This article is contributed. See the original author and article here.
This post was co-authored with Jinzhu Li and Sheng Zhao
Neural Text to Speech (Neural TTS), a powerful speech synthesis capability of Cognitive Services on Azure, enables you to convert text to lifelike speech which is close to human-parity. Since its launch, we have seen it widely adopted in a variety of scenarios by many Azure customers, from voice assistants like the customer service bot like BBC and Poste Italiane, to audio content creation scenarios like Duolingo.
Voice quality, which includes the accuracy of pronunciation, the naturalness of prosody such as intonation and stress patterns, and the fidelity of audio, is the key reason that customers are migrating from the traditional TTS voices to neural voices. Today we are glad to share that we have upgraded our Neural TTS voices with a new-generation vocoder, called HiFiNet, which results much higher audio fidelity while significantly improving the synthesis speed. This is particularly beneficial to customers whose scenario relies on hi-fi audios or long interactions, including video dubbing, audio books, or online education materials.
What’s new?
Our recent updates on Azure Neural TTS voices include a major upgrading of the vocoder. The voice fidelity has been improved significantly and audio quality defects such as glitches and small noises are largely reduced. Our tests show that this new vocoder generates audios without hearable quality loss from the recordings of training data (more details are introduced later). In addition, it can synthesize speech much faster than our previous version of product. All these benefits are achieved through a new-generation neural vocoder, called HiFiNet.
What is a vocoder and why does it matter?
Vocoder is a major component in speech synthesis, or text-to-speech. It turns an intermediate form of the audio, which is called acoustic feature, into audible waveform. Neural vocoder is a specific vocoder design which uses deep learning networks and is a critical module of Neural TTS.
Microsoft Azure Neural TTS consists of three major components in the engine: Text Analyzer, Neural Acoustic Model, and Neural Vocoder. To generate natural synthetic speech from text, first, text is input into Text Analyzer, which provides output in the form of phoneme sequence. A phoneme is a basic unit of sound that distinguishes one word from another in a particular language. Sequence of phonemes defines the pronunciations of the words provided in the text. Then the phoneme sequence goes into the Neural Acoustic Model to predict acoustic features, which defines speech signals, such as speaking style, speed, intonations, and stress patterns, etc. Finally, the Neural Vocoder converts the acoustic features into audible waves so the synthetic speech is generated.
The vocoder is critical to the final audio quality. In specific, it directly impacts the fidelity of a wave, including clearness, timbre, etc. Let’s hear the difference of the audio quality with samples generated using different neural vocoders based on the same acoustic features (recommended to listen with a high-quality headset).
Vocoder versions | 2018 vocoder for real-time synthesis | 2019 vocoder for real-time synthesis | 2020 for real-time synthesis (HiFiNet) |
“Top cinematographers weigh in on filmmaking in the age of streaming.” |
With each vocoder update, the speech generated sounds clearer, voice less muffled and noises reduced. In the next section, we introduce how a HiFiNet vocoder is trained during the creation of a neural voice model.
How does HiFiNet work?
In Azure TTS system, neural voice models are trained using human voice recordings as training data with deep learning networks. As part of the training, a vocoder is built with the goal to generate high quality audio output close to the original recordings from the training data. In the meantime, it needs to run fast enough to produce at least 24,000 samples per seconds, i.e. with a sampling rate of 24khz, which is the default sampling rate of Azure Neural TTS voice models.
Leveraging the state-of-art research on vocoders, we designed the training pipeline for HiFiNet, the new-generation Neural TTS vocoder, and applied it to create neural voice models in Azure Neural TTS. This pipeline is built with one simple goal: produce machine-generated audio waves (synthetic speech) that is indistinguishable from its original waves (human recordings) in a high speed.
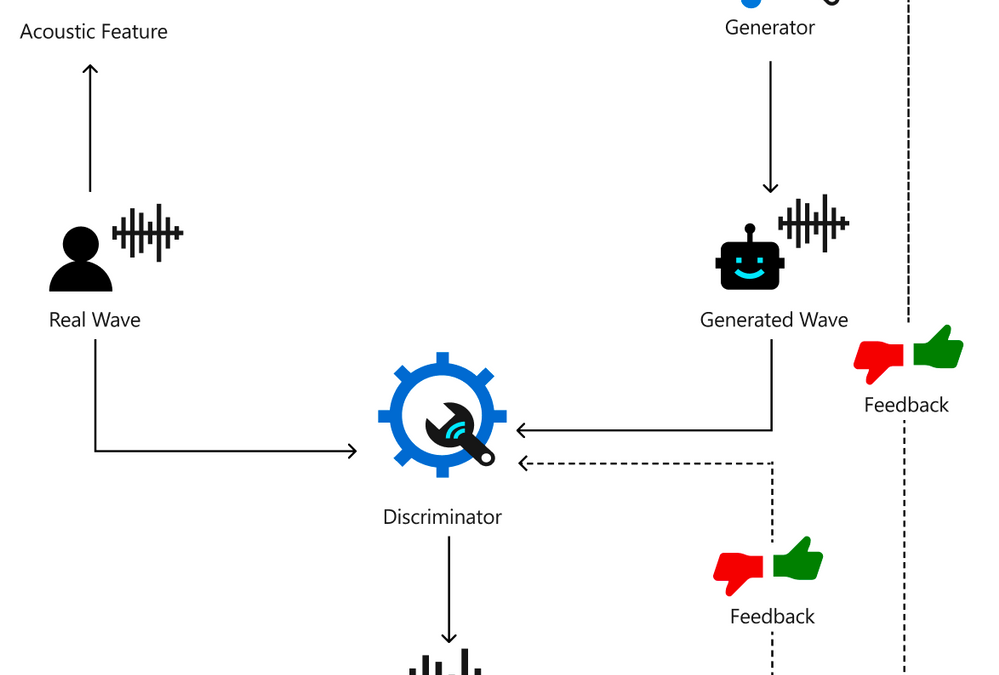
Below chart describes how the HiFiNet training pipeline works. With this pipeline, two key networks are trained: A Generator which is used to create audio (‘Generated Wave’), and a Discriminator which is used to identify the gap of the created audio from its training data (‘Real Wave’). The goal of the training is to make the Generator generate waves that the Discriminator can’t distinguish from the original real recordings.

First, the training pipeline uses the original human recording as input and extract the acoustic features. Then, the acoustic features are fed into the Generator module which generates waves, so we get two sets of waves: the original recordings as real waves, and the generated waves as fake waves. Next, the two sets of waves are fed into the Discriminator network to distinguish which are the real waves and which are the generated fake waves. This output from the Discriminator is used as feedback to help the Generator and Discriminator to learn better. As this training loop continues, the Generator becomes smarter to create indistinguishable fake waves, while the Discriminator gets smarter in making the right judgements. Finally, when the training reaches a point where Discriminator can’t distinguish the waves generated by the Generator from real waves, the vocoder is successfully trained. This vocoder is capable of producing audio outputs without noticeable quality loss compared to the original human recordings.
In the next section we describe the performance of HiFiNet vocoder.
What are the benefits?
HiFiNet significantly improves audio quality.
To understand the benefit of HiFiNet, we conducted a number of tests in many aspects which yelled positive results. Our tests show that the HiFiNet vocoder significantly improves the audio quality of the Neural TTS voice output, compared to our previous version of product.
CMOS (Comparative Mean Opinion Score) is a well accepted method in the speech industry for comparing the voice quality of two TTS systems. A CMOS test is similar to an A/B testing, where participants listen to different pairs of audio samples generated by two systems and provide their subjective opinions on how A compares to B. Normally in one test, we recruit 30-60 anonymous testers with qualified language expertise to evaluate around 50 pairs of audio samples side by side. The result is reported as CMOS gap, which measures the average of the difference in the opinion score between the two systems. In the cases where the absolute value of a CMOS gap is <0.1, we claim system A and B are on par. When the absolute value of a CMOS gap is >=0.1, then one system is reported better than the other. If the absolute value of a CMOS gap is >=0.2, we say one system is significantly better than the other.
We have done hundreds of CMOS tests of HiFiNet compared to our last version vocoder, on 68 neural voices across 49 languages/locales. Our results show that HiFiNet is notably better than the previous production vocoder in Azure Neural TTS.
In general, the audio quality, especially the fidelity is obviously improved. On average, across all languages, the HiFiNet vocoder achieves a CMOS gain higher than 0.2 compared to the previous vocoder, which means the improvement is hearable for users.
