This article is contributed. See the original author and article here.
In this article, I would be talking about how can we write data from ADLS to Azure Synapse dedicated pool using AAD . We will be looking at direct sample code that can help us achieve that.
1. First step would be to import the libraries for Synapse connector. This is an optional statement.

2. Next step is to initialize variable to create/read data frames
Note : Above step can also be written in below format :
3. Next step would be to use the write api in below format :

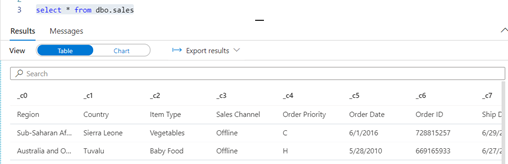
Execute the cell and you will be able to see the new table with data popped up:
Observation in Driver log with this exercise:

We find external data source, file format and external table created as well as dropped during this automated process.
More information about other options for dedicated pool and server less related read/write API’s in SPARK can be found out on this page.
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments