This article is contributed. See the original author and article here.
Abstract
With the Azure Machine Learning service, the training and scoring of hundreds of thousands of models with large amounts of data can be completed efficiently leveraging pipelines where certain steps like model training and model scoring run in parallel on large scale out compute clusters. In order to help organizations get a head start on building such pipelines, the Many Models Solution Accelerator has been created. The Many Models Solution Accelerator provides two primary examples, one using custom machine learning and the other using AutoML. Give it a try today!
Executive Overview
Many executives are looking to Machine Learning to improve their business. With the reliance on a more digital world, the amount of data generated is increasing faster than ever. Further, companies are purchasing 3rd party datasets to combine with internal data to gain further insight and make better predictions. In order to make better predictions, sophisticated machine learning models are being built that leverages this large pool of data. Further, as companies are expanding to do business in a variety of markets and environments, general machine learning model no longer suffice, instead, more specific machine learning models are needed. In this case, “general machine learning models” refers to the granularity for which this model was built, for example, building a demand forecast model for a product at the country level versus at the city level which would be a “specific machine learning model.” Building more specific machine learning models can easily results in building hundreds of thousands of specific models instead of a handful of general models. Combining large datasets with the need of building hundreds of thousands of more specific machine learning models is not a trivial task. Doing so requires very large compute power. In fact, this task can greatly benefit from parallel compute power where multiple compute instances are working simultaneously to build the machine learning models in parallel. Once those models are trained, leveraging them to score large amounts of data presents the same problem characteristics which again, leveraging a compute cluster where multiple compute instances are making predictions using the machine learning models simultaneously can greatly reduce the time required to do so. With the Azure Machine Learning service, the training and scoring of hundreds of thousands of models with large amounts of data can be completed efficiently leveraging pipelines where certain steps like model training and model scoring run in parallel on large scale out compute clusters. In order to help organizations get a head start on building such pipelines, the Many Models Solution Accelerator has been created. The Many Models Solution Accelerator provides two primary examples, one using custom machine learning and the other using AutoML.
In Azure Machine Learning, AutoML automates the building of the most common categories of Machine Learning models in a very robust and sophisticated manner. For example, a very common machine learning problem is demand forecasting. Having a more accurate demand forecast can increase revenues and reduce waste. Traditionally, many statistical methods have been used to do just this. However, more modern techniques leverage Machine Learning including Deep Learning techniques to provide a more accurate demand forecast. Further, the demand forecast can be improved by moving from forecasting a broader scope (general machine learning model) to forecasting a more granular scope (specific machine learning model). Doing so means, for example, instead of building one forecast for each Product at the country level, building a forecast for each product at the city. Moving to more specific models results in building hundreds of thousands of forecasts using large amounts of data which as discussed above can be solved using the Many Models Solution Accelerator.
Technical Overview
As data scientist move from building a handful of general machine learning models to hundreds of thousands of more specific machine learning models (i.e. geography or product scope), the need to perform the model training and model scoring tasks require parallel compute power to finish in a timely manner. In the Azure Machine Learning service SDK, this is accomplished using Pipelines and specifically a ParallelRunStep which runs on a multi node Compute Clusters. The data scientist provides the ParallelRunStep a custom script, an input dataset, a compute cluster and the amount of parallelism they would like. This concept can be applied to a custom python script and to Automated Machine Learning (AutoML).
Automated Machine Learning (AutoML) uses over ten algorithms (including deep learning algorithms) with varying hyperparameters to build Classification, Regression and Forecasting models. Further, Pipelines automate the invocation of AutoML across multiple nodes using ParallelRunStep to train the models in parallel as well as to batch score new data. Pipelines can be scheduled to run within Azure Machine Learning or invoked using their REST endpoint from various Azure services (i.e. Azure Data Factory, Azure DevOps, Azure Functions, Azure Logic Apps, etc). When invoked, the Parallel Pipelines run on Compute Clusters within Azure Machine Learning. The Compute clusters can be scaled up and out to perform the training and scoring. Each node in a compute clusters can be have Terabytes of RAM, over a 100 cores, and multiple GPUs. Finally, the scored data can be stored in an a datastore in Azure, such as Azure DataLake Gen 2, and then copied to a specific location for an application to consume the results.
In order to provide a jump start in leveraging Pipelines with the new ParallelRunStep, the Many Models Solution Accelerator has been created. This solution accelerator showcases both a custom python script and an AutoML script.
Major Components
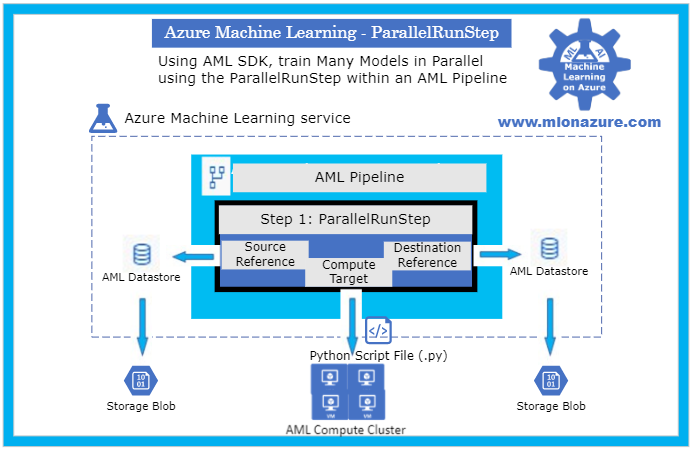
The main components of the Many Models Solution Accelerator includes an Azure Machine Learning Workspace, a Pipeline, a ParallelRunStep, a Compute Target, a Datastore, and a Python Script File as depicted in Figure 1, below.

Figure 1. The architecture of a Pipeline with a ParallelRunStep
For an overview of getting started with Azure Machine Learning service, please see the blog article MLonAzure: Getting Started with Azure Machine Learning service for the Data Scientist
For an overview of Pipelines, please see blog article, MLonAzure: Azure Machine Learning service Pipelines
Major Steps
1. Prerequisites
- An Azure Subscription along with an Azure Machine Learning Workspace are needed to get started. To get started with Azure Machine Learning, see Getting Started with Azure Machine Learning services
- Within the Azure Machine Learning, a Compute Instance needs to be created to serve as the Data Scientist’s workstation. Using the Compute Instance, clone the Many Models Solution Accelerator Github repository.
2. Data Prep
- Data needs to be split into multiple files (.csv or .parquet) for each group that a model is to be created for. Each file must contain one or more entire time series for the give group.
- The data must be placed in Azure Storage (e.g. ADL Gen 2, Blob Storage). The storage will then be registered as a Datastore from which two FileDatasets will be registered, one pointing to the folder containing the training data and the other to the folder containing the data to be scored.
- For example, to build a forecast model for each brand within a store, the training sales data would be split to create files StoreXXXX_BrandXXXX.
3. Model Training
The solution accelerator showcases model training with a custom python script and with AutoML which are orchestrated using a Pipeline. Please see solution-accelerator-manymodels-customscript and solution-accelerator-manymodels-AutoML. Putting it all together results in the architecture depicted in Figure 2, below.

Figure 2: Solution Accelerator Model Training
3. a. Pipeline
The solution accelerator leverages the Pipeline object to train the model. Specifically, a ParallelRunStep is used which requires a configuration parameters, ParallelRunConfig
ParallelRunConfig has many parameters, below are the typical ones used for the Many Models Solution Accelerator. For a complete list of ParallelRunConfig parameters, please see the ParallelRunConfig Class.
|
Parameter |
Explanation |
|
environment |
Provides the configurations for the Python Environment |
|
Entry_script |
This is a Python file (.py extension only) that will run in parallel. Note that the Many Models Solution Accelerator contains a custom Entry_script that leverages AutoML and one that leverages custom code. |
|
Compute_target |
The AML ComputeCluster to run the step on. |
|
Node_count |
The number of nodes to use within the training cluster. Scale this number to a higher number to increase parallelism. |
|
Process_count_per_node |
The number of cores that will be used within each node |
|
mini_batch_size |
For FileDatasets it’s the number of files that are used at a time, for Tabular Datasets it’s the number data size that will be processed at a given time. |
|
Run_inovcation_timeout |
The overall allowed time for the parallel run step |
3. b. Training script with AutoML
The solution accelerator showcases using AutoML Forecasting. AutoML has many parameters, below are the typical ones used for doing a Forecasting task within the Many Models Solution Accelerator. For a complete list of AutoML Config parameters, please see the AutoMLConfig Class.
automl_settings = {
"task" : 'forecasting',
"primary_metric" : 'normalized_root_mean_squared_error',
"iteration_timeout_minutes" : 10,
"iterations" : 15,
"experiment_timeout_hours" : 1,
"label_column_name" : 'Quantity',
"n_cross_validations" : 3,
"verbosity" : logging.INFO,
"debug_log": 'DebugFileName.txt',
"time_column_name": 'WeekStarting',
"max_horizon" : 6,
"group_column_names": ['Store', 'Brand'],
"grain_column_names": ['Store', 'Brand']
}
|
Parameter |
Explanation |
|
task |
The type of AutoML Task: Classification, Regression, Forecasting |
|
primary_metric |
The metric that AutoML should optimize based on |
|
Iteration_timeout_minutes |
How long each of the number of “iterations” can run for |
|
Iterations |
Number of models that should be tried (combinations of various Algorithms + various Hyperparameters) |
|
Experiment_timeout_hours |
How long the overall AutoML Experiment can take. Note: The experiment may might timeout before all iterations are complete. |
|
label_column_name |
The column that is being predicted |
|
n_cross_validations |
Number of cross validations that should take place within the training dataset |
|
verbosity |
Log details |
|
debug_log |
Location for the debug log |
|
time_column_name |
The name of the Time column, note that the training dataset can have multiple time series |
|
max_horizon |
How far how the forecast will go |
|
group_column_names |
The names of columns used to group your models. For timeseries, the groups must not split up individual time-series. That is, each group must contain one or more whole time-series. |
|
grain_column_names |
The column names used to uniquely identify timeseries in data that has multiple rows with the same timestamp. |
4. Model Forecasting
The solution accelerator showcases model forecasting with a custom python script and with AutoML which are orchestrated using a Pipeline. Please see solution-accelerator-manymodels-customscript and solution-accelerator-manymodels-AutoML. Putting it all together results in the architecture depicted in Figure 3, below.

Figure 3: Solution Accelerator Model Scoring
5. Automation
In order to automate the solution, the training and scoring pipelines must be published and a PipelineEndPoint must be created. Once that’s done, the PipelineEndpoint can then be invoked from Azure Data Factory. Specifically, the Azure Machine Learning Pipeline Activity is used. Note that the training and scoring pipelines can be collapsed into one pipelines if the training and scoring occur consecutively.
Next Steps
Azure Machine Learning Documentation
Many Models Solution Accelerator
Many Models Solution Accelerator Video
Azure Data Factory: Azure Machine Learning Pipeline Activity
MLOnAzure GitHub: Getting started with Pipelines
MLonAzure Blog: Getting Started with Azure Machine Learning for the Data Scientist
MLonAzure Blog: Azure Machine Learning service Pipelines
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments