’ve decided to accept the risk of not mitigating this recommendation for this resource.you have research and development environments for which you want to apply a not-so-strict baseline, whereas the rest of resources in the same subscriptions need to be fully protected. These are great examples for exempting these resources from evaluation with waiver as justification, whereas your production environments are still protected. Maybe you have a mix of Vulnerability Assessment solutions in your environment, some of which are not tracked by Azure Security Center. In this scenario, respective recommendation has already been remediated, and you can now create an exemption for these resources and select mitigated as justification.
 Figure 1 – Create exemption blade
Figure 1 – Create exemption blade
Our goal is to reduce alert-fatigue so that security analysts can focus on the highest priority recommendations. As a result, your secure score will not be impacted by exempted resources.
How does it work?
The process for exempting a resource from a recommendation is straightforward and explained in our official documentation. Basically, when working with a recommendation, you just have to click the ellipsis menu on the right side and then select create exemption.
 Figure 2 – Create exemption
Figure 2 – Create exemption
From a technical perspective, when you create a resource exemption, the status of the particular assessment (the evaluation of a particular resource against a given recommendation) is changed. The properties of the assessment will contain the status code “NotApplicable”, the cause “Exempt” and a description, as shown in the screenshot below.
 Figure 3 – Assessment status after creating a resource exemption
Figure 3 – Assessment status after creating a resource exemption
At the same time, creating a resource exemption in ASC will create an Azure Policy exemption, a new capability the resource exemption feature in ASC relies on. That said, there are several ways to programmatically work with resource exemptions.
Resource exemption and automation
Knowing that an assessment is changed, and a new policy exemption is created every time you create a resource exemption in ASC, you have several ways of programmatically interacting with the resource exemption feature.
Azure Resource Graph
Assessments in Azure Security Center are continuously exported to Azure Resource Graph, giving you a great starting point for automation. ARG is a database that keeps a set of information which is gathered from different resources, giving you a very fast option to query information instead of separately pulling it from our REST APIs. Eli Koreh showed in his article how easy it is to create custom dashboards for ASC powered by ARG. You can find a list of starter query samples for Azure Resource Graph in the documentation.
To give you an idea of how to work with resource exemption in an ARG query, I’ve created the following sample, that will return a list of all resource exemptions that have been created in your environment:
SecurityResources
| where type == 'microsoft.security/assessments' and properties.status.cause == 'Exempt'
| extend assessmentKey = name, resourceId = tolower(trim(' ',tostring(properties.resourceDetails.Id))), healthStatus = properties.status.code, cause = properties.status.cause, reason = properties.status.description, displayName = properties.displayName
| project assessmentKey, id, name, displayName, resourceId, healthStatus, cause, reason
You can tune that query according to your needs, but it’s great as is for a quick overview on all exemptions you have created in your environment.
Resource Exemption and REST API
When a resource exemption in ASC is created, an exemption in the ASC Policy Initiative assignment is created. This is why you can leverage the Microsoft.Authorization/policyExemptions API to query for existing exemptions. This API is available as of version 2020-07-01-preview.
A GET call against the REST URI https://management.azure.com/subscriptions/<your sub ID>/providers/Microsoft.Authorization/policyExemptions?api-version=2020-07-01-preview will return all exemptions that have been created for a particular subscription, similar to the output shown below:
{
"value": [
{
"properties": {
"policyAssignmentId": "/subscriptions/<yourSubID>/providers/Microsoft.Authorization/policyAssignments/SecurityCenterBuiltIn",
"policyDefinitionReferenceIds": [
"diskEncryptionMonitoring"
],
"exemptionCategory": "waiver",
"displayName": "ASC-vmName-diskEncryptionMonitoring-BuiltIn",
"description": "demo justification",
"expiresOn": "2020-09-22T22:00:00Z"
},
"systemData": {
"createdBy": "someone@company.com",
"createdByType": "User",
"createdAt": "2020-09-22T09:27:23.7962656Z",
"lastModifiedBy": "someone@company.com",
"lastModifiedByType": "User",
"lastModifiedAt": "2020-09-22T09:27:23.7962656Z"
},
"id": "/subscriptions/<yourSubID>/resourceGroups/<yourRG>/providers/Microsoft.Compute/virtualMachines/<vmName>/providers/Microsoft.Authorization/policyExemptions/ASC-vmName-diskEncryptionMonitoring-BuiltIn",
"type": "Microsoft.Authorization/policyExemptions",
"name": "ASC-vmName-diskEncryptionMonitoring-BuiltIn"
}
]
}
You can find further information about Policy Exemptions in the Azure Policy documentation.
(Workflow) automation with Logic Apps
Azure Security Center’s workflow automation feature is great for both, automatically reacting on alerts and recommendations, as well as manually triggering an automation in case you need it. I have created a sample playbook to request a resource exemption, that I want to explain a bit further below:
Request a resource exemption
In order to be able to create a resource exemption in ASC, your user account needs to be granted elevated access rights, such as Security Admin. In enterprise environments that we are working with, we often see that Azure subscriptions are given to people who are responsible for their own set of resources, but security is still owned by a central team. In this scenario, you don’t want to necessarily give every resource owner the right to create a resource exemption, but still, for justified reasons, someone should be allowed to request an exemption. To make this process easier and to fit it into your approval process, I’ve created a Logic App that can manually be triggered from the recommendation blade and allows you to request an exemption. Once a resource owner is checking recommendations and wants to exempt a resource, they can do it by clicking the Trigger Logic App button. The screenshot below shows the easy process:
 Figure 4 – Request resource exemption process
Figure 4 – Request resource exemption process
- Select one or several resources to be exempted from the recommendation you are currently investigating.
- Click the Trigger Logic App button
- Select the Request-ResourceExemption Logic App (or whatever name you give it when deploying it)
- Click the Trigger button
The Logic App leverages the When an ASC recommendation is created or triggered trigger and will then send an email and a Teams message to the subscription’s security contact(s). This email and message will contain information about the resource, the recommendation, and a link that, once clicked, will lead you directly to a portal view that enables you to immediately create the requested resource exemption. You can find this playbook in our Azure Security Center GitHub repository, from where you can one-click deploy it to your environment.
 Figure 5 – content of the request email
Figure 5 – content of the request email
You can also use this sample playbook as a starting point for customizations according to your needs. For example, if you want to create a ServiceNow or JIRA ticket with that workflow, you can simply add a new parallel branch with the Create a new JIRA issue or the Create ServiceNow Record actions:
 Figure 6 – add parallel branches for JIRA and/or ServiceNow to the Logic App
Figure 6 – add parallel branches for JIRA and/or ServiceNow to the Logic App
Next Steps
Resource Exemption in Azure Security Center now gives you a way to exempt resources from a recommendation in case it has already been remediated by a process not monitored by Azure Security Center, or in case your organization has decided to accept the risk related to that recommendation. You can easily build your own automations around that feature or leverage the sample artifact we have published in the Azure Security Center GitHub community. You can also publish your own automation templates in the community, so others can benefits from your efforts, as well. We have started a GitHub Wiki so you can easily learn how to publish your automations.
Now, go try it out and let us know what you think! We have published a short survey so you can easily share your thoughts around this new capability and the automation artifact with us.
Special thanks to Miri Landau, Senior Program Manager for reviewing this article.

Recent Comments