Prepare for Cloud Service Disaster Recovery – Export Key M365 Services Configurations
This article is contributed. See the original author and article here.
Not too long ago, it was the first day of school, then it was the first NFL game and we just passed the first day of fall. As seasons change, I am reminded of the things that I should do but often don’t. Either I forget or avoid. So it is for Business Continuity/Disaster Recovery (BCDR) efforts. About 10 years ago, I wrote a blog post with some points about DR (Disaster Recovery – Microsoft Tech Community) then, about seven years ago, I posted a DR ‘reminder’ (Disaster Recovery – A Reminder – Microsoft Tech Community). Those were both ‘pre-cloud’ – which seems so long ago. In any event, a post from me around BCDR for cloud components is well past due.
NOTE: Service availability is one aspect of BCDR, as is data availability. For the most part, those two elements are solid when it comes to SaaS – those are two of the value props of the SaaS model. However, in this post, I’m focusing on recovering from accidental or malicious deletions of configurations in some of your key Microsoft cloud services.
“What would you do if…?”
You get a call that ‘something is going on’ – people aren’t getting blocked when they should be. People aren’t getting prompted when they should be. Where you’d normally see your org’s logo on the sign in pages, you see the Microsoft logo. You recall that moments ago, you didn’t get prompted when you went to check email via OWA this morning. Your stomach turns.
You pop open the Azure portal and immediately notice you don’t get MFA’d. Your stomach turns again but more deeply. Your face gets hot. Your brain races as you ask yourself “Did I do something?” You open the AAD Conditional Access portal spot … there are only a few ‘default’ policies listed. There are normally a dozen or more policies with your custom naming standard. You rub your eyes to see if you’re just not seeing it but the emptiness remains. You refresh the portal page. You verify the tenant name … still blank. You quickly jump over to the MEM portal … many of the Intune policies and settings are gone, too. You check out the Defender for Cloud Apps (aka MCAS) policy page; your custom CASB policies are gone. It’s like you’re signing in to a brand new M365 trial.
Before you tackle the ‘who/what/when/where’ questions from management to explain what happened, you need to get back to a functional run-state. That won’t be too tough, thankfully, as you have nightly exports from the various M365 services. Or you have a weekly calendar reminder to run manual exports, every Friday when you first get into the office, right? Or you have Word docs with screen captures of the portal pages that you update the first Tuesday of every month, right? Or an XLS with the settings? Or you have a chicken-scratch Notepad file from when you first setup the policies?
Or, perhaps you don’t; perhaps you have nothing more than a vague visual memory of what you’d see when you’d look in the portals; a general idea of the various policies and what they did – but only sparse memories of a few of the myriad settings across the services. Oh, and the portal UIs have changed considerably since you setup those policies years ago (if it even was you who set them up). It’s gonna be a loooong day(s).
Ok, back to reality … whew.
An ounce of prevention (or planning) is worth a pound of cure. Just do something. It doesn’t need to be perfect. The only thing worse than a mass-deletion event is one without any sort of recoverability planning and desired settings references/materials. Staring at a blank portal page, trying to recall from memory what had been setup previously is no bueno. Plus, management will be asking ‘why weren’t we better prepared to recover from this?’ Have a solid answer vs a ‘deer in the headlights’ stare.
Sadly, as of today, there isn’t a ‘backup now’ or ‘recover now’ button in the portals but there is some good news; since these are SaaS capabilities, there are no servers to restore or infrastructure to recover/establish. It’s basically entering configuration information in web forms.
Here are a few ideas on possible BCDR for your M365 services (you may find/have others – if so, great! Share what’s worked/not worked for you in the comments)
- Screen-scrapes from the portal pages into organized docs that are stored in an available manner (electronically, local USB and hard-copy – three ring binders are great for this type of info, stored in your DR tubs)
- In the past, this was a more viable option but these days, in my view, there are just too many configuration screens/options for a given configuration and it takes a long time and a lot of clicks to drill-down to all of the various pages/sub-pages of a configuration/policy.
- That said, if this is your jam, rock on. Put on some headphones, fire up Winamp and blast REO Speedwagon while you try to wear out the CTRL/C/V buttons on your keyboard.
- M365 DSC is a well-developed PowerShell toolset to do all sorts of things with many cloud service configurations (export/import, monitor for drift, etc.)
- AAD Exporter looks very promising, but I’ve not spent any time with it, and it only captures AAD
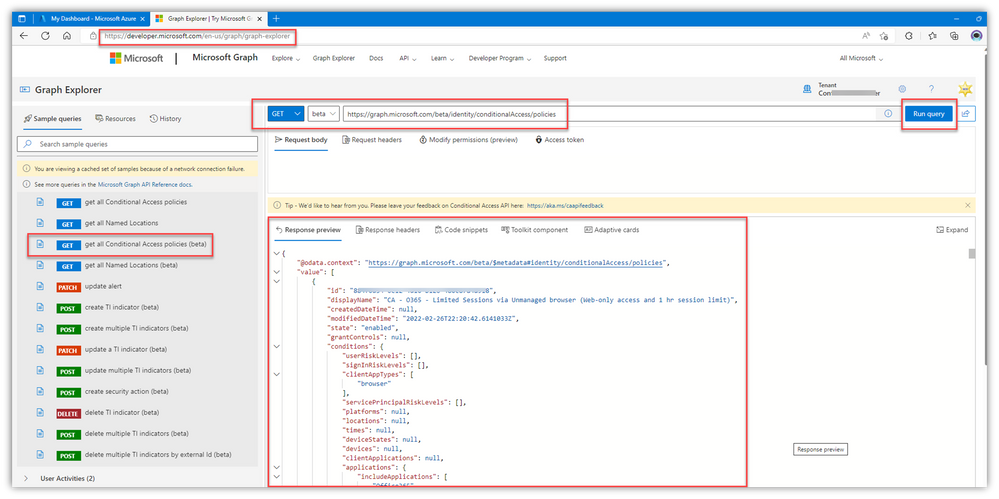
- Ad hoc Graph Explorer queries
- Graph Explorer | Try Microsoft Graph APIs – Microsoft Graph
- This is very helpful. There are some handy ‘built in’ GET queries in the various entity groups on the left (Users, Security, etc.) – GET is your friend for exports/documenting current state. Stay far, far away from anything EXCEPT GET or you may self-induce an accidental change
- The APIs have pretty extensive docs, too, with sample queries – Microsoft Graph REST API beta endpoint reference – Microsoft Graph beta | Microsoft Learn
- As a bonus, Graph is powerful – way beyond just config exports. Any skills you develop with this BCDR endeavor will carry over into other M365 management and admin tasks.
- Below is an example of a query to list the AAD CA policies in my lab:
Explore the various options “discoverable” in the dynamic auto-fill query box – I guarantee you’ll be giddy at some of the things you’ll find:

- Here are a few query URLs you can copy and paste in the query box, then copy/paste the GET results into Notepad or something – It’s literally THAT easy to grab many of your critical cloud configs
- AAD Conditional Access Policies – https://graph.microsoft.com/beta/conditionalAccess/policies
- AAD Devices – https://graph.microsoft.com/beta/devices
- AAD Trusted Locations – https://graph.microsoft.com/beta/conditionalAccess/namedLocations
- Intune Config Policies – https://graph.microsoft.com/beta/deviceManagement/configurationPolicies
- Intune Compliance Policies – https://graph.microsoft.com/beta/deviceManagement/deviceCompliancePolicies
- Intune MAM Policies – https://graph.microsoft.com/beta/deviceAppManagement/managedAppPolicies
- Intune branding/customization – https://graph.microsoft.com/beta/deviceManagement/intuneBrandingProfiles
- MIP Sensitivity Labels – https://graph.microsoft.com/beta/me/informationprotection/policy/labels
NOTE: You might not have the proper permissions to access certain elements from Graph, even if you’re using a GA account:

It’s an easy fix, right from within Graph Explorer, but be sure you understand what ‘Consent’ means – and also realize that your global AAD settings might restrict or block these consent actions:


NOTE: MDCA (Defender for Cloud Apps aka MCAS) doesn’t seem to have similar graph exposure. You can export the ‘whole’ portal config, policies and IP list into a single JSON file via Settings but I don’t know what that includes/leaves out, and there isn’t a way to re-import it for recovery.

