This article is contributed. See the original author and article here.
When Azure Analysis Services is processing, how do you know where there are opportunities for improvement? A typical design pattern is to process AAS to ensure that it is fully ready for users, although AAS can be processed asynchronously in a trigger-based cloud world. When Azure Analysis Services sends telemetry data to Log Analytics, the logs can be analyzed to find where the timing is taking for Analysis Services processing. The language for Azure Monitor is Kusto, which is also used for a few other Microsoft services as well (Azure Data Explorer, Application Insights, etc.)
For example, finding all the Refresh commands that were executed against an instance would look something like the below:
AzureDiagnostics
| where ResourceProvider == "MICROSOFT.ANALYSISSERVICES"
| where EventClass_s == "COMMAND_END"
| extend DurationMs=extract(@"([^,]*)", 1,Duration_s, typeof(long))
| project RootActivityId_g, TextData_s, StartTime_t, EndTime_t
| where TextData_s contains "Refresh"
| where StartTime_t <> todatetime('1601-01-01T00:00:00Z')

The result provides an excellent overview of how long the processing is taking. However, we’re looking for something a bit deeper. What partitions/tables are taking the longest to process?
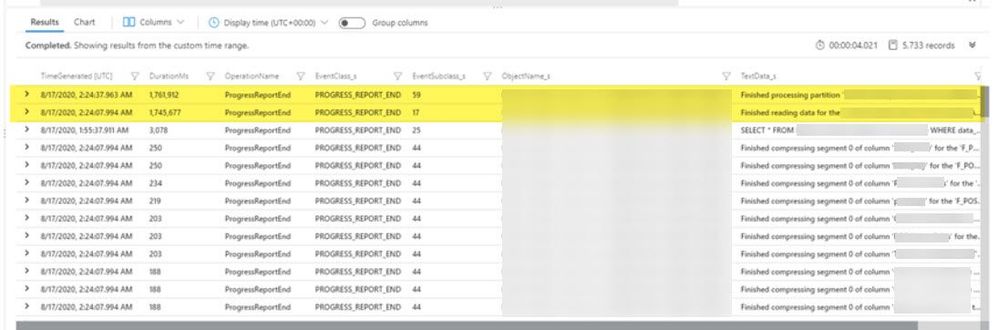
//use the below query to identify the processing time per partition in the model. The DurationMs report the number of milliseconds that elapsed to perform the processing. This query shows a detailed breakdown per partition, showing the amount of time spent running the SQL query, transferring data over the network, and compressing the data.
AzureDiagnostics
| where ResourceProvider == "MICROSOFT.ANALYSISSERVICES"
//capture progress reort end events and event subclass 59.
| where EventClass_s == "PROGRESS_REPORT_END" and ((EventSubclass_s == 17 and TextData_s contains "reading") or (EventSubclass_s == 25 and TextData_s contains "SELECT") or (EventSubclass_s == 59 and TextData_s contains "partition") or EventSubclass_s == 44 or EventSubclass_s == 6)
| extend DurationMs=extract(@"([^,]*)", 1,Duration_s, typeof(long))
| summarize count() by OperationName, EventClass_s, EventSubclass_s, DurationMs, ObjectName_s, TextData_s, TimeGenerated
| order by ObjectName_s, DurationMs

To make this a bit easier to understand, I’ve created a Power BI report that connects to a log analytics workspace and runs the Kusto mentioned above. Paste in the workspace URL into the parameter, and refresh the report. It is left pretty vanilla out of the box. In real life, this could be combined with all sorts of useful information to create an AAS “Dashboard” showing number of users, query duration percentiles, processing performance, etc.

The above query breaks down where the data is spending time processing at the partition level. When AAS is processing data, time is spent on three different categories:
- Executing SQL
- Reading the data from the source.
- Compressing the data into segments
Execute SQL is the very first step in the process, which is the amount of time that it takes the underlying data source to return the very first row to the AAS engine. If the latency here is long, the partition’s underlying SQL statement takes a long time to run. One of the first places to look is at the partition definitions in AAS, although the query could also be tuned at the database layer to return the data faster.
The second category you see is Reading data. Reading data is encapsulated in event subclass 17 and indicates the time that AAS was waiting for the entire dataset to be retrieved. There are a few potential bottlenecks to investigate here. A few quick places to look:
- Check the on-premises data gateway performance counters and look for CPU, Memory, and Networking to look for the box’s oversaturation. For reading data bottlenecks, this should ALWAYS be the first place to look.
- Check to see if the data gateway is streaming or spooling. This can be set via the StreamBeforeRequestCompletes property that exists in the %/On-Premises data gatewayMicrosoft.PowerBI.DataMovement.Pipeline.GatewayCore.dll.config file. False indicates the data is spooled locally to the gateway before the data packets are sent to the destination (Analysis Services); True indicates the data is streamed directly to the destination without spooling first.
The last step in Analysis Services Processing is compressing the various segments for columnar compression. Compression occurs after all the data has been read into Analysis Services and is handled via the Formula Engine. Have you ever processed an AS database and noticed that after it says all the data has been retrieved, it just looks like it sits there? That’s compression being applied. Some ways this can be reduced are:
- Only include columns that will be used in OLAP queries. Although the business generally asks for “all the columns,” only about 10% of these are used in reality. By analyzing the query log data, unused columns can be removed from the model or answered via direct queries to the source rather than using up valuable processing time.
- Avoid columns with lots of unique values. Vertipaq (the underlying engine behind AS) is a columnar based engine. It achieves high compression rates by storing only distinct values within a column/table. Because of this, fact tables generally compress at a much higher rate than dimension tables. Dimensions with large string values and lots of columns have the worst compression. This is also why one big table of all the things is wrong in Power BI! ;)
- Set the coding hint appropriately. See the docs page for more details, but without going into too much detail, Value Encoding is better for numerical, aggregating columns (facts) and hash encoding is better for everything else. I have personally seen the optimization of this alone result in a processing reduction of 20-30%.
The report and code samples I shared above are hosted within a GitHub repository here.
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments