– Up next, if you’re looking to significantly improve your apps and workloads in Azure, we’re going to look at free tools and guidance for discovering and assessing the reliability, security, costs, operations, and performance of what you have running in Azure with actionable recommendations to optimize your architecture across these areas. I’m joined today by Azure expert, Matt McSpirit. It’s great to have you back on for another impactful topic.
– Great. Thanks for having me.
– So on a previous show together, we looked at free assessment tools to give you a clear path forward in Azure, as you navigate the various options. So why don’t we fast forward a bit to the point where you might have a few workloads and services that you’re developing or running in production, and you want to improve the app architecture to reduce costs, maybe improve efficiency or resiliency. Where would you even get started?
– It’s a really common question. Even if you’ve done the due diligence to plan and architect your workloads really well, oftentimes there’s still a ton of room for optimization for your existing services. Now, to help with this, there’s the Azure Architecture Center. And there you get to the Well-Architected Framework, which is a set of guiding tenants derived from the experience gathered from real-world implementations. And this is defined across five main categories. The first is reliability, or the ability of a system to recover from failures and continue to function, where we define various principles for things like testing, resiliency and more. And there’s security, which is about protecting applications and data from threats. So here we share guidance for building a comprehensive strategy, including how you design for specific attacks and how to continually monitor, improve and respond. Then there’s cost optimization for managing costs to maximize the value of what you spend from planning to consumption, monitoring, and optimization. Then there’s operational excellence, where we provide guidance on operations and processes that keep a system running in production. And lastly, performance efficiency, where we tease out the main considerations to ensure that your system can monitor and respond to service issues to meet your SLAs.
– Makes sense. So looking across all the five different categories, how can we help then in those different areas?
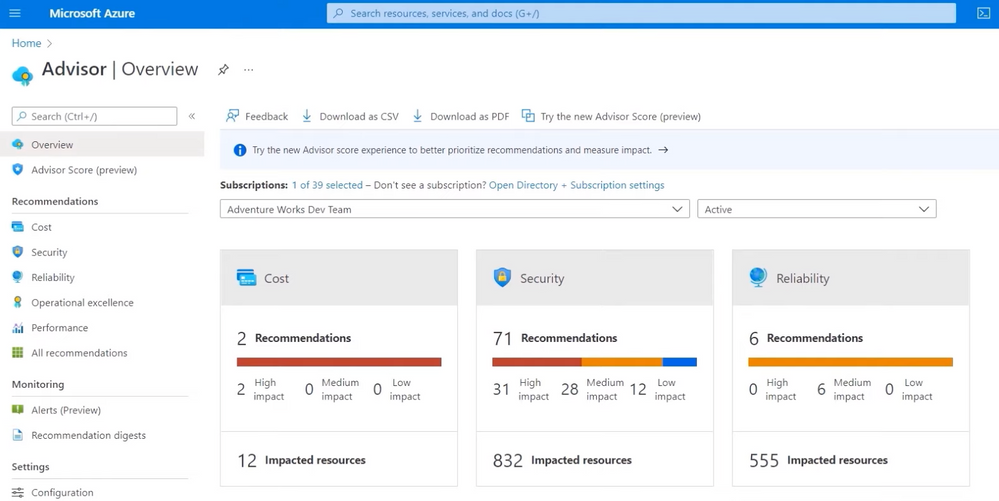
– Well, the good news is, is that the categories are built into the various tools and resources. For example, the framework’s incorporated in Azure Advisor and in the Azure Well-Architected review self-assessment to give you actionable recommendations. In fact, let’s start in the Azure portal with Azure Advisor, which is a free tool that continually analyzes your resource configuration, usage telemetry, and then provides actionable recommendations in real time in the subscription context. So here for my subscription, I can see that there are recommendations specific to all the categories in the Well-Architected Framework, and they’re even divided into high, medium, and low impact. And we also provide an Advisor Score, which aggregates advisor recommendations into a simple, actionable score to prioritize the actions that are going to yield the biggest improvement to the posture of your workloads. So here I can see my score across the five categories. And in my case, there are opportunities especially to save costs and increase security. Now in costs, I can see a pretty common recommendation to right size or shut down underutilized virtual machines. So if I click on Security, there are 71 recommendations, spanning permissions, encryption, networking, and more. So I’ll click back into costs. And one of the great things about this assessment is just how actionable these recommendations are. In fact, if I click into this quick fix recommendation for right sizing and shutting down unused VMs, you’ll see it lists 10 VMs that could be optimized and the potential cost savings for each. Now, our dev team’s in India, and if we look at this VM resource here, DP-Win-01, for example, it looks underutilized. We could save 139,000 rupees, which is around $1,900 dollars. And if I click into the usage patterns, you can see it’s just using a tiny amount of CPU, under half a percent. So this isn’t a production VM, and I can shut it down to save costs. So back in my list of recommended actions, I’ll choose to shut down the VM. And from right here, I can shut it down and confirm. So from a Well-Architected perspective, I was able to see and get actionable recommendations in the context of my subscription to optimize the costs of running my workloads.
– And it’s really great to see everything right there in context for you, and you can take action right from Azure Advisor. And I think it’s going to save a lot of time, especially compared to things like manually navigating to that resource, then looking at its usage pattern, and then shutting it down. You know, sometimes finding these underutilized resources that are running in Azure can be like finding a needle in a haystack.
– Yep, absolutely. And as you saw there, there are similar recommendations often with quick fixes across security, reliability, operations, and performance. And what I just showed was in the context of a subscription, which could span across multiple workloads. So let’s now look at what you can do if you just want to get recommendations for a specific workload. So for example, I’ve got a retail site here for Adventure Works, and I’m going through the purchase flow and opening my shopping bag. And when I do that, you’ll see it shares information on what’s frequently bought together based on what is currently a manually-defined list. So we want to add some more intelligence to deliver tailored recommendations. For example, if I just purchased a few pairs of these Zalica trunks, it probably shouldn’t recommend them to me again. Now, in this case, even though we have a machine learning model ready, we don’t have a clear understanding of the architecture attributes that we need to plan for in order to make sure it’s architected in a way that’s reliable, secure, and cost optimized. Now to get guided recommendations, I can go back to the Microsoft assessments I showed last time I was on, and we can choose the Azure Well-Architected Review. So here, if I sign in, I can review individual workloads and track progress over time, and it’s even integrated with Azure Advisor. So I’ll sign in and start a new assessment to show you. I’ll modify the assessment name a little with AW ML model so I can easily return to it later. And I’ve got the option here to link this assessment to Advisor recommendations, but because this is a new workload that I’m assessing before deploying into production, I don’t need to get Azure Advisor recommendations for it quite yet, but we’ll come back to it in a moment. So I’ll go ahead and start. And then in my case, I’ll choose Azure Machine Learning for my workload type. And if you deploy in other workloads, the Core Well-Architected Review and Data Services are going to cover those use cases. So this review for Machine Learning looks at all five categories in the Well-Architected Framework, and I’m selecting all of them in this case. And you can see all of the questions on the left here, and you’ll see there are over 20 questions that you can choose to answer. Now to save a little time, I’ll just show you a few questions across the different categories. So under reliability, there’s questions asking if we’re resilient to failures. Under security, here we can see a question about managing identities. And in the section on costs, I’m asked to review current steps taken to make sure we’re optimizing our spend. And one more thing here in performance efficiencies, asking how I autoscale compute resources for training and inferencing. So once I’m finished, I’ll hit view guidance, and it’s going to output a score, which is based on my answers in each category. So it’s good to see that I’m green with a score of 77 as an average across the categories, but there are still areas to improve on, like performance, where I’m in the yellow. And if I scroll down, I can open each of the categories recommendations. So as I expand all of these one by one, you’ll see it’s highlighting areas where we can improve our workload, so I don’t need to hunt these articles down. And in fact, I’ll scroll back up to reliability. And here, you can see we’ve got a recommendation to use Azure Machine Learning to monitor data drifts. And if I click into the recommendation, it takes me directly to the article in Microsoft Docs to detect data drift and how to set up dataset monitoring, right down to the Python code sample.
– And this is really great, especially as a pre-deployment checklist in this case for your Machine Learning workload. But what if I’ve already got a few services and workloads that are running in Azure? Can I use it then for those cases?
– Absolutely. The Well-Architected Review is perfect for those periodic health checks of your workloads once they’re deployed and running. In fact, the recommendations from Azure Advisor are going to look for optimizations in your running set of Azure resources. So I’ll go back to my assessments homepage, and I’ll open another assessment for the entire retail Adventure Works site. Now, in this case, I scope the assessment to security only. So you’ve got the flexibility to focus on the categories that you really care about. Now, if I view the guidance, you’ll see it’s connected to Azure Advisor. And once there, I can expand the recommendations and you’ll see, in both columns, there are items from Azure Advisor in this subscription as noted by this icon. Now in fact, this recommendation here found that a few of my web apps aren’t connecting over HTTPS and this is something the team needs to address ASAP. And when I look at the affected resources, you’ll see it also as a quick fix. And I can view the logic and script for the fix. So if I select all the resources, I can implement the fix for every impacted web app right from Azure Advisor. So between the Well-Architected self-assessment through to Azure Advisor and the created resources available, everything I’ve shown you today helps you overcome specific learning curves, get automated recommendations, and take advantage of best practices from other Azure users globally, as you build and run your workloads.
– And these are going to be really helpful tools, especially for anyone who’s looking to optimize what they have running in Azure, even like the pre-deployment checklist that you showed earlier. So what’s the best way then to get started with all this?
– Well, thankfully, there’s a number of different ways. So if you’ve got existing workloads in the Azure portal, you can use aka.ms/AzureAdvisor. This is an authenticated link to take you straight to the advisor overview for your tenant. Next, the Azure Architecture Center at aka.ms/Architecture is a great hub for all the resources you need. So there you’re going to find all the guidance and links to all the tools I showed today. And you can get to the Microsoft Assessments at aka.ms/MicrosoftAssessments and start your well-architected review.
– Thanks so much for joining us today, Matt and sharing all the great tools. Of course, keep checking back to Microsoft Mechanics for the latest updates. Subscribe, if you haven’t already, and thank you for watching.

 Chocolates, flowers, and spending time with your special someone are all Valentine’s Day traditions, but what about helping a friend or loved one spot and avoid a romance scam?
Chocolates, flowers, and spending time with your special someone are all Valentine’s Day traditions, but what about helping a friend or loved one spot and avoid a romance scam?



Recent Comments