In particular, HiFiNet also has better robustness than the previous version of vocoder. Audio defects are largely reduced in the generated waves with HiFiNet. Our tests show that with the previous production vocoder, in 100 test samples, our testers can hear about 10 defects like beep, click sound, fidelity loss. Although most of them are not obvious, it can still be annoying if it keeps happening in a long audio or multi-round voice interactions. Now, these defects are no longer reported with the HiFiNet audios, under the same test procedure with the same test sets.
With these advantages, we have updated the Neural TTS voices on Azure Cognitive Services with the new vocoder. Listen to the samples below to hear the difference. Or test the new voices using your own text with our online demo.
Language | Previous vocoder | HiFiNet | HiFiNet CMOS gain |
English (US) | +0.122 (Better) | ||
German | +0.193 (Better) | ||
Chinese (Mandarin, Simplified) | +0.348 (Obviously Better) | ||
Japanese | +0.465 (Obviously Better) |
HiFiNet reaches human-parity audio fidelity.
In addition, we have conducted tests to compare the human recording audio quality and the computer-generated audio quality with HiFiNet. To make the comparison more accurate and more focused on the vocoder itself, we use the acoustic features extracted directly from human recordings instead of the TTS-predicted acoustic features so the acoustic differences are controlled and only the vocoder is evaluated in CMOS tests. Participants are asked to give their scores for different pairs of the generated waves and human recordings. Our result shows the CMOS gap of the audios produced by HiFiNet compared to human recordings is -0.05, which mean the difference is hardly hearable and the audio quality is on par.
Hear how close the HiFiNet audio fidelity is to the human recordings with the samples below.
Language | Human recording | HiFiNet | HiFiNet CMOS gap |
English (US) | +0.045 (on par) | ||
Chinese (Mandarin, Simplified) | -0.054 (on par) |
HiFiNet generates audios faster.
Real Time Factor (RTF) is used to measure the performance of vocoder. It is calculated as the time duration needed to generate the audio divided by the audio duration.
HiFiNet is a parallel vocoder so it can generate multiple samples at the same time. Here are some measurements of HiFiNet performance on both GPU and CPU devices.
With the output of 24khz sampling rate, on M60 GPU, through carefully optimized CUDA implementation, the vocoder RTF is around 0.01, which means the HiFiNet system can generate an audio 10 second-long in 0.1 second. This speed is almost 3x of our previous production vocoder.
On CPU machines, thanks to the highly-optimized ONNX runtime, the vocoder RTF is around 0.02 for 24khz sampling rate output.
With the performance improvement of HiFiNet, the end-to-end synthesis speed is about 50% faster than our previous Neural TTS engine, which the audio quality is significantly improved at the same time.
What to expect next
Currently we support up to 24khz sampling rate on Azure Neural TTS service with 68 neural voice models available. In some highly sophisticated scenarios like audio dubbing, higher fidelity output like 48khz sampling rate makes a world of difference.
Below snippet from an audio spectrum shows the difference between 48hz sampling rate and 24khz. Audios with 48khz sampling rate get a higher frequency responding range which keeps more sophisticated details and nuances of the sound. Such high sampling rate creates challenges on both voice quality and inference speed.

In our exploration, HiFiNet can handle both challenges well. According to our experiments, HiFiNet vocoder on 48khz sampling rate can be trained to achieve even higher quality with reasonable inference speed.
Hear the difference of the audio fidelity between the TTS output in 24khz and 48khs sampling rate, with a hi-fi speaker or headset.
Language | 24khz HiFiNet | 48khz HiFiNet | |
English (US) | |||
English (UK) | |||
The 48khz vocoder is now in private preview and can be applied to custom voices. Contact mstts [at] microsoft.com for details.
Create a custom voice with HiFiNet
The HiFiNet vocoder is also available in the Custom Neural Voice capability, enabling organizations to create a unique brand voice in multiple languages for their unique scenarios.
Learn more about the process for getting started with Custom Neural Voice.
Get started
With these updates, we’re excited to be powering more natural and intuitive voice experiences for global customers. Text to Speech has more than 70 standard voices in over 40 languages and locales in addition to our growing list of Neural TTS voices.
For more information:
- Try the TTS demo
- See our documentation
- Check out our sample code
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments