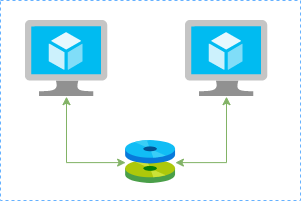
Configuring a GlusterFS using Azure Shared Disks on Ubuntu Linux
This article is contributed. See the original author and article here.
In this article I’ll show you how to create a redundtant storage pool using GlusterFS and Azure Shared Disks. GlusterFS is a network-attached storage filesystem that allows you to pool storage resources of multiple machines. Azure shared disks is a new feature for Azure managed disks that allows you to attach a managed disk to multiple virtual machines (VMs) simultaneously. Please note that enabling shared disks is only available to a subset of disk types. Currently only ultra disks and premium SSDs can enable shared disks. Check if the VM type you are planning to use support ultra or premium disks.
Our setup will consist in:
- An Azure Resource Group containing the resources
- An Azure VNET and a Subnet
- An Availability Set into a Proximity Placement Group
- 2 Linux VMs (Ubuntu 18.04)
- 2 Public IPs (one for each VM)
- 2 Network Security Groups (1 per VM Network Interface Card)
- A Shared Data Disk attached to the both VMs
I’ll be using the Azure Cloud Shell once is fully integrated to Azure and with all modules I need already installed.
Create SSH key pair
ssh-keygen -t rsa -b 4096
Create a resource group
New-AzResourceGroup -Name “myResourceGroup” -Location “EastUS”
Create virtual network resources
Create a subnet configuration
$subnetConfig = New-AzVirtualNetworkSubnetConfig `
-Name “mySubnet” `
-AddressPrefix 192.168.1.0/24
Create a virtual network
$vnet = New-AzVirtualNetwork `
-ResourceGroupName “myResourceGroup” `
-Location “EastUS” `
-Name “myVNET” `
-AddressPrefix 192.168.0.0/16 `
-Subnet $subnetConfig
Create a public IP address for the VM01
$pip01 = New-AzPublicIpAddress `
-ResourceGroupName “myResourceGroup” `
-Location “EastUS” `
-AllocationMethod Static `
-IdleTimeoutInMinutes 4 `
-Name “mypublicip01”
Create a public IP address for the VM02
$pip02 = New-AzPublicIpAddress `
-ResourceGroupName “myResourceGroup” `
-Location “EastUS” `
-AllocationMethod Static `
-IdleTimeoutInMinutes 4 `
-Name “mypublicip02”
Create an inbound network security group rule for port 22
$nsgRuleSSH = New-AzNetworkSecurityRuleConfig `
-Name “myNetworkSecurityGroupRuleSSH” `
-Protocol “Tcp” `
-Direction “Inbound” `
-Priority 1000 `
-SourceAddressPrefix * `
-SourcePortRange * `
-DestinationAddressPrefix * `
-DestinationPortRange 22 `
-Access “Allow”
Create a network security group for the VM01
$nsg = New-AzNetworkSecurityGroup `
-ResourceGroupName “myResourceGroup” `
-Location “EastUS” `
-Name “myNetworkSecurityGroup01” `
-SecurityRules $nsgRuleSSH
Create a network security group for the VM02
$nsg = New-AzNetworkSecurityGroup `
-ResourceGroupName “myResourceGroup” `
-Location “EastUS” `
-Name “myNetworkSecurityGroup02” `
-SecurityRules $nsgRuleSSH
Create a virtual network card for VM01 and associate with public IP address and NSG
$nic01 = New-AzNetworkInterface `
-Name “myNic01” `
-ResourceGroupName “myResourceGroup” `
-Location “EastUS” `
-SubnetId $vnet.Subnets[0].Id `
-PublicIpAddressId $pip01.Id `
-NetworkSecurityGroupId $nsg.Id
Create a virtual network card for VM02 and associate with public IP address and NSG
$nic02 = New-AzNetworkInterface `
-Name “myNic02” `
-ResourceGroupName “myResourceGroup” `
-Location “EastUS” `
-SubnetId $vnet.Subnets[0].Id `
-PublicIpAddressId $pip02.Id `
-NetworkSecurityGroupId $nsg.Id
Create availability set for the virtual machines.
$set = @{
Name = ‘myAvSet’
ResourceGroupName = ‘myResourceGroup’
Location = ‘eastus’
Sku = ‘Aligned’
PlatformFaultDomainCount = ‘2’
PlatformUpdateDomainCount = ‘2’
}
$avs = New-AzAvailabilitySet @set
Create the first virtual machine (myVM01)
Define a credential object
$securePassword = ConvertTo-SecureString ‘ ‘ -AsPlainText -Force
$cred = New-Object System.Management.Automation.PSCredential (“azureuser”, $securePassword)
Create a virtual machine configuration
$vmConfig = New-AzVMConfig `
-AvailabilitySetId $avs.Id `
-VMName “myVM01” `
-VMSize “Standard_D4s_v3” | `
Set-AzVMOperatingSystem `
-Linux `
-ComputerName “myVM01” `
-Credential $cred `
-DisablePasswordAuthentication | `
Set-AzVMSourceImage `
-PublisherName “Canonical” `
-Offer “UbuntuServer” `
-Skus “18.04-LTS” `
-Version “latest” | `
Add-AzVMNetworkInterface `
-Id $nic01.Id
Configure the SSH key
$sshPublicKey = cat ~/.ssh/id_rsa.pub
Add-AzVMSshPublicKey `
-VM $vmconfig `
-KeyData $sshPublicKey `
-Path “/home/azureuser/.ssh/authorized_keys”
Create the VM
New-AzVM `
-ResourceGroupName “myResourceGroup” `
-Location eastus -VM $vmConfig
Create the second virtual machine (myVM02)
Define a credential object
$securePassword = ConvertTo-SecureString ‘ ‘ -AsPlainText -Force
$cred = New-Object System.Management.Automation.PSCredential (“azureuser”, $securePassword)
Create a virtual machine configuration
$vmConfig = New-AzVMConfig `
-AvailabilitySetId $avs.Id `
-VMName “myVM02” `
-VMSize “Standard_D4s_v3” | `
Set-AzVMOperatingSystem `
-Linux `
-ComputerName “myVM02” `
-Credential $cred `
-DisablePasswordAuthentication | `
Set-AzVMSourceImage `
-PublisherName “Canonical” `
-Offer “UbuntuServer” `
-Skus “18.04-LTS” `
-Version “latest” | `
Add-AzVMNetworkInterface `
-Id $nic02.Id
Configure the SSH key
$sshPublicKey = cat ~/.ssh/id_rsa.pub
Add-AzVMSshPublicKey `
-VM $vmconfig `
-KeyData $sshPublicKey `
-Path “/home/azureuser/.ssh/authorized_keys”
Create the VM
New-AzVM `
-ResourceGroupName “myResourceGroup” `
-Location eastus -VM $vmConfig
Create a Shared Data Disk
$dataDiskConfig = New-AzDiskConfig -Location ‘EastUS’ -DiskSizeGB 1024 -AccountType Premium_LRS -CreateOption Empty -MaxSharesCount 2
New-AzDisk -ResourceGroupName ‘myResourceGroup’ -DiskName ‘mySharedDisk’ -Disk $dataDiskConfig
Attach the Data Disk to VM01
$dataDisk = Get-AzDisk -ResourceGroupName “myResourceGroup” -DiskName “mySharedDisk”
$VirtualMachine = Get-AzVM -ResourceGroupName “myResourceGroup” -Name “myVM01”
Add-AzVMDataDisk -VM $VirtualMachine -Name “mySharedDisk” -CreateOption Attach -ManagedDiskId $dataDisk.Id -Lun 0
update-AzVm -VM $VirtualMachine -ResourceGroupName “myResourceGroup”
Attach the Data Disk to VM02
$dataDisk = Get-AzDisk -ResourceGroupName “myResourceGroup” -DiskName “mySharedDisk”
$VirtualMachine = Get-AzVM -ResourceGroupName “myResourceGroup” -Name “myVM02”
Add-AzVMDataDisk -VM $VirtualMachine -Name “mySharedDisk” -CreateOption Attach -ManagedDiskId $dataDisk.Id -Lun 0
update-AzVm -VM $VirtualMachine -ResourceGroupName “myResourceGroup”
Create a proximity placement group
$ppg = New-AzProximityPlacementGroup -Location “EastUS” -Name “myPPG” -ResourceGroupName “myResourceGroup” -ProximityPlacementGroupType Standard
Move the existing availability set into a proximity placement group
$resourceGroup = “myResourceGroup”
$avSetName = “myAvSet”
$avSet = Get-AzAvailabilitySet -ResourceGroupName $resourceGroup -Name $avSetName
$vmIds = $avSet.VirtualMachinesReferences
foreach ($vmId in $vmIDs){
$string = $vmID.Id.Split(“/”)
$vmName = $string[8]
Stop-AzVM -ResourceGroupName $resourceGroup -Name $vmName -Force
}
$ppg = Get-AzProximityPlacementGroup -ResourceGroupName myResourceGroup -Name myPPG
Update-AzAvailabilitySet -AvailabilitySet $avSet -ProximityPlacementGroupId $ppg.Id
foreach ($vmId in $vmIDs){
$string = $vmID.Id.Split(“/”)
$vmName = $string[8]
Start-AzVM -ResourceGroupName $resourceGroup -Name $vmName
}
Configure the Disk on Linux VM01
ssh azureuser@13.82.29.9
Find the disk
lsblk -o NAME,HCTL,SIZE,MOUNTPOINT | grep -i “sd”
Partition a new disk
sudo parted /dev/sdb –script mklabel gpt mkpart xfspart xfs 0% 100%
sudo mkfs.xfs /dev/sdb1
sudo partprobe /dev/sdb1
Mount the disk
sudo mkdir /datadrive
sudo mount /dev/sdb1 /datadrive
Ensure mounting during the boot
sudo blkid
The ouput should be something similar to:
/dev/sdc1: LABEL=”cloudimg-rootfs” UUID=”5a9997c3-aafd-46e9-954c-781f2b11fb68″ TYPE=”ext4″ PARTUUID=”cbc2fcb7-e40a-4fec-a370-51888c246f12″
/dev/sdc15: LABEL=”UEFI” UUID=”2FBA-C33A” TYPE=”vfat” PARTUUID=”53fbf8ed-db79-4c52-8e42-78dbf30ff35c”
/dev/sda1: UUID=”c62479eb-7c96-49a1-adef-4371d27509e6″ TYPE=”ext4″ PARTUUID=”a5bb6861-01″
/dev/sdb1: UUID=”f0b4e401-e9dc-472e-b9ca-3fa06a5b2e22″ TYPE=”xfs” PARTLABEL=”xfspart” PARTUUID=”af3ca4e5-cb38-4856-8791-bd6b650ba1b3″
/dev/sdc14: PARTUUID=”de01bd39-4bfe-4bc8-aff7-986e694f7972″
sudo nano /etc/fstab
use the UUID value for the /dev/sdb1 device. Change by the UUID from your case and add the following at the end of the file:
UUID=f0b4e401-e9dc-472e-b9ca-3fa06a5b2e22 /datadrive xfs defaults,nofail 1 2
Configure the Disk on Linux VM02
ssh azureuser@40.114.24.217
Find the disk
lsblk -o NAME,HCTL,SIZE,MOUNTPOINT | grep -i “sd”
Partition a new disk
As the disk already was partitioned on the VM01, we can skip this step now.
Mount the disk
sudo mkdir /datadrive
sudo mount /dev/sda1 /datadrive
Ensure mounting during the boot
sudo blkid
The ouput should be something similar to:
/dev/sdb1: LABEL=”cloudimg-rootfs” UUID=”5a9997c3-aafd-46e9-954c-781f2b11fb68″ TYPE=”ext4″ PARTUUID=”cbc2fcb7-e40a-4fec-a370-51888c246f12″
/dev/sdb15: LABEL=”UEFI” UUID=”2FBA-C33A” TYPE=”vfat” PARTUUID=”53fbf8ed-db79-4c52-8e42-78dbf30ff35c”
/dev/sdc1: UUID=”d1b59101-225e-48f4-8373-4f1a92a81607″ TYPE=”ext4″ PARTUUID=”b0218b4e-01″
/dev/sda1: UUID=”f0b4e401-e9dc-472e-b9ca-3fa06a5b2e22″ TYPE=”xfs” PARTLABEL=”xfspart” PARTUUID=”dda03810-f1f9-45a5-9613-08e9b5e89a32″
/dev/sdb14: PARTUUID=”de01bd39-4bfe-4bc8-aff7-986e694f7972″
sudo nano /etc/fstab
use the UUID value for the /dev/sda1 device. Change by the UUID from your case and add the following at the end of the file:
UUID=f0b4e401-e9dc-472e-b9ca-3fa06a5b2e22 /datadrive xfs defaults,nofail 1 2
Install GlusterFS on Linux VM01
Please note that in my case the IPs 192.168.1.4 and 192.168.1.5 are the private ip’s from VM01 and VM02. Add those configuration on the /etc/hosts.
sudo nano /etc/hosts
192.168.1.4 gluster1.local gluster1
192.168.1.5 gluster2.local gluster2
sudo apt update
sudo apt install software-properties-common
sudo add-apt-repository ppa:gluster/glusterfs-7
sudo apt update
sudo apt install glusterfs-server
sudo systemctl status glusterd.service
Install GlusterFS on Linux VM02
Please note that the IPs 192.168.1.4 and 192.168.1.5 are the private ip’s from VM01 and VM02. Add those configuration on the /etc/hosts.
sudo nano /etc/hosts
192.168.1.4 gluster1.local gluster1
192.168.1.5 gluster2.local gluster2
sudo apt update
sudo apt install software-properties-common
sudo add-apt-repository ppa:gluster/glusterfs-7
sudo apt update
sudo apt install glusterfs-server
sudo systemctl status glusterd.service
Configure GlusterFS on Linx VM01
sudo gluster peer probe gluster2
sudo gluster peer status
sudo gluster volume create sharedvolume replica 2 gluster1.local:/datadrive gluster2.local:/datadrive force
sudo gluster volume start sharedvolume
sudo gluster volume status
sudo apt install glusterfs-client
sudo mkdir /gluster-storage
sudo nano /etc/fstab
Add the following at the end of the file:
gluster1.local:sharedvolume /gluster-storage glusterfs defaults,_netdev 0 0
sudo mount -a
Configure GlusterFS on Linx VM02
sudo gluster peer probe gluster1
sudo gluster peer status
sudo gluster volume status
sudo apt install glusterfs-client
sudo mkdir /gluster-storage
sudo nano /etc/fstab
Add the following at the end of the file:
gluster2.local:sharedvolume /gluster-storage glusterfs defaults,_netdev 0 0
sudo mount -a
Test
In one of the nodes, go to /gluster-storage and create some files:
ssh azureuser@myVM01
azureuser@myVM01:~# sudo touch /gluster-storage/file{1..10}
Then go to the another node and check those files:
ssh azureuser@myVM02
azureuser@myVM02:~# ls -l /gluster-storage
total 0
-rw-r–r– 1 root root 0 Apr 1 19:48 file1
-rw-r–r– 1 root root 0 Apr 1 19:48 file10
-rw-r–r– 1 root root 0 Apr 1 19:48 file2
-rw-r–r– 1 root root 0 Apr 1 19:48 file3
-rw-r–r– 1 root root 0 Apr 1 19:48 file4
-rw-r–r– 1 root root 0 Apr 1 19:48 file5
-rw-r–r– 1 root root 0 Apr 1 19:48 file6
-rw-r–r– 1 root root 0 Apr 1 19:48 file7
-rw-r–r– 1 root root 0 Apr 1 19:48 file8
-rw-r–r– 1 root root 0 Apr 1 19:48 file9
Now execute a shutdown on myVM02:
azureuser@myVM02:~# sudo init 0
Connection to 40.114.24.217 closed by remote host.
Connection to 40.114.24.217 closed.