Regardless, you can easily get screen captures of your custom policies from the portal.
- In my case, I use a naming convention for my custom MCAS policies which makes it super easy to sort them in the portal, then get screen shots of each policy


Visuals are Important
A few notes about the visual branding elements of the various services/portals, and the Company Portal for Intune:
- At this point, I don’t know of a way to export the images/pictures/graphics that are uploaded to the services. In the exports of the settings (if you can find them), there are references to CDN URL links but they’re ambiguous and don’t point directly to a ‘file.’
- Those files have very specific size limits/pixel counts and other parameters, not to mention there were probably hoops to jump through to get ‘organizational approval’ to use those specific images, etc. Track down those specific files that were uploaded and store them in the event that an accidental (or planned) change gets made to those and you want to revert/roll-back/recover.
- Those visual elements are part of your org’s ‘front door’ to most M365 services – most of your users will see those often.
- If those visuals change, even expectedly, it can cause “confusion” for a lot of people (read: many helpdesk calls). Be prepared.
- If you use custom colors in the Intune customizations and/or the Office ‘theme,’ they are likely hex values that you should make a note of.
- Further, some of the AAD branding elements apply to Autopilot, too – Windows Autopilot Azure AD Branding – Microsoft Tech Community



Think outside the box
With BCDR topics, you have to think well outside of typical ‘day to day’ operations. Make sure you have a plan, the plan is documented and vetted/tested and updated every month/quarter/year.
Here are a few more “table-top exercises” and thoughts related to BCDR:
- If Teams/chat and Exchange/email are down, along with AD/AAD (i.e. the GAL), how will you communicate with one another? No Teams chats. No email. No phone numbers.
- You can call someone’s cellphone but how will you find phone numbers?
- How will you execute a ‘war room’ meeting/conference call if Teams is down?
- Make a plan, make a list of names and phone numbers, store it somewhere and have a hard-copy. Update it (quarterly?).
- Ensure the decision tree used to declare a BCDR ‘incident’ includes cloud services/issues
- Print out the settings/config/recovery docs and put them into a 3-ring binder in your DR tub, along with a USB stick containing those files
- Don’t fall prey to the idea that ‘high availability’ is all you need. Accidents happen – and they replicate.
- Try to expect the unexpected. Think through the ‘what ifs’ and worst-case scenarios.
- I recall being part of a DR event where the highly available SAN went down … care to guess where the well-developed DR plans/docs/tools/etc. were stored?
Cautionary reminders
- Credential exposure: All of this BCDR documentation I mentioned above should be for your service settings, profiles and configurations – it should not include your (nor anyone’s) credentials. Safety first. Zero trust.
- Of course, special accounts/credentials needed for BCDR might need to be stored – but securely and separately from configuration recovery docs.
- Risk of unintended changes:
- Using Graph is very helpful but stick with GET. If you wander down the paths of POST, DELETE, SET … anything other than GET … you could very well enter a world of pain.
- Many of the cloud configuration screens/UIs don’t have the typical Win32 app ‘Are you sure?’ verification prompts. Admins sometimes accidentally make a change just by ‘casual administration,’ while they poke around in portal pages.
Sharing IT horror stories is a pretty fun past-time of ‘the job’ but in the heat of an incident or outage, there is VERY little fun. Do yourself a favor (and your org), take some time in the next week and review/setup exports of your key configurations. You’ll sleep a bit better once you do.
Hilde


Recent Comments