
by Contributed | Jun 20, 2022 | Technology
This article is contributed. See the original author and article here.
Education Insights aims to facilitate data-driven decisions, as we believe that data-informed educators and education leaders make the most significant impact in their schools. As an education professional, supporting students’ learning journeys while protecting their wellbeing is what you do. We’re here to help you identify needs and provide support from an informed perspective. We also highly value individual and organizational privacy and are committed to defending and protecting privacy for every student.
For those reasons, we provide Education Insights with attention to maintaining the highest external compliance standards, meeting GDPR, FERPA and other industry standards, as well as our own rigorous ethical and responsibility standards as established by Microsoft principles for Responsible AI.
In this blog, we will review some of the guidelines and practices Education Insights uses to help you leverage data to support your students, while maintaining peace of mind regarding your students’ data privacy and security. Additionally, we will provide some suggestions for to how to communicate Education Insights to your school community.
Guidelines and practices
1. High compliance standards
The information collected and shown through Insights meets national, regional, and industry-specific regulations for data collection and use, including GDPR and the Family Education Rights and Privacy Act (FERPA) for students and children’s security.
2. Students learning data only
Students’ digital activity data collected by Insights includes only their activity in the context of the class and of the learning journey, such as accessing learning materials, participating in meetings, uploading a resume, etc. We do not collect information about students’ private activities such as message content or working on personal files. We also respect educators’ privacy, hence no activity data from educators is displayed
3. Supportive and non-judgmental language
We believe that educators know their students best and are well positioned to make decisions about supporting their students. Education Insights doesn’t make judgements about students or educators. It aims to shine a light on student learning and digital engagement trends by providing meaningful activity data, leaving it up to the educator to follow up with students and to adapt instruction as they see fit.
4. Data access only for those who need it
To preserve students’ privacy, each person in the school community has access only to data relevant to them:
- Educators can only see the activity of students assigned to their classes. They cannot access data from other classes unless a collaborating educator has shared it with them.
- Education leaders get an organizational view of their students’ activity that depends on their role, organization affiliation, and the permissions assigned to them by the IT Admin.
Education Insights data belongs to the school or institution. Microsoft simply collects the data, analyzes, and stores it. Microsoft engineering does not have direct access to student data and all access is strictly controlled, logged and audited, you can learn more about it here.
5. Transparency for everyone
We are transparent in the data that is collected and how we use it. Each individual student also has a dedicated support page with authenticated access allowing them to see activity signals collected on them, along with instructions on how to contest the activity signals with their educators. Additionally, the IT admin can choose not to collect activity signals at any time; in which case Insights will not be available for the institution.
Communicating Education Insights to guardians and students
While data is critical to thoroughly support students, and while Education Insights provides data with high standards of ethical use, privacy, and security, we also understand that it is vital to communicate clearly to students and guardians the collection of data and the value it provides.
Here is a suggested baseline for communication in case it would be helpful to start a positive conversation with guardians and students. You can also share this blog for further details and links to resources :)
“Our priority as a school/district is always our students, and we aspire to equip them with the skills they need for success in school and beyond. Even before digital teaching practices were expedited by the outbreak of COVID-19, we knew that technology would make up a large part of lifelong learning.
Now, with students spending more educational time on digital platforms, our organization collects their digital activity in Microsoft Teams to support educators in adapting and supporting students’ learning and wellbeing in this changing environment. Data collected includes digital engagement, assignments status and grades, and their self-reflection of their wellbeing at school.
Any data collected is only in the context of the learning activity, non-learning activity data is not being collected. The data is shared only with the people that need it to best support the student, and with the intention of providing each student with the best educational possibilities for them and helping them thrive in school and life.
Students’ data is being collected, stored, and presented in a responsible manner, rigorously following and meets applicable national, regional, and industry-specific regulations for data collection and use, including GDPR and the Family Education Rights and Privacy Act (FERPA) .”
|
Some technical details for you
For those of you who are interested in some of the “backbone” of how Insights data is collected and stored:
Where do we store the ? Insights is deployed in Europe and the United States. Data for European-based users is stored on servers in Europe. Data for Australian-based and US-based users is stored on servers in the United States. Data for users outside of Europe, Australia, or the United States, will be stored in one of our geographic regions.
do we handle large volumes of data with high reliability? Insights leverages the power of Azure to ingest, process and store large amounts of signals in near-real time and with high reliability. All this is implemented on top of M365 secure environments. Each of these resources is provisioned in multiple geographical locations to honor the data locality explained above. Insights has a rich monitoring and alerting system which helps us track and mitigate potential data lost in the pipeline.
Learning more about data privacy in Education Insights
We’re always looking for ways to make Education Insights better. Have questions, comments, or ideas? Let us know! Add your ideas here or share your comment below.
by Contributed | Jun 18, 2022 | Technology
This article is contributed. See the original author and article here.
Row-level security (RLS) provides an important layer of security and is available as of PostgreSQL 9.5. It is also frequently used to implement data security for multi-tenant and SaaS applications. In this article, we will look at row level security on Azure Database for PostgreSQL – Hyperscale (Citus) to help you better understand how this feature might be used to implement data security in your application.
Before we get to RLS, here’s how Azure Database for PostgreSQL – Hyperscale helps with the distribution (sharding) of data. It brings the sharding logic to data layer and manages the shards across the nodes which make up the server group. Once you choose a relevant distribution key, Citus distributes the data. If you are a SaaS provider, the distribution key could be customer / tenant identifier. In such a case, with RLS, you can ensure the right set of data is visible to different users of the database across organizations while Citus can manage their data within single database cluster / server group.
Having looked at why, let’s jump right into how of this. We’re going to walk you through the steps to configure and test row level security in Azure Database for PostgreSQL – Hyperscale. You should start by Creating Azure PostgreSQL Hyperscale (Citus) instance / server group.
Once the hyperscale server group is created and ready for connection, let’s proceed with the next steps.
Create a Table and Load Some Sample Data:
We’re going to create a new schema which will hold the table(s) where we want to enable RLS. This is not really required but just to ensure that you get full understanding of how this should work in the real environment.
CREATE SCHEMA test1;
In this schema, we’ll create a distributed table and load some data into it.
Create table:
CREATE TABLE test1.events(
tenant_id int,
id int,
type text
);
Shard the table on ‘tenant_id’ column:
SELECT create_distributed_table(‘test1.events’,’tenant_id’);
Load dummy data into the table:
INSERT INTO test1.events VALUES (1,1,’push’);
INSERT INTO test1.events VALUES (2,2,’push’);
INSERT INTO test1.events VALUES (1,2,’push’);
INSERT INTO test1.events VALUES (2,1,’push’);
After adding this dummy data into the new table, next step is to add roles other than the default admin (citus) which will have access to data as per the need.
Add Additional Roles as Required:
To do this, you need to login to Azure Portal as the default role ‘citus’ isn’t given privileges to create new roles.
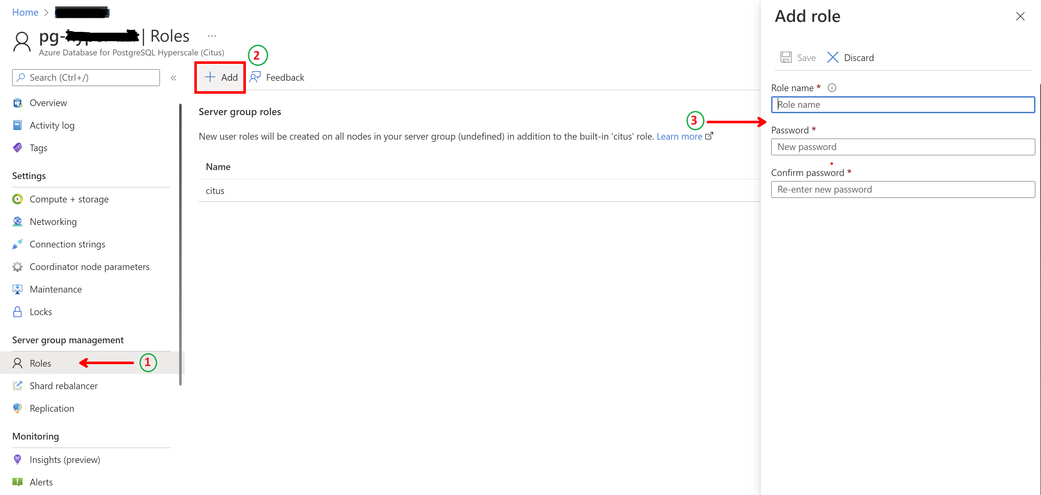
As shown below, once you navigate to the hyperscale server group on the portal –
Step 1 – click on ‘Roles’ under Server group management,
Step 2 – click on ‘+ Add’ to add new role
Step 3 – provide a name for the new role and assign a password to it.
For this exercise, we’ll create two roles, namely – tenant1 and tenant2. The reason we chose the role names is to ensure that shard key (in this case tenant_id) can be part of the name of the role and hence 1 and 2. You will see in the next section, why this is important.
Once this is done, grant privileges to these roles as needed.
Grant Required Privileges to the New Role(s):
Since we created a new schema to hold the distributed table, first step is to ensure that the new roles have access to this schema.
GRANT usage ON SCHEMA test1 TO tenant1, tenant2;
Without this step, if you try to assign privileges directly, PostgreSQL will return an error suggesting the role doesn’t have permission to access the schema.
Next, assign actual privileges on the table(s) to the roles.
GRANT SELECT, UPDATE, INSERT, DELETE
ON test1.events TO tenant1, tenant2;
At this time, we have given the required privileges on the table to the newly created roles. However, if a user logs in with these, they will be able to see all the data across shards.
This is where the row level security comes into picture.
Configure Row Level Security:
To ensure that the primary role (citus) has access to all the data when we add new roles and enable RLS, create a policy which is applicable to this role:
CREATE POLICY admin_all ON test1.events
TO citus — apply to this role
USING (true) — read any existing row
WITH CHECK (true);
Note that the policy will come into effect once row level security is enabled for the table.
The next step is to create a policy which will define the check on rows accessible by users.
CREATE POLICY user_mod ON test1.events
USING (current_user = ‘tenant’ || tenant_id::text);
— lack of CHECK means same condition as USING
The policy defines which rows user has access to as it concatenates string ‘tenant’ with the tenant_id column of the table. If you scroll back to where we created the roles and why we chose those names for the roles, it should make sense now.
And then finally enable the RLS on the table.
ALTER TABLE test1.events ENABLE ROW LEVEL SECURITY;
To further simplify this – the rows in the table have tenant_id values 1 or 2. Policy defines expression (‘tenant’ || ‘1’) as role name to have access to rows where tenant_id is 1 and so on. Of course, you need to create more roles as you keep adding rows to the table with different tenant IDs.
This check is pushed down to all the worked nodes in the hyperscale server group and will ensure that the access to the data is governed by the policy created by row level security.
This is it! Go ahead, login with the new role and try to fetch or change the rows in the table.
On the dummy data defined here, when ‘tenant1’ logs in and runs the following query –
SELECT * FROM test1.events;
The output is this –

This ensures that the role ‘tenant1’ only has access to rows with tenant_id being 1 and similarly role ‘tenant2’ will have access to rows with tenant_id being 2 and so on.
Stay tuned for more!
FastTrack for Azure: Move to Azure efficiently with customized guidance from Azure engineering. FastTrack for Azure – Benefits and FAQ | Microsoft Azure
by Contributed | Jun 17, 2022 | Technology
This article is contributed. See the original author and article here.
Earlier this year, we introduced 9 new out-of-box Trainable Classifiers for sensitive business document discovery and classification. These include Finance, IT, IP, Tax, Agreements, Healthcare, Procurement, and Legal Affairs.
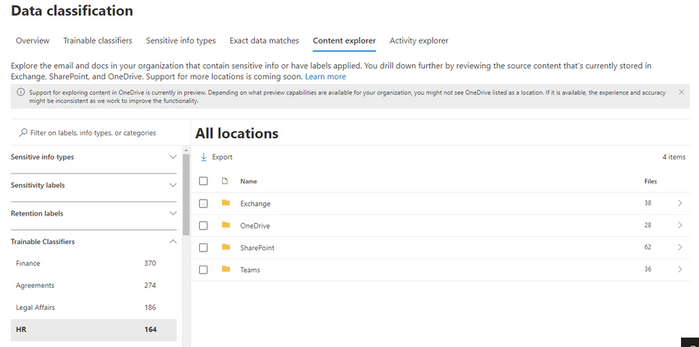
To make the discovery of your sensitive information easier, we are introducing data discovery with Trainable Classifiers in Content Explorer. This means that your sensitive documents that are classified by Trainable Classifiers can be viewed even if they are not used as conditions in an auto-labeling policy. This includes both pre-trained out-of-box models as well as custom trainable classifiers.
For each classifier, you can drill down from the location to the specific document that has been classified. If the classification is not what is expected, there is an opportunity to provide No-Match feedback so that we can further improve our classifiers. We currently have 11 out-of-box business document classifiers available for this feature with another 23 in private preview and another 30 that will be available for preview shortly.
These Trainable classifiers can be used for the discovery and classification of sensitive information across SPO and ODB by clicking on the respective classifier/category in Content Explorer.
Some of the Trainable Classifiers we plan to provide as built-in out-of-box include
- Intellectual property and trade secrets such as Project Documents, Standard Operating Procedures, Software Product Development Files, Network Design documents
- Business-critical documents such as M&A files, Business Plan, Strategic Planning Documents, Meeting Notes Statement of Work, Financial Statements, Manufacturing batch records, Customer account Files, Market research reports
- Sensitive business content as part of daily business operations such as Payroll, Invoice, Statement of Work, Financial Statements, Statement of Accounts, Employee Performance Files, Facility Permits

Customers can opt-out of this feature by raising a support ticket with this request and this feature can be turned off for their tenant.
Thanks for reading!


Recent Comments