This article is contributed. See the original author and article here.
We use a combination of the Purview REST API (via JMESPath), and the Client object to achieve getting the full list of Assets from Purview, and iterating to populate the corresponding metadata per Asset.
Scenario 1: Column asset classifications
GitHub gist: full script
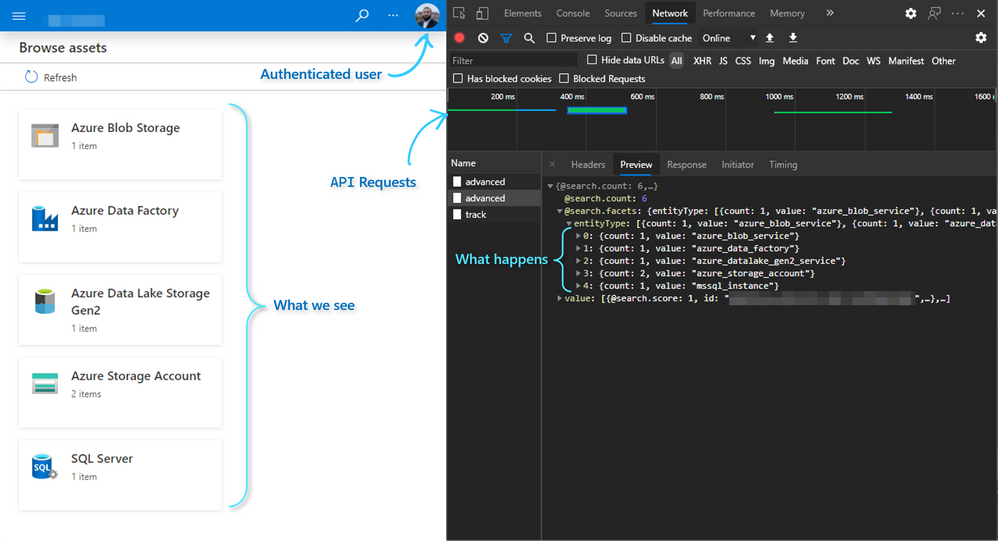
Here’s a summarized view of what we achieve:

Extracting metadata from Purview with Synapse Spark Pools using Python
Let’s look at the relevant components from the script.
The first function azuread_auth is straightforward and not Purview specific – it simply allows us to authenticate to Azure AD using our Service Principal and the Resource URL we want to navigate (in this case, Purview: https://purview.azure.net:(
def azuread_auth(tenant_id: str, client_id: str, client_secret: str, resource_url: str):
"""
Authenticates Service Principal to the provided Resource URL, and returns the OAuth Access Token
"""
url = f"https://login.microsoftonline.com/{tenant_id}/oauth2/token"
payload= f'grant_type=client_credentials&client_id={client_id}&client_secret={client_secret}&resource={resource_url}'
headers = {
'Content-Type': 'application/x-www-form-urlencoded'
}
response = requests.request("POST", url, headers=headers, data=payload)
access_token = json.loads(response.text)['access_token']
return access_tokenWe’re going to be passing around the access_token returned above every time we make a call to Purview’s REST API.
Next, we leverage PyApacheAtlas to return a client using purview_auth:
def purview_auth(tenant_id: str, client_id: str, client_secret: str, data_catalog_name: str):
"""
Authenticates to Atlas Endpoint and returns a client object
"""
oauth = ServicePrincipalAuthentication(
tenant_id = tenant_id,
client_id = client_id,
client_secret = client_secret
)
client = PurviewClient(
account_name = data_catalog_name,
authentication = oauth
)
return clientOnce we have our proof of authentication (access_token and client) – we’re ready to programmatically access the Purview REST API.
We use get_all_adls_assets to recursively retrieve all scanned assets from our Data Lake from the Purview REST API.
Note: this function intentionally traverses the tree structure until only assets remain (i.e. no folders are returned, only files).
The function below applies the simple recursion techniques I outlined in this article against our Data Lake and Purview API to retrieve asset names and schemas.
While this is fine for exploration, due diligence (i.e. implementing a more optimal, piecemeal approach) should be applied for Production implementations on a case-by-case basis to avoid long-running jobs.
The API parameter used to determine whether we hit the end is isLeaf:
def get_all_adls_assets(path: str, data_catalog_name: str, azuread_access_token: str, max_depth=1):
"""
Retrieves all scanned assets for the specified ADLS Storage Account Container.
Note: this function intentionally recursively traverses until only assets remain (i.e. no folders are returned, only files).
"""
# List all files in path
url = f"https://{data_catalog_name}.catalog.purview.azure.com/api/browse"
headers = {
'Authorization': f'Bearer {azuread_access_token}',
'Content-Type': 'application/json'
}
payload="""{"limit": 100,
"offset": null,
"path": "%s"
}""" % (path)
response = requests.request("POST", url, headers=headers, data=payload)
li = json.loads(response.text)
# Return all files
for x in jmespath.search("value", li):
if jmespath.search("isLeaf", x):
yield x
# If the max_depth has not been reached, start
# listing files and folders in subdirectories
if max_depth > 1:
for x in jmespath.search("value", li):
if jmespath.search("isLeaf", x):
continue
for y in get_all_adls_assets(jmespath.search("path", x), data_catalog_name, azuread_access_token, max_depth - 1):
yield y
# If max_depth has been reached,
# return the folders
else:
for x in jmespath.search("value", li):
if jmespath.search("!isLeaf", x):
yield xNote a couple points regarding this function:
We can further expand the implementation by abstracting away the data source and making
source_typeinto a parameter (i.e. besides ADLS, we can query metadata about other sources supported on Purview – e.g. SQL DB, Cosmos DB etc.).
We’ll just need to deal with curating the
payloadon a case-by-case basis, but the basic premise remains the same.
Note the
limit: 100parameter is there because I didn’t want to deal with API Pagination logic (the demo Data Lake is small).
This parameter can be increased for larger implementations up until we hit the upper limit defined by the API – at which point we need to implement pagination best practices into our script logic (no different than other Azure/non-Azure APIs).
For deeper folder structures,
max_depthcan be increased as desired
Once we have a list of all our assets, we can iterate through the list and retrieve the Schema and Classification from Purview inline:
files_df['schema'] = files_df.apply(lambda row: get_adls_asset_schema(assets_all, row['asset'], atlas_client), axis=1)Where we use the client object we defined earlier to call get_adls_asset_schema:
def get_adls_asset_schema(assets_all: list, asset: str, purview_client: str):
"""
Returns the asset schema and classifications from Purview
"""
# Filter response for our asset of interest
assets_list = list(filter(lambda i: i['name'] == asset, assets_all))
# Find the guid for the asset to retrieve the tabular_schema or attachedSchema (based on the asset type)
match_id = ""
for entry in assets_list:
# Retrieve the asset definition from the Atlas Client
response = purview_client.get_entity(entry['id'])
# API response is different based on the asset
if asset.split('.', 1)[-1] == "json":
filtered_response = jmespath.search("entities[?source=='DataScan'].[relationshipAttributes.attachedSchema[0].guid]", response)
else:
filtered_response = jmespath.search("entities[?source=='DataScan'].[relationshipAttributes.tabular_schema.guid]", response)
# Update match_id if source is DataScan
if filtered_response:
match_id = filtered_response[0][0]
# Retrieve the schema based on the guid match
response = purview_client.get_entity(match_id)
asset_schema = jmespath.search("[referredEntities.*.[attributes.name, classifications[0].[typeName][0]]]", response)[0]
return asset_schemaNote a couple takeaways from here:
JMESPath is awesome
The Atlas API response is slightly different based on the filetype (e.g.
jsonvscsv), hence we deal with it case-by-case.
This makes sense, since
jsontechnically hasattachedSchema(i.e. Schema that comes as a part of the object itself), whereascsvis of typetabular_schema(i.e. Schema that Purview had to infer)
Finally, once the functions are done calling the API, we can call a display(files_df) on our DataFrame to get back the final output:

Final Output
Note:
files_dfis a Pandas DataFrame, but we can easily convert to Spark withfiles_df = spark.createDataFrame(files_df).
Shouldn’t make a difference for our purposes since the DataFrame is small.
Scenario 2: Purview Insights
GitHub gist: full script
Our goal is to create this Power BI Report – which provides us with the same data that Purview Studio makes visually available to us. The idea here is for us to be able to leverage the ability of Power BI to create Custom Reports:

Demo Power BI Report generated from Purview Insights data
We simply specify the script as a Python Data source – where the script is structured such that it queries Purview’s APIs to produce Pandas Dataframes:

Using the Python Script as a Power BI Data Source
Note: We acknowledge that this method of data extraction is experimental in nature, and is definitely not suitable for ingesting a large amount of data into Power BI.
In our case, since the Insights data is pre-computed by the Purview Engine already, this serves the end goal of creating simple Custom Reports (i.e. our Python script doesn’t have to work very hard to extract this data).
Finally, we can refresh this Power BI report as needed, to ingest the latest data points from Purview:

Refreshing the Power BI dataset, which executes the underlying Python query
Wrap Up
We explored how to call the Purview REST API with Python to programmatically obtain Purview Asset Metadata – i.e. Schema and Classifications into Synapse as a DataFrame. We also looked at how we can apply the same techniques to ingest data from Purview Insights, and create custom Power BI dashboards with ease.
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments