by Contributed | Nov 14, 2023 | Technology
This article is contributed. See the original author and article here.
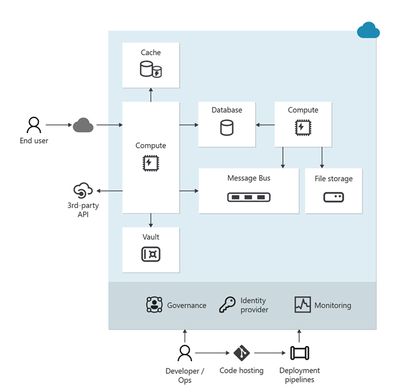
I am excited to announce a comprehensive refresh of the Well-Architected Framework for designing and running optimized workloads on Azure. Customers will not only get great, consistent guidance for making architectural trade-offs for their workloads, but they’ll also have much more precise instructions on how to implement this guidance within the context of their organization.
Background
Cloud services have become an essential part of the success of most companies today. The scale and flexibility of the cloud offer organizations the ability to optimize and innovate in ways not previously possible. As organizations continue to expand cloud services as part of their IT strategies, it is important to establish standards that create a culture of excellence that enables teams to fully realize the benefits of the modern technologies available in the cloud.
At Microsoft, we put huge importance on helping customers be successful and publish guidance that teaches every step of the journey and how to establish those standards. For Azure, that collection of adoption and architecture guidance is referred to as Azure Patterns and Practices.
The Patterns and Practices guidance has three main elements:
Each element focuses on different parts of the overall adoption of Azure and speaks to specific audiences, such as WAF and workload teams.
What is a workload?
The term workload in the context of the Well-Architected Framework refers to a collection of application resources, data, and supporting infrastructure that function together towards a defined business goal.
Well-architected is a state that is achieved and maintained through design and continuous improvement. You optimize through a design process that results in an architecture that delivers what the business needs while minimizing risk and expense.
For us, the workload standard of excellence is defined in the Well-architected Framework – a set of principles, considerations, and trade-offs that cover the core elements of workload architecture. As with all of the Well-architected Framework content, this guidance is based on proven experience from Microsoft’s customer-facing technical experts. The Well-architected Framework continues to receive updates from working with customers, partners, and our technical teams.
Today we have published updates across each of the core pillars of WAF which represent a huge amount of experience and learning from across Microsoft.
The refreshed and expanded Well-Architected Framework brings together guidance to help workload teams design, build, and optimize great workloads in the cloud. It is intended to shape discussions and decisions within workload teams and help create standards that should be applied continuously to all workloads.
Details of the refreshed Well-Architected Framework
Over the past six months, Microsoft’s cloud solution architects refreshed the Well-Architected Framework by compiling the learnings and experience of over 10,000 engagements that had leveraged the WAF and its assessment.
All five pillars of the Well-Architected Framework now follow a common structure that consists exclusively of design principles, design review checklists, trade-offs, recommendation guides, and cloud design patterns.

Design principles. Presents goal-oriented principles that build a foundation for the workload. Each principle includes a set of recommended approaches and the benefits of taking those approaches. The principles for each pillar have changed in terms of content and coverage.
Design review checklists. Lists roughly codified recommendations that drive action. Use the checklists during the design phase of your new workload and to evaluate brownfield workloads.

Trade-offs. Describes tradeoffs with other pillars. Many design decisions force a tradeoff. It’s vital to understand how achieving the goals of one pillar might make achieving the goals of another pillar more challenging.
Recommendation guides. Every design review checklist recommendation is associated with one or more guides. They explain the key strategies to fulfill that recommendation. They also include how Azure can facilitate workload design to help achieve that recommendation. Some of these guides are new, and others are refreshed versions of guides that cover a similar concept.
The recommendation guides include trade-offs along with risks.
- This icon indicates a trade-off:

- This icon indicates a risk:


Cloud design patterns. Build your design on proven, common architecture patterns. The Azure Architecture Center maintains the Cloud Design Patterns catalog. Each pillar includes descriptions of the cloud design patterns that are relevant to the goals of the pillar and how they support the pillar.

The Well-Architected Review assessment has also been refreshed. Specifically, the “Core Well-Architected Review” option now aligns to the new content structure in the Well-Architected Framework. Every question in every pillar maps to the design review checklist for that pillar. All choices for the questions correlate to the recommendation guides for the related checklist item.
Using the guidance
The Well-architected Framework is intended to help workload teams throughout the process of designing and running workloads in the cloud.
Here are three key ways in which the guidance can help your team be successful:
- Use the Well-architected Framework as the basis for your organization’s approach to designing and improving cloud workloads.
- Establish the concept of achieving and maintaining a state of well-architected as a best practice for all workload teams
- Regularly review each workload to find opportunities to optimize further – use learnings from operations and new technology capabilities to refine elements such as running costs, or attributes aligned to performance, reliability, or security
To learn more, see the new hub page for the Well-Architected Framework: aka.ms/waf
Dom Allen has also created a great, 6-minute video on the Azure Enablement Series.

by Contributed | Nov 13, 2023 | Technology
This article is contributed. See the original author and article here.
v:* {behavior:url(#default#VML);}
o:* {behavior:url(#default#VML);}
w:* {behavior:url(#default#VML);}
.shape {behavior:url(#default#VML);}
Meiko Lopez
Normal
Joe Cicero
2
277
2023-11-09T21:37:00Z
2023-11-09T21:37:00Z
3
719
4101
34
9
4811
16.00
0x010100A389A42144AF8541BAAFF21480674075
Clean
Clean
false
false
false
false
EN-US
JA
AR-SA
Service Delivery Manager Profile: Meiko Lopez
“Be steadfast in the truth – providing comfort and assurance to the customers that you will help them to a resolution.”
-Meiko Lopez, Sr. Product Manager
In the dynamic world of cybersecurity, heroes emerge to safeguard our customers’ digital realm. One such hero is Meiko Lopez, a senior product manager within Microsoft’s service delivery arm for the Defender Experts for XDR service. With almost 13 years of experience at Microsoft, Meiko brings a wealth of knowledge, skills, and a unique approach to the cybersecurity landscape.
Who is Meiko Lopez?
Meiko (pronounced mee-ko) Lopez introduces herself: “My name is Meiko Lopez, and I am a service delivery manager (SDM) for the Microsoft Defender Experts for XDR service.” Her journey at Microsoft has been nothing short of extraordinary.
What did you do before becoming an SDM?
Meiko’s journey at Microsoft is a testament to her dedication and versatility. She started as a technical account manager, now known as a customer success account manager. In this role, she served as a “Cyber Champ,” assisting enterprise customers in crafting and executing their IT strategies and aligning them with Microsoft’s solutions. Her early experiences also included roles as a project manager, where she helped customers recover and rebuild their infrastructure after cybersecurity breaches, enhancing their security posture for the long term.
Meiko’s transition to a cyber architect role further showcased her technical prowess and leadership. Through these diverse roles, she developed a strong network of partnerships and honed both her business acumen and technical skills. These experiences have enabled her to help customers reach new heights in their cybersecurity journey.
What is your typical “day in the life” of an SDM?
Meiko’s day as an SDM is filled with activities aimed at enhancing customer satisfaction and service performance. She conducts operational syncs with her customers, discussing service health and alignment with their business objectives. These discussions also serve as an avenue for collecting feedback and suggestions for operational, technical, and relationship improvements.
In addition to customer interactions, Meiko collaborates with other product managers to share customer feedback and prioritize needs. She engages with her team members on various initiatives that enhance visibility both inside and outside their organization, making the Defender Experts for XDR service even more powerful. Her day wraps up by inputting insights from various stakeholders to track backlog items that ultimately improve the service.
How do you customize your approach for each customer?
Meiko’s success lies in her ability to customize her partnership with each customer. She takes the time to understand their unique business and operational context. She reviews notes from past conversations, connects with internal stakeholders aligned to the customer, and reviews Defender Experts operational insights to identify areas that will demonstrate value during their discussions. Active engagement with the team of analysts also provides a deeper understanding of the customer’s environment and how they can improve technically.
How do you balance technical expertise with the human element?
In the world of cybersecurity, balancing technical expertise with the human element is paramount. Meiko emphasizes the importance of empathy in high-stakes situations. She believes that technical understanding, coupled with the ability to convey information effectively to the appropriate audience, is the key to success. Communication is the linchpin that ensures resolution and instills confidence in customers.
Meiko’s advice to those aspiring to enter the cybersecurity field is simple yet powerful: “Go for it. Gain the foundation and grow from there. There are so many facets of cybersecurity that the possibilities are endless. Network and connect with those in cybersecurity to get a first-hand account of what your future could entail. Find what works best for you.”
What are some of your unique strengths and qualities?
Beyond her technical skills, Meiko’s unique strengths and qualities benefit her customers in cybersecurity. She’s known for her personable nature, which fosters trust and credibility. In the cybersecurity space, trust is everything, and Meiko’s ability to connect with others has proven invaluable. Her calm demeanor in critical situations provides assurance to customers that they have a dedicated and dependable ally in their corner.
Meiko Lopez’s journey is a testament to the diverse opportunities and paths within the cybersecurity field, and her commitment to excellence serves as an inspiration for those entering this dynamic and vital field.

by Contributed | Nov 11, 2023 | Technology
This article is contributed. See the original author and article here.
Hi everyone! Brandon Wilson here once again with this month’s “Check This Out!” (CTO!) guide.
These posts are only intended to be your guide, to lead you to some content of interest, and are just a way we are trying to help our readers a bit more, whether that is learning, troubleshooting, or just finding new content sources! We will give you a bit of a taste of the blog content itself, provide you a way to get to the source content directly, and help to introduce you to some other blogs you may not be aware of that you might find helpful.
From all of us on the Core Infrastructure and Security Tech Community blog team, thanks for your continued reading and support!
Title: Click Through Demo for Windows Server 2012 Extended Security Updates Enabled by Azure Arc
Source: Azure Arc
Author: Dan Richardson
Publication Date: 10/9/2023
Content excerpt:
As many of you know, Windows Server 2012 is reaching end-of-support (EoS) on October 10, 2023. Extended Security enabled by Azure Arc is the best way for customers to get trusted security updates and benefit from cloud capabilities including discovery, management, and patching, all in one offering.

Title: Azure Provides Enhanced Security Awareness with Ubuntu Pro
Source: Azure Compute
Author: Maulik Shah
Publication Date: 10/12/2023
Content excerpt:
Bad actors can expose a new security vulnerability to initiate a DDoS attack on a customer’s infrastructure. This attack is leveraged against servers implementing the HTTP/2 protocol. Windows, .NET Kestrel, and HTTP .Sys (IIS) web servers are also impacted by the attack. Azure Guest Patching Service keeps customers secure by ensuring the latest security and critical updates are applied using Safe Deployment Practices on their VM and VM Scale Sets.

Title: Azure Monitor Baseline Alerts (AMBA) for Azure landing zone (ALZ) is Generally Available (GA)!
Source: Azure Governance and Management
Author: Paul Grimley
Publication Date: 10/6/2023
Content excerpt:
Some of you may recall back in June we posted a blog introducing AMBA and since then we’ve received a huge amount of interest and adoption in its use as well as hearing from you on what you needed to be able to use AMBA in your environment.
We’ve made significant investment and progress in addressing feedback and fixes and I’m pleased to announce the AMBA pattern for ALZ is now GA! As part of GA we’re also integrating the recommended alerts into the ALZ Azure Portal reference implementation for new deployments (please visit https://aka.ms/alz/portal) with Bicep and Terraform support planned in the near future.

Title: Optimize your Cloud investment with new Azure Advisor Workbooks
Source: Azure Governance and Management
Author: Antonio Ortoll
Publication Date: 10/10/2023
Content excerpt:
Everyone is under pressure to cut costs these days. But in times of economic flux, it’s not just about cutting costs. A successful approach lies in the ability to continuously optimize and prioritize what matters most to drive innovation, productivity, and agility and to realize an ongoing cycle of growth and innovation. Reinvestment opens the opportunity to maintain momentum when everyone else is seeking to downsize – that’s the competitive advantage optimization offers your business.

Title: Announcing AuthorizationResources in Azure Resource Graph
Source: Azure Governance and Management
Author: Snaheth Thumathy
Publication Date: 10/16/2023
Content excerpt:
We are excited to announce support for Azure RBAC resources in Azure Resource Graph (ARG) via the AuthorizationResources table! You can query your Role Assignments, Role Definitions, and Classic Admins resources. With this table, you’ll be able to quickly answer questions such as “how many users are using a role definition?” or “how many role assignments are used?” or “how many role definitions are used?”. Then, you can act on the results to clean up unused role definitions, remove redundant role assignments, or optimize your existing role assignments using AAD Groups.

Title: Built-in Azure Monitor alerts for Azure Site Recovery is now in public preview
Source: Azure Governance and Management
Author: Aditya Balaji
Publication Date: 10/29/2023
Content excerpt:
We are happy to share that built-in Azure Monitor alerts for Azure Site Recovery is now in public preview.
With this integration, Azure Site Recovery users will now have:
- A way to route notifications for alerts to any of the destinations supported by Azure Monitor – which includes email, ITSM, Webhook, Functions etc.
- An alerting experience for Azure Site Recovery which is consistent with the alerting experience currently available for many other Azure resource types.
- Enhanced flexibility in terms of choosing which scenarios to get notified for, ability to suppress notifications during planned maintenance windows, and so on.

Title: Announcing General Availability: Azure Change Tracking & Inventory using Azure Monitor agent (AMA)
Source: Azure Governance and Management
Author: Swati Devgan
Publication Date: 10/31/2023
Content excerpt:
We are excited to announce the general availability to configure Azure Change Tracking & Inventory using the Azure Monitor agent (AMA)
The Change Tracking and Inventory service tracks changes to Files, Registry, Software, Services and Daemons and uses the MMA (Microsoft Monitoring Agent)/OMS (Operations Management Suite) agent.

Title: Step-by-Step Guide: Setting up Custom Domain for Azure Storage Account with HTTPS Only Enabled
Source: Azure PaaS
Author: Zoey Lan
Publication Date: 10/3/2023
Content excerpt:
If you are using Azure Storage to host your website, you might want to enable HTTPS Only to ensure secure communication between the client and the server. However, setting up a custom domain with HTTPS Only enabled can be a bit tricky. In this blog, we will guide you through the step-by-step process of setting up a custom domain for your Azure Storage account with HTTPS Only enabled.

Title: How to Restrict User Visibility of File Share, Queue, and Table Storage Service
Source: Azure PaaS
Author: Sourabh Jain
Publication Date: 10/13/2023
Content excerpt:
Suppose you have a specific requirement wherein the user should not have access to view the File Share, Queue, and Table Storage Services Data. The user should only be able to access and view the containers within the storage account. In this blog, we will delve into the methods and techniques to fulfil this requirement.

Title: Unlocking Azure Secrets: Using Identities for Key Vault Access
Source: Core Infrastructure and Security
Author: Joji Varghese
Publication Date: 10/2/2023
Content excerpt:
Azure Key Vault is essential for securely managing keys, secrets, and certificates. Managed Identities (MI) allow Azure resources to authenticate to any service that supports Azure AD authentication without any credentials in your code. For those looking to swiftly test Managed Identities for Azure Key Vault access from a Virtual Machine, this blog provides step-by-step implementation details. We will delve into both User Assigned Managed Identity (UAMI) and System Assigned Managed Identity (SAMI), helping you determine the best approach for your needs.

Title: Mobile Application Management on Windows 11
Source: Core Infrastructure and Security
Author: Atil Gurcan
Publication Date: 10/4/2023
Content excerpt:
Intune is very well known for its ability to manage both devices (aka. MDM) and applications (aka.MAM). The core difference between these two options lies back to the level of management that companies require, or employees accept.
While MDM is seen an appropriate way to manage company-owned devices or a full zero trust environment; MAM is useful when a company wants to make sure employees can use their personal devices to run applications that access to company data, and limit what can be done with that data. From that perspective, it can improve zero trust posture of a company as well; making sure that applications used to access certain data such as the company data complies with certain criteria, that is defined in the application protection policy.

Title: Quick-Start Guide to Azure Private Endpoints with AKS & Storage
Source: Core Infrastructure and Security
Author: Joji Varghese
Publication Date: 10/9/2023
Content excerpt:
Azure Private Endpoints (PE) offer a robust and secure method for establishing connections via a private link. This blog focuses on utilizing PEs to link a Private Azure Kubernetes Service (AKS) cluster with a Storage account, aiming to assist in quick Proof-of-Concept setups. Although we spotlight the Storage service, the insights can be seamlessly applied to other Azure services.

Title: Defender Definition Updates with ConfigMgr – Part 2 – How to set it up
Source: Core Infrastructure and Security
Author: Stefan Röll
Publication Date: 10/16/2023
Content excerpt:
Here is Part 2 of my Blog Defender Definition Updates with ConfigMgr – Part 1 – Learnings from the Field
Currently Defender Definition Updates are called Security Intelligence Update for Windows Defender Antivirus. To keep it consistent with Part 1 of my Blog, I will keep calling them Definition Updates – The updates that are released multiple times per day.

Title: Service Endpoints vs Private Endpoints
Source: Core Infrastructure and Security
Author: Khushbu Gandhi
Publication Date: 10/24/2023
Content excerpt:
For a long time, if you were using the multi-tenant, PaaS version on many Azure services, then you had to access them over the internet with no way to restrict access just to your resources. This restriction was primarily down to the complexity of doing this sort of restrictions with a multi-tenant service. At that time, the only way to get this sort of restriction was to look at using single-tenant solutions like App Service Environment or running service yourself in a VM instead of using PaaS.

Title: Calling Azure Resource APIs from Power Automate Using Graph Explorer
Source: Core Infrastructure and Security
Author: Werner Rall
Publication Date: 10/31/2023
Content excerpt:
In today’s fast-paced technological landscape, cloud integration and automation have ascended as twin pillars of modern business efficiency. Microsoft’s Azure and Power Automate are two titans in this arena, each offering a unique set of capabilities. But what if we could marry the vast cloud resources of Azure with the intuitive workflow automation of Power Automate? In this article, we’ll embark on a digital journey to explore how you can seamlessly call Azure Resource APIs from Power Automate, unlocking new vistas of potential for your business processes. Whether you’re an Azure aficionado, a Power Automate pro, or someone just stepping into the cloud, strap in and let’s dive deep into this integration!

Title: Wired for Hybrid What’s New in Azure Networking September 2023 Edition
Source: ITOps Talk
Author: Pierre Roman
Publication Date: 10/16/2023
Content excerpt:
Azure Networking is the foundation of your infrastructure in Azure. Each month we bring you an update on What’s new in Azure Networking.
In this blog post, we’ll cover what’s new with Azure Networking in September 2023. In this blog post, we will cover the following announcements and how they can help you.
- Gateway Load Balancer IPv6 Support
- Sensitive Data Protection for Application Gateway Web Application Firewall
- Domain fronting update on Azure Front Door and Azure CDN
- New Monitoring and Logging Updates in Azure Firewall

Title: What’s new in Microsoft Entra
Source: Microsoft Entra (Azure AD)
Author: Shobhit Sahay
Publication Date: 10/2/2023
Content excerpt:
Microsoft has recently introduced a range of new security tools and features for the Microsoft Entra product family, aimed at helping organizations improve their security posture. With the ever-increasing sophistication of cyber-attacks and the increasing use of cloud-based services and the proliferation of mobile devices, it is essential that organizations have effective tools in place to manage their security scope.
Today, we’re sharing the new feature releases for the last quarter (July – September 2023) and the change announcements (September 2023 change management train). We also communicate these changes on release notes and via email. We’re continuing to make it easier for our customers to manage lifecycle changes (deprecations, retirements, service breaking changes) within the new Entra admin center as well.

Title: Just-in-time access to groups and Conditional Access integration in Privileged Identity Management
Source: Microsoft Entra (Azure AD)
Author: Joseph Dadzie
Publication Date: 10/2/2023
Content excerpt:
As part of our mission to enable customers to manage access with least privilege, we’re excited to announce the general availability of two additions to Microsoft Entra Privileged Identity Management (PIM): PIM for Groups and PIM integration with Conditional Access.

Title: Step-by-Step Guide to Identify Inactive Users by using Microsoft Entra ID Governance Access Reviews
Source: Microsoft Entra (Azure AD)
Author: Dishan Francis
Publication Date: 10/10/2023
Content excerpt:
Within an organization, inactive user accounts can persist for various reasons, including former employees, service providers, and service accounts associated with products or services. These accounts may remain inactive temporarily or for extended periods. If an account remains inactive for 90 days or more, it is more likely to remain inactive. It’s crucial to periodically review these inactive accounts and eliminate any that are unnecessary. Microsoft Entra ID Governance Access Reviews now offers the capability to detect inactive accounts effectively.

Title: Microsoft Graph Activity Log is Now Available in Public Preview
Source: Microsoft Entra (Azure AD)
Author: Kristopher Bash
Publication Date: 10/13/2023
Content excerpt:
Today we’re excited to announce the public preview of Microsoft Graph Activity Logs. Have you wondered what applications are doing with the access you’ve granted them? Have you discovered a compromised user and hoped to find out what operations they have performed? If so, you can now gain full visibility into all HTTP requests accessing your tenant’s resources through the Microsoft Graph API.

Title: Entra ID now enables you to receive emails in your preferred language
Source: Microsoft Entra (Azure AD)
Author: Jairo Cadena
Publication Date: 10/17/2023
Content excerpt:
We have received feedback from you—our customers—about the need to have user level language localization. We understand that users would like to receive notifications that have their text adapted to their local language, customs, and standards.
We have added logic to check multiple places for language information to make the best possible choice for what language we should send an email in, and these changes are now generally available for Privileged Identity Management, Access Reviews and Entitlement Management.

Title: Windows Local Administrator Password Solution with Microsoft Entra ID now Generally Available!
Source: Microsoft Entra (Azure AD)
Author: Sandeep Deo
Publication Date: 10/23/2023
Content excerpt:
Today we’re excited to announce the general availability of Windows Local Administrator Password Solution (LAPS) with Microsoft Entra ID and Microsoft Intune. This capability is available for both Microsoft Entra joined and Microsoft Entra hybrid joined devices. It empowers every organization to protect and secure their local administrator account on Windows and mitigate any Pass-the-Hash (PtH) and lateral traversal type of attacks.
Since our public preview announcement in April 2023, we’ve continued to see significant growth in deployment and usage of Windows LAPS across thousands of customers and millions of devices. Thank you!

Title: Delegate Azure role assignment management using conditions
Source: Microsoft Entra (Azure AD)
Author: Stuart Kwan
Publication Date: 10/25/2023
Content excerpt:
We’re excited to share the public preview of delegating Azure role assignment management using conditions. This preview gives you the ability to enable others to assign Azure roles but add restrictions on the roles they can assign and who they can assign roles to.

Title: New security capabilities of Event Tracing for Windows
Source: Windows IT Pro
Author: Jose Sua
Publication Date: 10/11/2023
Content excerpt:
Elevate your security with improved Event Tracing for Windows (ETW) logs. Now you can know who initiated the actions for each device to aid in threat detection and analysis. Whether you’re in cybersecurity, IT, performance, or software development, diagnosing cybersecurity threats has never been easier. In this article, get ready to:
- Learn about Windows event tracing.
- Find new security-related information on a Windows device.
- Interpret security-related events.

Title: The evolution of Windows authentication
Source: Windows IT Pro
Author: Matthew Palko
Publication Date: 10/11/2023
Content excerpt:
As Windows evolves to meet the needs of our ever-changing world, the way we protect users must also evolve to address modern security challenges. A foundational pillar of Windows security is user authentication. We are working on strengthening user authentication by expanding the reliability and flexibility of Kerberos and reducing dependencies on NT LAN Manager (NTLM).
Kerberos has been the default Windows authentication protocol since 2000, but there are still scenarios where it can’t be used and where Windows falls back to NTLM. Our team is building new features for Windows 11, Initial and Pass Through Authentication Using Kerberos (IAKerb) and a local Key Distribution Center (KDC) for Kerberos, to address these cases. We are also introducing improved NTLM auditing and management functionality to give your organization more insight into your NTLM usage and better control for removing it.

Title: Windows passwordless experience expands
Source: Windows IT Pro
Author: Sayali Kale
Publication Date: 10/23/2023
Content excerpt:
The future is passwordless. Microsoft has an ongoing commitment with other industry leaders to enable a world without passwords. Today, we are excited to announce an improved Windows passwordless experience to organizations starting with the September 2023 update for Windows 11, version 22H2.

Title: What’s new for IT pros in Windows 11, version 23H2
Source: Windows IT Pro
Author: Harjit Dhaliwal
Publication Date: 10/31/2023
Content excerpt:
When you update devices running Windows 11, version 22H2 to version 23H2, you’ll get the capabilities we have delivered as part of continuous innovation, including those announced in September, enabled by default. These include:…

Previous CTO! Guides:
Additional resources:

by Contributed | Nov 9, 2023 | Technology
This article is contributed. See the original author and article here.
t’s gearing up to be an exciting week November 14th – 17th as we prepare for this year’s Microsoft Ignite and PASS Data Summit all happening at once! While across the way we’ll be sharing the latest from Microsoft all up, taking place at the Convention Center. We’re excited to be with our community digging into all things data. We’re back as premier sponsors together with our partners at Intel. With over 30+ sessions we’ll cover everything from ground to the cloud, with SQL Server, Azure SQL, all the way up to powering analytics for your data with Microsoft Fabric. This year, we’ll also bring in our developer community with sessions covering our solutions for open-source database, PostgreSQL.
We hope you’ll join us to “Connect, Share and Learn” alongside the rest of your peers at the PASS community. The official event kicks off with our keynote Wednesday morning with Shireesh Thota Vice President of Azure Databases who’s been hard at work getting ready for the event:
https://twitter.com/AzureSQL/status/1720185734689079787
Below you’ll find just some of the highlights happening at this year’s PASS Summit:
Pre-Cons
Monday: The Cloud Workshop for the SQL DBA
Bob Ward
This workshop will provide a technically led driven approach to translating your knowledge and skills from SQL Server to Azure SQL. You will experience an immersive look at Azure SQL including hands-on labs, no Azure subscription required.
Tuesday: Azure SQL and SQL Server: All Things Developers
Brian Spendolini, Anagha Todalbagi
In this workshop, we’ll dedicate a full day to deep diving into each one of these new features such as JSON, Data API builder, calling REST endpoints, Azure function integrations and much more, so that you’ll learn how to take advantage of them right away. Also being covered:
- Understand the use cases
- Gain practical knowledge that can be used right away
Keynote
Wednesday:
Shireesh Thota, Vice President of Azure Join Microsoft’s Shireesh Thota and Microsoft engineering leaders for a keynote delivered live from Seattle. We’ll showcase how the latest from Microsoft across databases, analytics, including the recently announced Fabric, seamlessly integrate to accelerate the power of your data.
General Sessions
30+ more sessions over three days: Check them all out here.
From SQL Server to Azure SQL and analytics and governance, Microsoft’s experts will bring the latest product develops to help you build the right data platform to solve your business needs.
Connect, Grow, Learn with us!
As a special offer from Microsoft, enter the code AZURE150 at checkout to receive $150 off on the 3-Day conference pass (in-person).
SQL Server: 30 and thriving!
Already registered? Pop on by opening night as we say Happy Birthday SQL Server!
Register today at https://passdatacommunitysummit.com/
See you there!
by Contributed | Nov 3, 2023 | Technology
This article is contributed. See the original author and article here.
Introduction
Containers technologies are no longer something new in the industry. It all started focusing on how to deploy reproducible development environments but now you can find many other fields where applying containers, or some of the underlying technologies used to implement them, are quite common.
I will not cover here Azure Container Instances nor Azure Kubernetes Services. For an example of the latter you can browse this article NDv4 in AKS. ACI will be explained in another article.
Currently there are many options available when working with containers, Linux seasoned engineers quite likely have worked with LXC; later Docker revolutionized the deployment of development environments, more recently other alternatives like Podman have emerged and are now competing for a place in many fields.
However, in HPC, we have been working for some years with two different tools, Shifter as the first fully focused containers project for supercomputers and Singularity. I will show you how to use Singularity in HPC clusters running in Azure. I will also explain how to use Podman for running AI workloads using GPUs in Azure VMs.
Running AI workloads using GPU and containers
Running AI workloads do not need the presence of GPUs, but almost all the frameworks for machine learning/deep learning are designed to make use of them. So, I will assume GPU compute resources are required in order to run any AI workload.
There are many ways of taking advantage of GPU compute resource within containers. For example, you can run the whole container in privileged mode in order to get access to all the hardware available in the host VM, some nuances must be highlighted here because privileged mode cannot grant more permissions than those inherent to the user running the container. This means running a container as root in privileged mode is way different than running the container as a regular user with less privileges.
The most common way to get access to the GPU resources is via nvidia-container-toolkit, this package contains a hook in line with OCI standard (see references below) providing direct access to GPU compute resources within the container.
I will use a regular VM using Nvidia T4 Tesla GPU (NC8as_T4_v3) running RHEL 8.8. Let’s get started.
These are all the steps required to run AI workloads using containers and GPU resources in a VM running in Azure:
- A VM using any family of N-series (for AI workloads like machine learning, deep learning, etc… NC or ND are recommended) and a supported operating system.
- Install CUDA drivers and CUDA toolkit if required. You can omit this if you are using DSVM images from Marketplace, these images come with all required drivers preinstalled.
- Install your preferred container runtime environment and engine to work with containers.
- Install nvidia-container-toolkit.
- Run a container using any image with the tools required to check the GPU usage like nvidia-smi command. Using any container from NGC is more than recommended to avoid additional steps.
- Create the image with your code or commit the changes in a running container.
I will start with step 2 because I’m sure there is no need to explain how to create a new VM with N-series.
Installing CUDA drivers
There is no specific restriction about which CUDA release must be installed. You have the freedom to choose the latest version from Nvidia website, for example.
$ wget https://developer.download.nvidia.com/compute/cuda/repos/rhel8/x86_64/cuda-rhel8.repo -O /etc/yum.repos.d/cuda-rhel8.repo
$ sudo dnf clean all
$ sudo dnf -y install nvidia-driver
Let’s check if the drivers are installed correctly by using nvidia-smi command:
[root@hclv-jsaelices-nct4-rhel88 ~]# nvidia-smi
Fri Nov 3 17:41:03 2023
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.104.12 Driver Version: 535.104.12 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 Tesla T4 Off | 00000001:00:00.0 Off | Off |
| N/A 51C P0 30W / 70W | 2MiB / 16384MiB | 7% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| No running processes found |
+---------------------------------------------------------------------------------------+
Installing container runtime environment and engine
As I commented in the introduction, Podman will be our main tool to run containers. By default, Podman will use runc as the runtime environment, runc adheres to OCI standard so no additional steps to make sure nvidia-container-toolkit will work in our VM.
$ sudo dnf install -y podman
I won’t explain here all the benefits of using Podman against Docker. I’ll just mention Podman is daemonless and a most modern implementation of all technologies required to work with containers like control groups, layered filesystems and namespaces to name a few.
Let’s verify Podman was successfully installed using podman info command:
[root@hclv-jsaelices-nct4-rhel88 ~]# podman info | grep -i ociruntime -A 19
ociRuntime:
name: runc
package: runc-1.1.4-1.module+el8.8.0+18060+3f21f2cc.x86_64
path: /usr/bin/runc
version: |-
runc version 1.1.4
spec: 1.0.2-dev
go: go1.19.4
libseccomp: 2.5.2
os: linux
remoteSocket:
path: /run/podman/podman.sock
security:
apparmorEnabled: false
capabilities: CAP_SYS_CHROOT,CAP_NET_RAW,CAP_CHOWN,CAP_DAC_OVERRIDE,CAP_FOWNER,CAP_FSETID,CAP_KILL,CAP_NET_BIND_SERVICE,CAP_SETFCAP,CAP_SETGID,CAP_SETPCAP,CAP_SETUID
rootless: false
seccompEnabled: true
seccompProfilePath: /usr/share/containers/seccomp.json
selinuxEnabled: true
serviceIsRemote: false
Installing nvidia-container-toolkit
Podman fully supports OCI hooks and that is precisely what nvidia-container-toolkit provides. Basically, OCI hooks are custom actions performed during the lifecycle of the container. It is a prestart hook that is called when you run a container providing access to the GPU using the drivers installed in the host VM. The already created repository is also providing this package so let’s install it using dnf:
$ sudo dnf install -y nvidia-container-toolkit
Podman is daemonless so no need to add the runtime using nvidia-ctk runtime configure, but, in this case, an additional step is required to generate the CDI configuration file:
$ sudo nvidia-ctk cdi generate --output=/etc/cdi/nvidia.yaml
$ nvidia-ctk cdi list
INFO[0000] Found 2 CDI devices
nvidia.com/gpu=0
nvidia.com/gpu=all
Running containers for AI workloads
Now, we have all the environment ready for running new containers for AI workloads. I will make use of NGC images from Nvidia to save time and avoid the creation of custom ones. Please, keep in mind some of them are quite big so make sure you have enough space in your home folder.
Let’s start with an Ubuntu 20.04 image with CUDA already installed on it:
[jsaelices@hclv-jsaelices-nct4-rhel88 ~]$ podman run --security-opt=label=disable --device=nvidia.com/gpu=all nvcr.io/nvidia/cuda:12.2.0-devel-ubuntu20.04
==========
== CUDA ==
==========
CUDA Version 12.2.0
Container image Copyright (c) 2016-2023, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
This container image and its contents are governed by the NVIDIA Deep Learning Container License.
By pulling and using the container, you accept the terms and conditions of this license:
https://developer.nvidia.com/ngc/nvidia-deep-learning-container-license
A copy of this license is made available in this container at /NGC-DL-CONTAINER-LICENSE for your convenience.
Another example running the well-known DeviceQuery tool that comes with CUDA toolkit:
[jsaelices@hclv-jsaelices-nct4-rhel88 ~]$ podman run --security-opt=label=disable --device=nvidia.com/gpu=all nvcr.io/nvidia/k8s/cuda-sample:devicequery-cuda11.7.1-ubuntu20.04
/cuda-samples/sample Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "Tesla T4"
CUDA Driver Version / Runtime Version 12.2 / 11.7
CUDA Capability Major/Minor version number: 7.5
Total amount of global memory: 15948 MBytes (16723214336 bytes)
(040) Multiprocessors, (064) CUDA Cores/MP: 2560 CUDA Cores
GPU Max Clock rate: 1590 MHz (1.59 GHz)
Memory Clock rate: 5001 Mhz
Memory Bus Width: 256-bit
L2 Cache Size: 4194304 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total shared memory per multiprocessor: 65536 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 1024
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 3 copy engine(s)
Run time limit on kernels: No
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
Device supports Unified Addressing (UVA): Yes
Device supports Managed Memory: Yes
Device supports Compute Preemption: Yes
Supports Cooperative Kernel Launch: Yes
Supports MultiDevice Co-op Kernel Launch: Yes
Device PCI Domain ID / Bus ID / location ID: 1 / 0 / 0
Compute Mode:
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 12.2, CUDA Runtime Version = 11.7, NumDevs = 1
Result = PASS
You can see in these examples that I’m running those containers with my user without root privileges (rootless environment) with no issues, and that is because of that option passed to the podman run command, –security-opt=label=disable. This command is used to disable all SELinux labeling. This is performed this way for the sake of this article’s length. I could use a SELinux policy created with Udica or use the one that comes with Nvidia (nvidia-container.pp) but I preferred to disable the labeling for these specific samples.
Now it is time to try running specific frameworks for AI using Python. Let’s try with Pytorch:
[jsaelices@hclv-jsaelices-nct4-rhel88 ~]$ podman run --rm -ti --security-opt=label=disable --device=nvidia.com/gpu=all pytorch/pytorch
root@7cb030cc3b47:/workspace# python
Python 3.10.13 (main, Sep 11 2023, 13:44:35) [GCC 11.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
>>> torch.cuda.is_available()
True
>>>
As you can see PyTorch framework can see the GPU and would be able to run any code using GPU resources without any issue.
I won’t create any custom image as suggested in the last step described previously. That can be a good exercise for the reader, so it is your turn to test your skills running containers and using GPU resources.
Running HPC workloads using containers
Now it is time to run HPC applications in our containers. You can also use podman to run those, in fact there is an improvement over podman developed jointly by NERSC and Red Hat called Podman-HPC but, for this article, I decided to use Singularity which is well-know in HPC field.
For this section, I will run some containers using Singularity in a cluster created with CycleCloud using HB120rs_v3 size for the compute nodes. For the OS, I’ve chosen Almalinux 8.7 HPC image from Azure Marketplace.
I will install Singularity manually but this can be automated using cluster-init in CycleCloud.
Installing Singularity in the cluster
In Almalinux 8.7 HPC image epel repository is installed by default so you can easily install singularity with a single command:
[root@slurmhbv3-hpc-2 ~]# yum install -y singularity-ce
Last metadata expiration check: 1:16:36 ago on Fri 03 Nov 2023 04:38:39 PM UTC.
Dependencies resolved.
=========================================================================================================================================================
Package Architecture Version Repository Size
=========================================================================================================================================================
Installing:
singularity-ce x86_64 3.11.5-1.el8 epel 44 M
Installing dependencies:
conmon x86_64 3:2.1.6-1.module_el8.8.0+3615+3543c705 appstream 56 k
criu x86_64 3.15-4.module_el8.8.0+3615+3543c705 appstream 517 k
crun x86_64 1.8.4-2.module_el8.8.0+3615+3543c705 appstream 233 k
libnet x86_64 1.1.6-15.el8 appstream 67 k
yajl x86_64 2.1.0-11.el8 appstream 40 k
Installing weak dependencies:
criu-libs x86_64 3.15-4.module_el8.8.0+3615+3543c705 appstream 37 k
Transaction Summary
=========================================================================================================================================================
Install 7 Packages
Total download size: 44 M
Installed size: 135 M
Downloading Packages:
(1/7): criu-libs-3.15-4.module_el8.8.0+3615+3543c705.x86_64.rpm 1.0 MB/s | 37 kB 00:00
(2/7): conmon-2.1.6-1.module_el8.8.0+3615+3543c705.x86_64.rpm 1.1 MB/s | 56 kB 00:00
(3/7): crun-1.8.4-2.module_el8.8.0+3615+3543c705.x86_64.rpm 5.3 MB/s | 233 kB 00:00
(4/7): libnet-1.1.6-15.el8.x86_64.rpm 1.5 MB/s | 67 kB 00:00
(5/7): criu-3.15-4.module_el8.8.0+3615+3543c705.x86_64.rpm 4.5 MB/s | 517 kB 00:00
(6/7): yajl-2.1.0-11.el8.x86_64.rpm 954 kB/s | 40 kB 00:00
(7/7): singularity-ce-3.11.5-1.el8.x86_64.rpm 11 MB/s | 44 MB 00:04
---------------------------------------------------------------------------------------------------------------------------------------------------------
Total 7.0 MB/s | 44 MB 00:06
Extra Packages for Enterprise Linux 8 - x86_64 1.6 MB/s | 1.6 kB 00:00
Importing GPG key 0x2F86D6A1:
Userid : "Fedora EPEL (8) "
Fingerprint: 94E2 79EB 8D8F 25B2 1810 ADF1 21EA 45AB 2F86 D6A1
From : /etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-8
Key imported successfully
Running transaction check
Transaction check succeeded.
Running transaction test
Transaction test succeeded.
Running transaction
Preparing : 1/1
Installing : yajl-2.1.0-11.el8.x86_64 1/7
Installing : libnet-1.1.6-15.el8.x86_64 2/7
Running scriptlet: libnet-1.1.6-15.el8.x86_64 2/7
Installing : criu-3.15-4.module_el8.8.0+3615+3543c705.x86_64 3/7
Installing : criu-libs-3.15-4.module_el8.8.0+3615+3543c705.x86_64 4/7
Installing : crun-1.8.4-2.module_el8.8.0+3615+3543c705.x86_64 5/7
Installing : conmon-3:2.1.6-1.module_el8.8.0+3615+3543c705.x86_64 6/7
Installing : singularity-ce-3.11.5-1.el8.x86_64 7/7
Running scriptlet: singularity-ce-3.11.5-1.el8.x86_64 7/7
Verifying : conmon-3:2.1.6-1.module_el8.8.0+3615+3543c705.x86_64 1/7
Verifying : criu-3.15-4.module_el8.8.0+3615+3543c705.x86_64 2/7
Verifying : criu-libs-3.15-4.module_el8.8.0+3615+3543c705.x86_64 3/7
Verifying : crun-1.8.4-2.module_el8.8.0+3615+3543c705.x86_64 4/7
Verifying : libnet-1.1.6-15.el8.x86_64 5/7
Verifying : yajl-2.1.0-11.el8.x86_64 6/7
Verifying : singularity-ce-3.11.5-1.el8.x86_64 7/7
Installed:
conmon-3:2.1.6-1.module_el8.8.0+3615+3543c705.x86_64 criu-3.15-4.module_el8.8.0+3615+3543c705.x86_64
criu-libs-3.15-4.module_el8.8.0+3615+3543c705.x86_64 crun-1.8.4-2.module_el8.8.0+3615+3543c705.x86_64
libnet-1.1.6-15.el8.x86_64 singularity-ce-3.11.5-1.el8.x86_64
yajl-2.1.0-11.el8.x86_64
Complete!
I won’t explain all the pros and cons when using Singularity over other containers alternatives. I will just highlight some of the security features provided by Singularity and, especially, the format of the image used (Singularity Image Format, SIF) during the examples.
One of the biggest advantages of using Singularity is the size of the images, SIF is a binary format and is very compact comparing to regular layered Docker images. See below an example of the image of OpenFOAM:
[jsaelices@slurmhbv3-hpc-2 .singularity]$ singularity pull docker://opencfd/openfoam-default
INFO: Converting OCI blobs to SIF format
INFO: Starting build...
Getting image source signatures
Copying blob 855f75e343f2 done |
Copying blob b9158799e696 done |
Copying blob 561d59533bc7 done |
Copying blob 96b48e52a343 done |
Copying blob a8cede8f862e done |
Copying blob 3153aa388d02 done |
Copying blob 3efcde42d95a done |
Copying config dc7161e162 done |
Writing manifest to image destination
2023/11/03 17:59:51 info unpack layer: sha256:3153aa388d026c26a2235e1ed0163e350e451f41a8a313e1804d7e1afb857ab4
2023/11/03 17:59:51 info unpack layer: sha256:855f75e343f27a0838944f956bdf15a036a21121f249957cf121b674a693c0c9
2023/11/03 17:59:51 info unpack layer: sha256:a8cede8f862e92aa526c663d34038c1152fb56f3e7005a1bcefd29219a77fd6f
2023/11/03 17:59:54 info unpack layer: sha256:561d59533bc76812ab48aef920990af0217af17b23aaccc059a5e660a2ca55b0
2023/11/03 17:59:54 info unpack layer: sha256:b9158799e696063a99dc698caef940b9e60ca7ff9c1edd607fc4688d953a1aa6
2023/11/03 17:59:54 info unpack layer: sha256:96b48e52a343650d16be2c5ba9800b30ff677f437379cc70e05c255d1212b52e
2023/11/03 18:00:03 info unpack layer: sha256:3efcde42d95ab617eac299e62eb8800b306a0279e9368daf2141337f22bf8218
INFO: Creating SIF file...
You can see the size is about 350 MB:
[jsaelices@slurmhbv3-hpc-2 .singularity]$ ls -lh openfoam-default_latest.sif
-rwxrwxr-x. 1 jsaelices jsaelices 349M Nov 3 18:00 openfoam-default_latest.sif
Docker is using a layered format that is substantially bigger in size:
[root@slurmhbv3-hpc-1 ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
opencfd/openfoam-default latest dc7161e16205 3 months ago 1.2GB
Running MPI jobs with Singularity
Singularity is fully compatible with MPI and there are 2 different ways to submit an MPI job with SIF images.
I will use the bind method for its simplicity but you can also use the hybrid method if binding volumes between the host and the container is not desirable.
Let’s create a simple definition file called mydefinition.def (similar to Dockerfile or Containerfile):
Bootstrap: docker
From: almalinux
%files
/shared/bin/mpi_test /shared/bin/mpi_test
%environment
export MPI_HOME=/opt/intel/oneapi/mpi/2021.9.0
export MPI_BIN=/opt/intel/oneapi/mpi/2021.9.0/bin
export LD_LIBRARY_PATH=/opt/intel/oneapi/mpi/2021.9.0/libfabric/lib:/opt/intel/oneapi/mpi/2021.9.0/lib/release:/opt/intel/oneapi/mpi/2021.9.0/lib:/opt/intel/oneapi/tbb/2021.9.0/env/../lib/intel64/gcc4.8:/opt/intel/oneapi/mpi/2021.9.0//libfabric/lib:/opt/intel/oneapi/mpi/2021.9.0//lib/release:/opt/intel/oneapi/mpi/2021.9.0//lib:/opt/intel/oneapi/mkl/2023.1.0/lib/intel64:/opt/intel/oneapi/compiler/2023.1.0/linux/lib:/opt/intel/oneapi/compiler/2023.1.0/linux/lib/x64:/opt/intel/oneapi/compiler/2023.1.0/linux/compiler/lib/intel64_lin
export MPI_INCLUDE=/opt/intel/oneapi/mpi/2021.9.0/include
export HOST=$(hostname)
%runscript
echo "Running MPI job inside Singularity: $HOST"
echo "MPI job submitted: $*"
exec echo
Here, I’m just using the Almalinux image from Docker Hub, copying the MPI application, defining some useful environment variables and a few simple commands to execute when the container is called without any parameter.
Now, it is time to build the SIF image:
[root@slurmhbv3-hpc-1 jsaelices]# singularity build mympitest.sif mpi_sample.def
INFO: Starting build...
2023/11/03 18:07:49 info unpack layer: sha256:92cbf8f6375271a4008121ff3ad96dbd0c10df3c4bc4a8951ba206dd0ffa17e2
INFO: Copying /shared/bin/mpi_test to /shared/bin/mpi_test
INFO: Copying /shared/bin/openmpi-test to /shared/bin/openmpi-test
INFO: Adding environment to container
INFO: Adding runscript
INFO: Creating SIF file...
INFO: Build complete: mympitest.sif
I’m going to just execute the MPI application binding the folder where the whole Intel MPI is laying:
[jsaelices@slurmhbv3-hpc-1 ~]$ singularity exec --hostname inside-singularity --bind /opt/intel:/opt/intel mympitest.sif /shared/bin/mpi_test
Hello world: rank 0 of 1 running on inside-singularity
Let’s call the app using mpiexec as we do with any other MPI job:
[jsaelices@slurmhbv3-hpc-1 ~]$ mpiexec -n 2 -hosts slurmhbv3-hpc-1 singularity exec --bind /opt/intel:/opt/intel mympitest.sif /shared/bin/mpi_test
Hello world: rank 0 of 2 running on slurmhbv3-hpc-1
Hello world: rank 1 of 2 running on slurmhbv3-hpc-1
In the next step, I will use SLURM scheduler to submit the job. In order to do that, I’m creating a very simple script:
#!/bin/bash
#SBATCH --job-name singularity-mpi
#SBATCH -N 2
#SBATCH -o %N-%J-%x
module load mpi/impi_2021.9.0
mpirun -n 4 -ppn 2 -iface ib0 singularity exec --bind /opt/intel:/opt/intel mympitest.sif /shared/bin/mpi_test
Let’s submit the job with sbatch:
$ sbatch singularity.sh
Let’s check the output file of the submitted job:
[jsaelices@slurmhbv3-hpc-1 ~]$ cat slurmhbv3-hpc-1-2-singularity-mpi
Hello world: rank 0 of 4 running on slurmhbv3-hpc-1
Hello world: rank 1 of 4 running on slurmhbv3-hpc-1
Hello world: rank 2 of 4 running on slurmhbv3-hpc-2
Hello world: rank 3 of 4 running on slurmhbv3-hpc-2
With this example this article ends.
You’ve seen how to run containers, how to make use of GPU and run AI workloads in a simple and effective way. You’ve also learnt how to run Singularity containers and MPI jobs easily. You can use all this material as a starting point to extend your knowledge and apply it to more complex tasks. Hope you enjoyed it.
References
Podman
Podman HPC
Nvidia Container Toolkit
Singularity containers

Recent Comments