Access myVM01 and you notice that you still with access to the files:
azureuser@myVM01:~$ ls -l /gluster-storage/
total 0
-rw-r–r– 1 root root 0 Apr 1 19:48 file1
-rw-r–r– 1 root root 0 Apr 1 19:48 file10
-rw-r–r– 1 root root 0 Apr 1 19:48 file2
-rw-r–r– 1 root root 0 Apr 1 19:48 file3
-rw-r–r– 1 root root 0 Apr 1 19:48 file4
-rw-r–r– 1 root root 0 Apr 1 19:48 file5
-rw-r–r– 1 root root 0 Apr 1 19:48 file6
-rw-r–r– 1 root root 0 Apr 1 19:48 file7
-rw-r–r– 1 root root 0 Apr 1 19:48 file8
-rw-r–r– 1 root root 0 Apr 1 19:48 file9
Now let’s create some new files:
azureuser@myVM01:~$ sudo touch /gluster-storage/new-file{1..10}
azureuser@myVM01:~$ sudo ls -l /gluster-storage/
total 0
-rw-r–r– 1 root root 0 Apr 1 19:48 file1
-rw-r–r– 1 root root 0 Apr 1 19:48 file10
-rw-r–r– 1 root root 0 Apr 1 19:48 file2
-rw-r–r– 1 root root 0 Apr 1 19:48 file3
-rw-r–r– 1 root root 0 Apr 1 19:48 file4
-rw-r–r– 1 root root 0 Apr 1 19:48 file5
-rw-r–r– 1 root root 0 Apr 1 19:48 file6
-rw-r–r– 1 root root 0 Apr 1 19:48 file7
-rw-r–r– 1 root root 0 Apr 1 19:48 file8
-rw-r–r– 1 root root 0 Apr 1 19:48 file9
-rw-r–r– 1 root root 0 Apr 1 20:00 new-file1
-rw-r–r– 1 root root 0 Apr 1 20:00 new-file10
-rw-r–r– 1 root root 0 Apr 1 20:00 new-file2
-rw-r–r– 1 root root 0 Apr 1 20:00 new-file3
-rw-r–r– 1 root root 0 Apr 1 20:00 new-file4
-rw-r–r– 1 root root 0 Apr 1 20:00 new-file5
-rw-r–r– 1 root root 0 Apr 1 20:00 new-file6
-rw-r–r– 1 root root 0 Apr 1 20:00 new-file7
-rw-r–r– 1 root root 0 Apr 1 20:00 new-file8
-rw-r–r– 1 root root 0 Apr 1 20:00 new-file9
Then just turn on the myVM02 and you will be able the see all files syncronized on myVM02:
azureuser@myVM02:~$ ls -l /gluster-storage/
total 0
-rw-r–r– 1 root root 0 Apr 1 19:48 file1
-rw-r–r– 1 root root 0 Apr 1 19:48 file10
-rw-r–r– 1 root root 0 Apr 1 19:48 file2
-rw-r–r– 1 root root 0 Apr 1 19:48 file3
-rw-r–r– 1 root root 0 Apr 1 19:48 file4
-rw-r–r– 1 root root 0 Apr 1 19:48 file5
-rw-r–r– 1 root root 0 Apr 1 19:48 file6
-rw-r–r– 1 root root 0 Apr 1 19:48 file7
-rw-r–r– 1 root root 0 Apr 1 19:48 file8
-rw-r–r– 1 root root 0 Apr 1 19:48 file9
-rw-r–r– 1 root root 0 Apr 1 20:00 new-file1
-rw-r–r– 1 root root 0 Apr 1 20:00 new-file10
-rw-r–r– 1 root root 0 Apr 1 20:00 new-file2
-rw-r–r– 1 root root 0 Apr 1 20:00 new-file3
-rw-r–r– 1 root root 0 Apr 1 20:00 new-file4
-rw-r–r– 1 root root 0 Apr 1 20:00 new-file5
-rw-r–r– 1 root root 0 Apr 1 20:00 new-file6
-rw-r–r– 1 root root 0 Apr 1 20:00 new-file7
-rw-r–r– 1 root root 0 Apr 1 20:00 new-file8
-rw-r–r– 1 root root 0 Apr 1 20:00 new-file9
As you can see the files was in sync and without any kind of data loss even in the case of one of the nodes was offline.

































































Recent Comments