by Contributed | Mar 16, 2021 | Technology
This article is contributed. See the original author and article here.
Some of you have seen a blog on Azure AD only authentication (hereafter “AAD-only auth”) that was accidently published. With this blog we would like to correct the previous message and announce that this feature will be in a public preview in April and will support all Azure SQL SKUs such as Azure SQL Database, Azure Synapse Analytics and Managed Instance (MI).
Following the SQL on-premises feature that allows the disabling of SQL authentication and enables only Windows authentication, we developed a similar feature for Azure SQL that allows only Azure AD authentication and disables SQL authentication in the Azure SQL environment.
When “AAD-only auth” is active (enabled), it disables SQL authentication, including SQL server admin as well as SQL logins and users, and allows only Azure AD authentication for the Azure SQL server and MI. SQL authentication is disabled at the server level (including all databases) and prevents any authentication (connection to the Azure SQL server and MI) based on any SQL credentials.
Although SQL authentication is disabled, the creation of new SQL logins and users is not blocked. Neither the pre-existing nor newly created SQL accounts will not be allowed to `connect to the server. In addition, enabling the AAD-only auth does not remove existing SQL login and user accounts, but it disallows these accounts to connect to Azure SQL server and any database created for this server.

by Contributed | Mar 16, 2021 | Technology
This article is contributed. See the original author and article here.
The purpose of this about is to discuss Managed and External tables while querying from SQL On-demand or Serverless.
Thanks to my colleague Dibakar Dharchoudhury for the really nice discussion related to this subject.
By the docs: Shared metadata tables – Azure Synapse Analytics | Microsoft Docs
Spark provides many options for how to store data in managed tables, such as TEXT, CSV, JSON, JDBC, PARQUET, ORC, HIVE, DELTA, and LIBSVM. These files are normally stored in the warehouse directory where managed table data is stored.
Spark also provides ways to create external tables over existing data, either by providing the LOCATION option or using the Hive format. Such external tables can be over a variety of data formats, including Parquet.
Azure Synapse currently only shares managed and external Spark tables that store their data in Parquet format with the SQL engines
Note “The Spark created, managed, and external tables are also made available as external tables with the same name in the corresponding synchronized database in serverless SQL pool.”
Following an example of an External Table created on Spark-based in a parquet file:
1) Authentication:
blob_account_name = "StorageAccount"
blob_container_name = "ContainerName"
from pyspark.sql import SparkSession
sc = SparkSession.builder.getOrCreate()
token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary
blob_sas_token = token_library.getConnectionString("LInkedServerName")
spark.conf.set(
'fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name),
blob_sas_token)
Note my linked Server Configuration:
2) External table:
Spark.sql('CREATE DATABASE IF NOT EXISTS SeverlessDB')
#THE BELOW EXTERNAL SPARK TABLE
filepath ='wasbs://Container@StorageAccount.blob.core.windows.net/parquets/file.snappy.parquet'
df = spark.read.load(filepath, format='parquet')
df.write.mode('overwrite').saveAsTable('SeverlessDB.Externaltable')
Here you can query from SQL Serverless

If you check the path where your external table was created you will be able to see under the Data lake as follows. For example, my workspace name is synapseworkspace12:

3) I can also create a managed table as parquet using the same dataset that I used for the external one as follows:
#Managed - table
df.write.format("Parquet").saveAsTable("SeverlessDB.ManagedTable")
This one will also be persisted on the storage account under the same path but on the managed table folder.
Following the documentation. This is another way to achieve the same result for managed table, however in this case the table will be empty:
CREATE TABLE SeverlessDB.myparquettable(id int, name string, birthdate date) USING Parquet

Those are the commands supported to create managed and external tables on Spark per doc. that would be possible to query on SQL Serverless.
If you want to clean up this lab – Spark SQL:
-- Drop the database and it's tables
DROP DATABASE SeverlessDB CASCADE
That is it!
Liliam
UK Engineer

by Contributed | Mar 16, 2021 | Technology
This article is contributed. See the original author and article here.
Introduction & Profiles
Hi there everyone! We are Team 21, first place prize winners of the Imperial College London Data Science Society’s (ICDSS) 2021 AI Hackathon for the ‘Kaiko Cryptocurrency Challenge’. We are Howard, a penultimate Mechanical Engineering student and Stephanie, a penultimate Molecular Bioengineering student from Imperial College London.
Check out the full report and code in this repo: https://github.com/howardwong97/AI-Hack-2021-Team-21-Submission .
Feel free to contact us if you have any questions!
Kaiko Cryptocurrency Challenge and Our Motivation
The Kaiko Cryptocurrency Challenge provided cryptocurrency market data to create a predictive model. We tackled this challenge by investigating the effectiveness of traditional time series models in predicting volatility in the cryptocurrency market and the effect of introducing social media sentiment.
If we look at the Bitcoin volatility index, the latest 30-day estimate for the BTC/USD pair is 4.30%. There are several factors contributing to the high volatility in cryptocurrency prices: low liquidity, minimal regulation, and the fact that it’s a very young market. It is incredibly difficult to apply fundamental analysis and so the values of cryptocurrencies are mostly driven by speculation. Social media, therefore, makes a huge impact. Take the tweet from Elon Musk about Dogecoin, for example, we observed a dramatic price drop and increased volatility. Although we can’t say with certainty that what happened was a direct result of the tweet, we cannot underestimate the effect of social media on the cryptocurrency market.
Exploratory Data Analysis
Instead of working directly with prices, we compute the returns, which normalizes the data to provide a comparable metric. Furthermore, we take the log of the returns, which has the desirable property of additivity. Denoted by , the log returns can be written as

The histogram of log returns is plotted below. It is often assumed that log returns, especially in the equities market, are normally distributed. The unimodal distribution seems to agree with this assumption. However, the negative skew and excess kurtosis suggests that this is not the case!

Mean
|
Variance
|
Skew
|
Excess Kurtosis
|
-0.000002
|
4.68e-07
|
-4.26
|
179.5
|
We are interested in modelling the serial correlation observed in the log returns. The autocorrelation function (ACF) plot suggests that there is significant serial correlation. In addition, plotting the partial autocorrelation function (PACF) of the squared log returns allows shows autoregressive conditional heteroskedastic effects (more on this later). In other words, the volatility is not serially independent.

Lastly, we talk about the concept of stationarity. Roughly speaking, a time series is said to be weakly stationary if both the mean of  and the covariance of and
and the covariance of and  are time invariant. This is the foundation of time series analysis; the mean is only informative if the expected value remains constant across time periods. Therefore, we performed the Augmented Dickey-Fuller unit-root test and confirmed that the log returns is indeed stationary.
are time invariant. This is the foundation of time series analysis; the mean is only informative if the expected value remains constant across time periods. Therefore, we performed the Augmented Dickey-Fuller unit-root test and confirmed that the log returns is indeed stationary.
Time Series Analysis
A mixed autoregressive moving average process, or ARMA, is written as

One of the assumptions of ARMA is that the error process, , is homoscedastic or constant over time. However, we have seen from the PACF plot of the squared log returns that this might not be the case. Volatility has some interesting characteristics. Firstly, asset returns tend to exhibit volatility clustering; volatility tends to remain high (or low) over long periods. Secondly, volatility evolves in a continuous manner; large jumps in volatility are rare. This is where volatility models come in. The idea of autoregressive conditional heteroscedasticity (ARCH) is that the variance of the current error term is dependent on previous shocks. An ARCH model assumes.
, is homoscedastic or constant over time. However, we have seen from the PACF plot of the squared log returns that this might not be the case. Volatility has some interesting characteristics. Firstly, asset returns tend to exhibit volatility clustering; volatility tends to remain high (or low) over long periods. Secondly, volatility evolves in a continuous manner; large jumps in volatility are rare. This is where volatility models come in. The idea of autoregressive conditional heteroscedasticity (ARCH) is that the variance of the current error term is dependent on previous shocks. An ARCH model assumes.

Generalised ARCH (GARCH) builds upon ARCH by allowing lagged conditional variances to enter the model as well:

The constants  ,
,  and
and  are parameters to be estimated.
are parameters to be estimated.  can be interpreted as a measure of the reaction of the volatility to market shocks, while
can be interpreted as a measure of the reaction of the volatility to market shocks, while  measures its persistence. Therefore, ARMA specifies the structure of the conditional mean of log returns, while GARCH specifies the structure of the conditional variance. Put together, an ARMA-GARCH can be summarised as
measures its persistence. Therefore, ARMA specifies the structure of the conditional mean of log returns, while GARCH specifies the structure of the conditional variance. Put together, an ARMA-GARCH can be summarised as

Forecasting Volatility
Another interesting property of volatility is that it is not directly observable. For example, if we had daily log returns data for BTC, we cannot establish the daily volatility. However, data with finer granularity (e.g., one-minute data) is available, one can estimate this by taking the sample standard deviation over a single trading day. Therefore, we used the following forecasting scheme:
- Reduce the resolution of the log returns to five-minute intervals. Since log returns are additive, we can simply sum the log returns
 to
to  .
.
- Compute the realized volatility for each five-minute period.
- Use a rolling window of 120 samples to fit ARMA-GARCH using maximum likelihood.
- Use fitted parameter estimates to compute the forecasted volatility for the next five-minute interval.
Fitting the model on a rolling window and then forecasting the following period’s five-minute volatility ensure that we avoid look-ahead bias.

The results are plotted above. Clearly, the ARMA GARCH model did not perform very well! Indeed, we have fitted ARMA(1,1) and GARCH(1,1) for simplicity; other lag orders could be necessary. One could also argue that the models were also over a relatively short timeframe.
Sentiment Analysis
There are many flavours of GARCH (e.g. I-GARCH, E-GARCH). However, we are interested in exploring the possibility of introducing sentiment regressors to the GARCH model specification. It is straightforward to introduce additional terms, i.e.

where  is an additional explanatory variable, and is a new parameter to be estimated.
is an additional explanatory variable, and is a new parameter to be estimated.
So how do we measure sentiment? For this, we turn to Reddit, which provides an API for searching for posts and comments. We performed a search for “Bitcoin” and “BTC” across several subreddits (yes, including WallStreetBets).
What remains is to engineer features for our model. There are two key features that we saw to be the most informative:
- Frequency – how many times Bitcoin has been mentioned on Reddit within a timeframe?
- Sentiment – what is the overall sentiment (positive or negative)?
Indeed, upvotes would have been a good feature to include too, as it is an indication of the reach of the post or comment. However, we did not include this in this project.
Natural Language Processing (NLP) techniques have been utilised in the past to detect sentiment as positive or negative. However, comments about the financial markets are unique in terms of terminology. Therefore, a domain-specific corpus must be built to train a sentiment model. Conveniently, Stocktwits is a site where users can label their own comments as either “bullish” or “bearish”, so this would be the perfect source for training data. In our past work, we scraped thousands of posts and trained a RoBERTa model.
What is RoBERTa? Many are familiar with BERT, the self-supervised method released by Google in 2018. Researchers at the University of Washington built upon this by removing BERT’s next-sentence pretraining objective, and training with much larger mini-batches and learning rates. We chose this due to its promise of better downstream task performance – this is especially important in a 24-hour Hackathon!
Feature Engineering
Having scraped all mentions of Bitcoin on Reddit over the period, we made sentiment predictions using our financial RoBERTa model, which labels each comment as “Bullish” (positive) or “Bearish” (negative). We created the following features:
- N, the number of comments made about BTC in the past hour.
- S, computed by defining
 and
and  and summing these for each comment in the past hour.
and summing these for each comment in the past hour.
The new GARCH specification is now

It is important to ensure that N and S are synchronous with the log returns (i.e. the post or comment was published at or before the time period of interest).

Results
So, how did our new sentiment-based model perform? Terribly! In fact, the mean square error (MSE) of this new model was about ten times worse than the original model. There are clearly many pitfalls in the work that we have presented here. Our sentiment model was clearly very simplistic as it only provided a ‘bullish’ or ‘bearish’ signal. The Reddit dataset that we created was also relatively small – there are other sources of news that we could have used. One could also argue that our sentiment model was incapable of identifying bots deployed to manipulate sentiment models such as this one.
Something also must be said about the efficacy of traditional time series models. GARCH models have historically been rather effective in forecasting daily volatility. However, our intuition tells us that social media sentiment clearly plays a big factor. Our future work will be focused on thinking of more appropriate ways of integrating this into our model.
Resources
Microsoft Learn BlockChain
Beginners Guide to BlockChain on Azure
by Contributed | Mar 16, 2021 | Technology
This article is contributed. See the original author and article here.
In this installment of the weekly discussion revolving around the latest news and topics on Microsoft 365, hosts – Vesa Juvonen (Microsoft) | @vesajuvonen, Waldek Mastykarz (Microsoft) | @waldekm are joined by are joined by Scotland-based Solution Architect, dual MVP Veronique Lengelle (CPS) | @veronicageek.
The discussion included insights to the role of technical architect for Microsoft 365 platform – both about designing solutions that solve customer problems and as important – educating customers on the value of the integrated platform. Microsoft Teams vs SharePoint – meet the customer where they are at and coach from there. “Don’t neglect to deliver SharePoint training and don’t focus solely on Microsoft Teams.” And finally, the growth in partner opportunities as many customers who quickly moved to M365 and the cloud in the last year are now looking for guidance on how to leverage many more of the platform’s capabilities that they own. Veronique is an active contributor to PnP PowerShell project, as a champion for Sys Admin users.
As with the previous week, Microsoft and the Community delivered 23 articles and videos this last week. Brilliant! This session was recorded on Monday, March 15, 2021.
This episode was recorded on Monday, March 15, 2021.
These videos and podcasts are published each week and are intended to be roughly 45 – 60 minutes in length. Please do give us feedback on this video and podcast series and also do let us know if you have done something cool/useful so that we can cover that in the next weekly summary! The easiest way to let us know is to share your work on Twitter and add the hashtag #PnPWeekly. We are always on the lookout for refreshingly new content. “Sharing is caring!”
Here are all the links and people mentioned in this recording. Thanks, everyone for your contributions to the community!
Microsoft articles:
Community articles:
Additional resources:
If you’d like to hear from a specific community member in an upcoming recording and/or have specific questions for Microsoft 365 engineering or visitors – please let us know. We will do our best to address your requests or questions.
“Sharing is caring!”

by Contributed | Mar 16, 2021 | Technology
This article is contributed. See the original author and article here.
|
Implementing SSO with Microsoft Accounts (for Single Page Apps) |
Project: UCL Resourcium
Team members: Louis de Wardt, Hemil Shah, Pritika Shah
Project Resourcium University College London
Guest blog by the Project Resourcium Team from University College London
With the complexities that come with setting up your own database to make a login system, the best alternative would be to use Microsoft live login instead. This works by “handing” over responsibilities of login management to Microsoft as well as security technicalities. Having to design your own database with login and passwords also slows the development process, giving you less time as developers to focus on things that you need. Our project aimed to allow an easy way for students to access our application and get assistance. The simplest answer was for students to use their existing login (also known as SSO ‘Single Sign On’) to access apps. This does not only simplify things for the developer, but also the user themselves since it reduces the need for them to remember another set of usernames and passwords. This article will explain in detail on how you can setup your application to use live login directly with Microsoft.
This is designed to work for single page apps, if your app involves a web server serving each web page then you will need to use a slightly different login flow (specifically the `Web` flow rather than the `Single-page application`)
Setting everything up:
- You need an app registration on Azure Active Directory. Go to Active Directory -> App Registrations -> New Registration. We chose `SSO Example App` for the app name but you can choose your own app name. You need to decide for yourself whether your app should be single or multi-tenant. We can skip the redirect URL for now but we’ll need to come back to that. These screenshots describe this process visually:

Press the new registration button:

- You need a web based application with a button that can trigger the sign on event. An example of a simple one can be found at the end. This application also needs to be hosted on a URL. For development it is common to use localhost. For example react applications would be `http://localhost:3000`. If your application is composed of just static files then you’ll need a local web server to host them. A simple way is to use the following command (assuming you have python installed) `python3 -m http.server 3000` which will broadcast the current directory to your local computer on port `3000`, you should be able to access your website at `http://localhost:3000` in your browser.
- In the app registration you need to add the URL of your app to the list of allowed redirect URLs. To do this go to Authentication -> Add a Platform -> Single-page application. Then enter the redirect URL and then press configure (leave all the other values as their defaults). When you publish your app you will also need to add the public URL of the app as another redirect URL.
Here you can see screenshots showing each step:

Here you choose Single-page application:

Enter in the redirect URL (such as http://localhost:3000):

Code
- Add the MSAL library for JavaScript as a dependency to your project. There are multiple ways of doing this. You can either run npm install @azure/msal-browser or use a CDN. This is documented officially here.
- You need to copy the App ID and, if you are using single tenant, you also need the tenant ID. This information can be found in the Overview section of the App Registration.
Create a variable to store this information:
var msalConfig = {
auth: {
clientId: "{{APP_ID}}",
// Only required if single tenant (remove if multi-tenant)
authority:
"https://login.microsoftonline.com/{{TENANT_ID}}",
},
};
- Now we can create a function to start the login process.
function login() {
var msalInstance = new msal.PublicClientApplication(msalConfig);
msalInstance
// Here you can specify scopes (see example code for more details)
.loginPopup({})
.then((response) => {
if (response === null) {
showError("There was an error authenticating you (response was null)");
return;
}
showResult(response);
})
.catch((error) => {
showError("There was an unexpected error during the login process");
console.error(error);
});
}
Here we chose the popup method of authentication, you can also chose redirect.
The functions called showError and showResult are examples and they will likely be different in your application.
The response object has a field called accessToken which you can use to query data on behalf of the user.
Scopes
By default you are very limited by what you can do with the access token for security reasons. If you want to be able to perform more actions you can add scopes. Here is an example from the MSAL documentation:
var loginRequest = {
scopes: ["user.read", "mail.send"]
};
Now we can update the loginPopup parameters from earlier:
msalInstance
.loginPopup(loginRequest)
// ... the rest of the code
Now the access token will have access to those scopes.
Note: you will also need to update the permissions on the app registration for all scopes except for user.read which is on the registration by default.
Example app
You can find an example app here (https://resourcium.github.io/sso-article/example_site.zip) that demonstrates using SSO login on a single page app without any frameworks (pure JavaScript).
To run you need to download the source code and host it locally such as by using python3 -m http.server 3000. You then need to create the app registration which will give you access to a tenant id and an app id. You should then edit the script.js file to update the clientId and authority (see the msalConfig variable). You need to set the single page app redirect URL to be localhost:3000 or your local URL.
Useful links:
by Contributed | Mar 16, 2021 | Technology
This article is contributed. See the original author and article here.
Have you ever wondered if there is an option to limit the number of agents you need to deploy on your servers to allow for proper monitoring?
There is the Azure monitor Agent, the performance monitoring agent, the Desired State Configuration Agent, and many more…
What if I told you this is about to change?
Well, it is. So read on and find out what’s in store for you.
The upcoming Azure Monitor Agent (AMA) currently in preview, will orchestrate the collection of monitoring data from the guest operating system of your server and VMs and deliver it to Azure Monitor. It will simplify the way you deploy and configure the afore mentioned collection while it enables new capabitities not available with the current set of monitoring agents.
Join Pierre Roman and Shayoni Seth (Senior Program Manager on the Azure Monitor Agent team) as they discuss the upcoming Azure Manager Agent changes.
You can watch the video here or on Channel 9
Resources:
by Contributed | Mar 15, 2021 | Technology
This article is contributed. See the original author and article here.
The Azure API for FHIR is a managed service that allows for rapidly exchanging data in the HL7 FHIR standard format with a single, simplified data management solution for protected health information (PHI). Azure API for FHIR lets you quickly connect existing data sources, such as electronic health record systems and research databases.
Watch our other videos:
Role of FHIR in Modern Health Solutions
Impact of the ONC Cures Act Final Rule
Resources:
Learn More about the Azure API for FHIR
Deploy the Azure API for FHIR
Data agility and open standards in Health
by Contributed | Mar 15, 2021 | Technology
This article is contributed. See the original author and article here.
In this video we will provide an overview of ONC’s Cures Act Final Rule which is designed to give patients and their healthcare providers secure access to health information. It also aims to increase innovation by fostering an ecosystem of new applications to provide patients with more choices in their healthcare.
We will discuss the impact of the ONC Cures Act Final Rule – how it impacts the adoption of FHIR, what the provisions of the rule are and also the timelines laid down by the Rule for implementation.
by Contributed | Mar 15, 2021 | Technology
This article is contributed. See the original author and article here.
This month brings two more reasons to choose Microsoft 365 Business Premium as the solution for your business’s productivity, collaboration, and security needs.
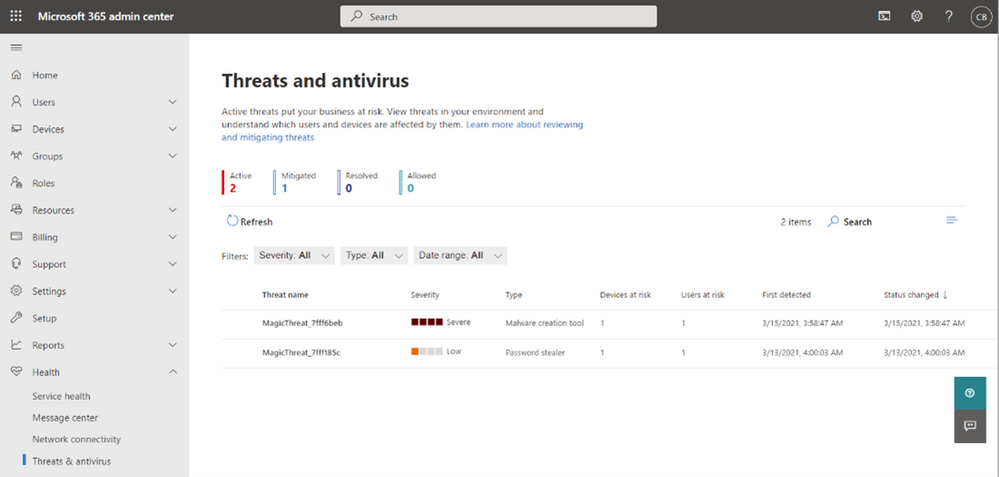
In September we announced new management capabilities for Microsoft Defender Antivirus in Microsoft 365 Business Premium. The new Active Threats page of that antivirus management experience has been rolling out for the past few months and is now available to all customers worldwide.
View a consolidated list of threats right from the Microsoft 365 Admin Center
You can access this page from the Microsoft 365 Admin Center, beneath the Health menu. This provides a consolidated view of any threats detected in Microsoft Defender across all the managed Windows 10 PCs within your organization. The machines must be managed by Intune and not running other antivirus solutions. If you aren’t using your Business Premium subscription to manage your PCs with Intune yet, the simplified setup experience we introduced last year is a great way to get started.
This new infrastructure manages the version of Microsoft Defender that is included in Windows 10, so there is no additional software to install or manage. Microsoft Defender runs quietly and efficiently, leveraging Microsoft’s intelligent security graph for powerful cloud-based protection. Many of the customers we talk with aren’t aware of how good this built-in version of Defender has become, and it’s worth a look if you are interested in eliminating the extra expense of a third-party antivirus product and simplifying your IT operations.
On March 2nd, general availability of Universal Print was announced at Microsoft Ignite. Universal Print allows IT to manage printers directly through a centralized portal, without the need for on-premises print servers. This is great news for customers who are looking to eliminate their last few servers and get the benefits of a 100% cloud setup. This video describes some of the benefits of Universal Print, which is included in Microsoft 365 Business as well as enterprise plans.
These are two new ways that Microsoft 365 Business Premium can help your business thrive by providing essential productivity, collaboration, security, and management capabilities.
We’re eager to hear your feedback as you begin using these new features, so be sure to share your experiences and ask questions in here in the Tech Community.
To learn more about the new Active Threats view, see Threats detected by Microsoft Defender Antivirus – Microsoft 365 Business | Microsoft Docs
To learn more about Universal Print, see the official announcement
If you are an IT services partner, learn how you can help your customers be more secure using Microsoft 365 Business Premium with this partner playbook and webinar series
by Contributed | Mar 15, 2021 | Technology
This article is contributed. See the original author and article here.
As a result of the issues currently facing Azure AAD, we are currently experiencing problems on the Microsoft Tech Community with login and authentication. This will result in users being unable to login and users already logged in getting unexpected errors as sessions timeout.
** Updated at 4pm PT **
This issue is now resolved, apologies for any inconvenience.
Note: Some Azure services may still be affected by this issue and you can find updates about this on the Azure Status pages.
Allen Smith
Technical Lead
Microsoft Tech Community



Recent Comments