
by Contributed | Sep 1, 2022 | Business, Microsoft 365, Technology
This article is contributed. See the original author and article here.
As more sophisticated cyber criminals take aim at hybrid and remote workers, Microsoft is working to raise awareness among Exchange Online customers that one of the most important security steps they can take is to move away from outdated, less secure protocols, like Basic Authentication. As previously announced, we are turning off Basic Authentication in Exchange Online for all tenants starting October 1, 2022.
The post Microsoft retires Basic Authentication in Exchange Online appeared first on Microsoft 365 Blog.
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.
by Contributed | Aug 31, 2022 | Technology
This article is contributed. See the original author and article here.
We are excited to announce the General Availability (GA) of enabling Zone Redundancy for Azure SQL Hyperscale databases. The zone redundant configuration utilizes Azure Availability Zones to replicate databases across multiple physical locations within an Azure region. By selecting zone redundancy, you can make all layers of your Hyperscale databases resilient to a much larger set of failures, including catastrophic datacenter outages, without any changes of the application logic. For more information see Hyperscale zone redundant availability.
Creating a zone redundant Hyperscale Database
A zone redundant Hyperscale database can be created with Portal, Azure CLI, PowerShell, or REST API. Zone redundancy for Hyperscale service tier can only be specified at database creation. This setting cannot be modified once the resource is provisioned. Database copy, point-in-time restore, or creating a geo-replica can be used to update the zone redundant configuration for an existing Hyperscale database.
Portal
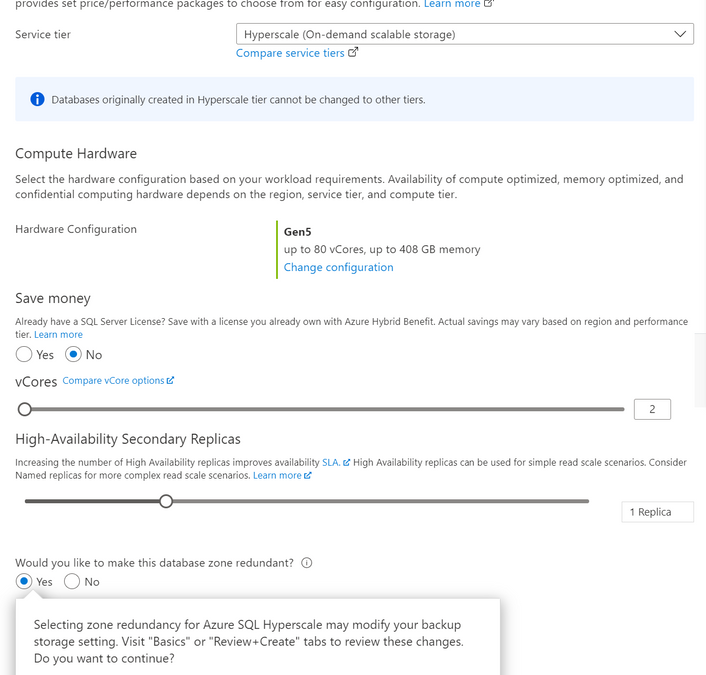
The following image illustrates how to use Azure portal to configure a new Hyperscale database to be zone redundant. This can be configured in the Configure database blade when creating a new database, creating a geo replica, creating a copy database, doing a point in time restore or doing a geo restore. Zone-redundant or Geo-zone-redundant backup storage and at least 1 High-Availability Secondary Replica must be specified.

CLI
The following CLI commands can be used to create a zone redundant Hyperscale database using the –zone-redundant {false, true} parameter.
The Hyperscale database must have at least 1 high availability replica and zone-redundant or geo-zone-redundant backup storage. Below is an example CLI command for creating a new zone redundant Hyperscale database.
az sql db create -g mygroup -s myserver -n mydb -e Hyperscale -f Gen5 –ha-replicas 1 –-zone-redundant -–backup-storage-redundancy Zone
PowerShell
The following PowerShell commands can be used to create a zone redundant Hyperscale database using the -ZoneRedundant parameter.
The Hyperscale database must have at least 1 high availability replica and zone-redundant or geo-zone-redundant backup storage must be specified. Below is an example PowerShell command for creating a new zone redundant Hyperscale database.
New-AzSqlDatabase -ResourceGroupName "ResourceGroup01" -ServerName "Server01" -DatabaseName "Database01" -Edition “Hyperscale” -HighAvailabilityReplicaCount 1 -ZoneRedundant -BackupStorageRedundancy Zone
Current Limitations
- Zone redundant configuration can only be specified during database creation. This setting cannot be modified once the resource is provisioned. Database copy, point-in-time restore, or creating a geo-replica can be used to update the zone redundant configuration for an existing Hyperscale database. When using one of these update options, if the target database is in a different region than the source or if the database backup storage redundancy from the target differs from the source database, the copy operation will be a size of data operation.
- Named replicas are not currently supported.
- Only Gen5 compute is supported.
- Zone redundancy cannot currently be specified when migrating an existing database from another Azure SQL Database service tier to Hyperscale.
Regions where this is available
All Azure regions that have Availability Zones support zone redundant Hyperscale database.
by Contributed | Aug 30, 2022 | Technology
This article is contributed. See the original author and article here.
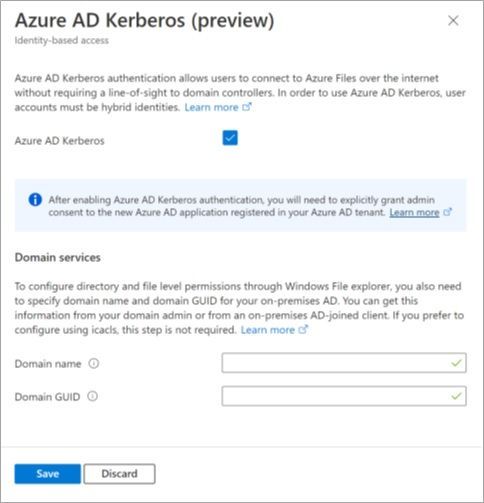
We are excited to announce Azure Files integration with Azure Active Directory (Azure AD) Kerberos for hybrid identities. With this release, identities in Azure AD can mount and access Azure file shares without the need for line-of-sight to an Active Directory domain controller.
Until now, Azure Files supported identity-based authentication over Server Message Block (SMB) through two types of Domain Services: on-premises Active Directory Domain Services (AD DS) and Azure Active Directory Domain Services (Azure AD DS). On-premises AD DS requires clients to have line-of-sight to the domain controller, while Azure AD DS requires deploying domain services onto Azure AD and domain joining to Azure AD DS. Azure AD Kerberos is a new addition to these identity-based authentication methods. Azure AD Kerberos allows Azure AD to issue Kerberos service tickets over HTTPS for service applications in Azure AD. This removes the need to setup and manage another domain service, while also removing the line-of-sight requirement to the domain controller when authenticating with Azure Files. For this experience, the clients connecting to Azure Files need to be Azure AD-joined clients (or hybrid Azure AD-joined), and the user identities must be hybrid identities, managed in Active Directory.
This experience builds on what we previously announced for FSLogix profiles support. Now, the experience is much simpler, and the use cases are no longer limited to Azure Virtual Desktop user profiles.
To learn more and get started, visit our documentation page.

by Contributed | Aug 29, 2022 | Technology
This article is contributed. See the original author and article here.
Microsoft partners like Audioburst, Fivetran, Skkynet, and YData Labs deliver transact-capable offers, which allow you to purchase directly from Azure Marketplace. Learn about these offers below:
|
Audioburst – Audio Content Analysis: Audioburst’s enhanced content analysis tools extract actionable data points, enhance search and discovery, improve recommendations, and provide monetization opportunities using NLP and AI on Azure. |
 |
Fivetran Data Pipelines: Fivetran automatically ingests and centralizes your data from hundreds of data sources using over 180 data connectors. Fivetran data pipelines support a variety of data warehouses, including Microsoft Azure Synapse Analytics, Azure Blog Storage, Azure Databricks, and Snowflake.
|
 |
Skkynet DataHub: With the Skkynet DataHub, you can integrate live IoT processes using standard protocols, including OPC, MQTT, and Modbus, as well as connect SCADA systems, Azure Data Lake, and more for real-time OT/IT integration and remote data access.
|
 |
YData – Accelerate Development and Increase ROI of Your AI Solutions: YData helps data science teams collaborate, build great training data sets, and exponentially accelerate AI and ML projects while preserving security, privacy, and data fidelity without leaving Azure.
|
by Contributed | Aug 29, 2022 | Business, Microsoft 365, Technology
This article is contributed. See the original author and article here.
With Microsoft Teams Phone, we have been unabashed in our belief that the future of calling is built on VoIP calling that delivers rich voice and video experiences across organizational boundaries. Teams Phone VoIP calling capabilities are complemented by an enterprise-grade PSTN service that provides customers with the ultimate flexibility in how they communicate and collaborate.
The post Discover how Microsoft Teams Phone keeps 12 million PSTN users connected appeared first on Microsoft 365 Blog.
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments