This article is contributed. See the original author and article here.
Labeled data is critical to training supervised learning models. Higher volumes and more accurate labeled data contribute to more accurate models but labeling data has traditionally been time-intensive and error-prone.
With Data Labeling in Azure Machine Learning, you now have a central place to create, manage, and monitor labeling projects. You can now manage data labeling projects seamlessly from within the studio web experience to generate and manage tasks reducing the back-and-forth of labelling data offline. With AML Data Labeling, you can load and label data and be ready to train in minutes.
To increase productivity and decrease costs for a given task, the Assisted Machine Learning labeling feature allows you to leverage automatic machine learning models to accelerate labeling by clustering like objectives and automatically prelabeling data when the underlying model has reached high confidence. This feature is available for image classification (multi-class or multi-label) and Object detection tasks, in Enterprise edition workspaces.

Data Labeling in Azure Machine learning now includes below capabilities:
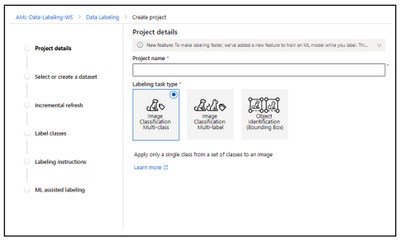
Image Classification Multi-Class
This project type helps you to categorize an image when you want to apply only a single class from a set of classes to an image.

Image Classification Multi-label
This project type allows you to categorize an image when you want to apply one or more labels from a set of classes to an image. For instance, a photo of a dog might be labeled with both dog and land.

Object Identification (Bounding Box)
Use this project type when you want to assign a class and a bounding box to each object within an image. If your project is of type “Object Identification (Bounding Boxes),” you’ll specify one or more bounding boxes in the image and apply a tag to each box. Images can have multiple bounding boxes, each with a single tag.

Assisted machine learning
The machine assisted labeling lets you trigger automatic machine learning models to accelerate the labeling task. At the beginning of your labeling project, the images are shuffled into a random order to reduce potential bias. However, any biases that are present in the dataset will be reflected in the trained model. For example, if 80% of your images are of a single class, then approximately 80% of the data used to train the model will be of that class. This training does not include active learning.
Enabling ML assisted labeling consists of two phases:
- Clustering
- Prelabeling
The exact number of labeled images necessary to start assisted labeling is not a fixed number. This can vary significantly from one labeling project to another. ML Assisted Labeling uses a technique called Transfer Learning, and the pre-labeling will be triggered when sufficient confidence is achieved which varies based on the dataset.
Since the final labels still rely on input from the labeler, this technology is sometimes called human in the loop labeling.
Clustering
After a certain number of labels are submitted manually, the machine learning model for image classification starts to group together similar images. These similar images are presented to the labelers on the same screen to speed up manual tagging. Clustering is especially useful when the labeler is viewing a grid of 4, 6, or 9 images.
The clustering phase does not appear for object detection models.
Prelabeling
After enough image labels are submitted, a classification model is used to predict image tags. Or an object detection model is used to predict bounding boxes. The labeler now sees pages that contain predicted labels already present on each image. For object detection, predicted boxes are also shown. Accuracy will vary depending images, labels, the domain, and other factors. With Pre-Labeling, you can review the predictions before committing the labels.
Once a machine learning model has been trained on your manually labeled data, the model is evaluated on a test set of manually labeled images to determine its accuracy at a variety of different confidence thresholds. This evaluation process is used to determine a confidence threshold above which the model is accurate enough to show pre-labels. The model is then evaluated against unlabeled data. Images with predictions more confident than this threshold are used for pre-labeling.
Resources
Learn more about the Azure Machine Learning service.
Get started with a free trial of the Azure Machine Learning service.
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments