This article is contributed. See the original author and article here.
Azure Synapse Analytics brings the worlds of data integration, big data, and enterprise data warehousing together into a single service for end-to-end analytics, at cloud scale. This week at Microsoft Ignite we announced several features that bring accelerated time to insight via new built-in capabilities for both data exploration and data warehousing.
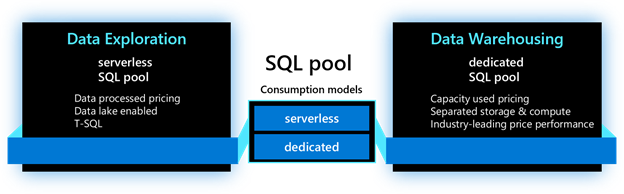
As we dive into each new feature, we will use the terminology below to identify where the feature is applicable. For the SQL capabilities in Azure Synapse Analytics, the main resource used is called a SQL pool. This resource has two consumption models: serverless and dedicated. The serverless model provides transparent compute consumption and is billed per data processed. The dedicated model allows use of dedicated compute, comes with capacity model and is billed per DWU-consumed. This new terminology will appear in the product soon.

Accelerate time to insight with:
-
Power BI performance accelerator for Azure Synapse Analytics (private preview)
Last year when we announced Azure Synapse Analytics, we promised to bring Microsoft’s data and BI capabilities together to deliver optimized experiences for our users. Today, we continue expanding on that promise with the announcement of the Power BI performance accelerator for Azure Synapse Analytics, a new self-managed process that enables automatic performance tuning for workloads and queries ran in Power BI.
As Power BI users run their queries and reports, the performance accelerator monitors those queries behind the scenes and optimizes their execution thus significantly improving query response times over the latest data. It analyzes all Power BI queries holistically and intelligently creates materialized views within the SQL engine while recognizing common query joins and aggregations patterns. As Power BI queries continue to execute, queries are automatically sped up and users observe increased query performance leading to quicker business insights. With new data being ingested into SQL tables, materialized views are automatically refreshed and maintained. Best of all, as more and more queries are being executed, the performance accelerator optimizes and adjusts the deployed materialized views to fine tune view design, all while reducing query execution times.
This feature can be enabled with a few clicks within the Synapse Studio. You can simply choose the frequency for executing the process and set the maximum storage to manage the size of the system-generated materialized views and it’s ready to start optimizing your Power BI workload.

The Power BI performance accelerator for Azure Synapse Analytics delivers a zero-management experience. It helps system administrators manage materialized views while allowing Power BI users to gain quick and up-to-date business insights.
This feature applies to dedicated model. To participate, submit your request here.
-
Azure Synapse Link for Azure Cosmos DB now includes Synapse SQL (public preview)
Azure Synapse Link connects operational data stores with high performance analytics engines in Azure Synapse Analytics. Using Synapse Link, customers can perform near real-time analytics directly over their data managed in Azure Cosmos DB without impacting the performance of their operational workloads.
Today, we are announcing the public preview of Azure Synapse Link for Azure Cosmos DB using Synapse SQL. This functionality is now available to all customers and is deployed worldwide. Customers can now use a serverless SQL pool in Azure Synapse Analytics to perform interactive analytics over Azure Cosmos DB data enabling quick insights and exploratory analysis without the need to employ complex data movement steps. Thanks to the rich T-SQL support for analytical queries and automatic schema discovery for data, it has never been easier to explore operational data by running ad-hoc and advanced analytical queries. Best of all, due to the rich and out-of-the-box ecosystem support, tools such as Power BI – and others – are just a few clicks away.

This feature applies to serverless model. To learn more, visit the Azure Synapse Link for Azure Cosmos DB documentation.
Note: this functionality will become available in the next few weeks.
-
Enhanced support for analyzing text delimited files (public preview)
Despite the availability and popularity of columnar file formats optimized for analytics, such as Parquet and ORC, most newly generated and legacy data is still in text delimited formats. With this in in mind, we are continuously improving the experience for delimited text data. To support immediate and interactive data exploration for this text data, the following enhancements are being introduced:
– Fast parser: The new delimited text parser (CSV version 2.0) provides significant performance improvement, ranging from 2X (querying smaller files) to up to 10X or more (querying larger files). This new performance improvement, based on novel parsing techniques and multi-threading, is available to all existing and newly provisioned Azure Synapse workspaces.
– Automatic schema discovery: With automatic schema discovery, OPENROWSET function can be used with CSV files without a need to define expected schema. As the system automatically derives the schema based on the data being queried, users can focus on the needed data insights leading to faster and easier data exploration.
– Transform as CSV: We have extended support for the CREATE EXTERNAL TABLE AS SELECT statement to enable storing query results in the delimited text format. This functionality enables multi-stage data transformation to be performed while keeping the data in delimited text format throughout its lifecycle.

This feature applies to serverless model. To learn more, visit the Azure Synapse SQL documentation.
Improve data loading performance and ease of use with:
-
COPY command (Generally Available)
Loading data into your data warehouse may not always be the easiest task. Defining the proper table structure to host your data, data quality problems, handling incorrect data and errors, and ingestion performance are among some of the typical issues customers face. We designed the COPY command to tackle these problems. The COPY command has become the default utility for loading data into data warehouses within Azure Synapse Analytics. In addition to bringing the COPY command into General Availability state, we have also added the following features:
– Automatic schema discovery: The whole process of defining and mapping source data into target tables is a cumbersome process, especially when tables contain large numbers of columns. To help with this, we are introducing built-in auto-schema discovery and an auto-table creation process (auto_create_table option in preview within COPY). When used, the system automatically creates the target table based on the schema of the Parquet files.
– Complex data type support: COPY command now supports loading complex data types stored in Parquet files which eliminates the previous need to manage multiple computes. When used together with the automatic schema discovery option, complex data types will automatically be mapped to nvarchar columns.
These new functionalities are also supported in partner products as well. Azure Stream Analytics, Azure Databricks, Informatica, Matillion, Fivetran, and Talend are among the products and services that support the new COPY command.
This feature applies to dedicated model. To learn more, visit the COPY documentation.
-
Fast streaming ingestion (Generally Available)
With the rise of IoT devices, both the amount and velocity of the data produced has increased dramatically. To make that data available for analysis and to reduce the time it takes to load and query this data within your data warehouse environments, we are announcing the General Availability of high throughput streaming data ingestion (and inline analytics) to dedicated SQL pools in Azure Synapse using Azure Stream Analytics. This new connector can handle ingestion rates exceeding 200MB/sec while ensuring very low latencies.
With Azure Stream Analytics, in addition to high throughput ingress, customers can use SQL to run in-line analytics such as JOINs, temporal aggregations, filtering, real-time time inferencing with pre-trained ML models, pattern matching, geospatial analytics and much more. It supports common formats such as JSON, and custom de-serialization capabilities to ingress and analyze any custom or binary streaming data formats. More details can be found in the announcement blog.
This feature applies to dedicated model. To learn more about high throughput streaming ingestion, visit our documentation.
Secure your sensitive data using:
-
Column-level Encryption (public preview)
As data gets moved to the cloud, securing your data assets is critical to building trust with your customers and partners. Azure Synapse Analytics already provides a breadth of options that can be used to handle sensitive data in a secure manner. We are expanding that support with the introduction of Column Level Encryption.
Column-level encryption (CLE) helps you implement fine-grained protection of sensitive data within a table (server-side encryption). With CLE, customers gain the ability to use different protection keys for different columns in a table, with each key having its own access permissions. The data in CLE-enforced columns is encrypted on disk, and remains encrypted in memory, until the DECRYPTBYKEY function is used to decrypt it. Azure Synapse Analytics supports using both symmetric and asymmetric keys.
This feature applies to dedicated model. To learn more, visit the Column Level Encryption documentation.
Improve productivity with expanded T-SQL support:
-
MERGE support (public preview)
During data loading processes, often there is a need to transform, prepare, and consolidate data from different and disparate data sources into a target table. Depending on the desired table state, data needs to be either inserted, updated, or deleted. Previously, this process could have been implemented using the supported T-SQL dialect. However, the process required multiple queries to be used which was costly and error prone. With the new MERGE support, Azure Synapse Analytics now addresses this need. Users can now synchronize two tables in a single step, streamlining the data processing using a single step statement while improving code readability and debugging.
This feature applies to dedicated model. For more details, see our MERGE documentation.
Note: this functionality will become available in the next few weeks.
-
Stored procedures support (public preview)
Stored procedures have long been a popular method for encapsulating data processing logic and storing it in a database. To enable customers to operationalize their SQL transformation logic over the data residing in their data lakes, we have added stored procedures support to our serverless model. These data transformation steps can easily be embedded when doing data ingestion with Azure Synapse, and other tools, for repeatable and reliable execution.
This feature applies to serverless model.
Note: this functionality will become available in the next few weeks.
-
Inline Table-Valued Functions (public preview)
Views have long been the go-to method for returning queryable table results in T-SQL. However, views do not provide the ability to parameterize their definitions. While user-defined functions (UDFs) offer the power to customize results based on arguments, only those that return scalar values had been available in Synapse SQL. By extending support for inline table-valued functions (TVFs), users can now return a table result set based on specified parameters. Query these results just as you would any table and alter its definition as you would a scalar-valued function.
This feature applies to both serverless and dedicated models. For more details, visit the CREATE FUNCTION documentation.
Note: this functionality will become available in the next few weeks, post deployment.
Try Azure Synapse Analytics today
- Sign up for an Azure free account and get $200 of credit to try Azure Synapse
- Create an Azure Synapse workspace in minutes to access these new features
- Learn more with the Azure Synapse SQL documentation
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments