This article is contributed. See the original author and article here.
Today’s companies are dealing with data of many different types, in many different sizes, and coming in at varying frequencies. These companies are looking beyond the limitations of traditional data architectures to enable cloud scale analytics, data science, and machine learning on all of this data. One architecture pattern that addresses many of the challenges of traditional data architectures is the lakehouse architecture.
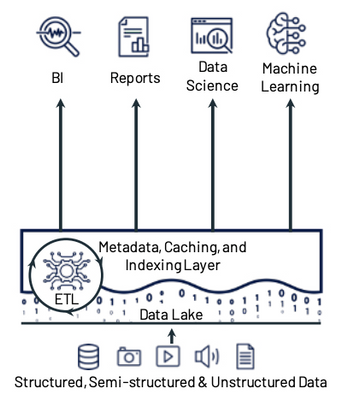
Lakehouses combine the low cost and flexibility of data lakes with the reliability and performance of data warehouses. The lakehouse architecture provides several key features including:
- Reliable, scalable, and low-cost storage in an open format
- ETL and stream processing with ACID transactions
- Metadata, versioning, caching, and indexing to ensure manageability and performance when querying
- SQL APIs for BI and reporting along with declarative DataFrame APIs for data science and machine learning
Lakehouse Principles and Components

When building a lakehouse architecture, keep these 3 key principles and their associated components in mind:
- A data lake to store all your data, with a curated layer in an open-source format. The data lake should be able to accommodate data of any type, size, and speed. The format of the curated data in the lake should be open, integrated with cloud native security services, and it should support ACID transactions.
- A foundational compute layer built on open standards. There should be a foundational compute layer that supports all of the core lakehouse use cases including curating the data lake (ETL and stream processing), data science and machine learning, and SQL analytics on the data lake. That layer should also be built on open standards that ensure rapid innovation and are non-locking and future proof.
- Easy integration for additional and/or new use cases. No single service can do everything. There are always going to be new or additional use cases that aren’t a part of the core lakehouse use cases. These new or additional use cases often need specialized services or tools. This is why easy integrations between the curated data lake, the foundational compute layer, and other services and tools are key requirements.
Let’s look at how Azure Databricks along with Azure Data Lake Storage and Delta Lake can help build a lakehouse architecture using these 3 principles.
Open, Transactional Storage with Azure Data Lake Storage + Delta Lake

One part of the first principle is to have a data lake to store all your data. Azure Data Lake Storage offers a cheap, secure object store capable of storing data of any size (big and small), of any type (structured or unstructured), and at any speed (fast or slow). The second part of the first principle is to have the Curated data in the data lake be in an open format that supports ACID transactions. Companies often use Delta Lake to build this curated zone of their data lake. Delta Lake is simply an open file format based on Parquet that can be stored in Azure Data Lake Storage. Among other things, it supports ACID transactions (UPDATE, DELETE, and even MERGE), time travel, schema evolution/enforcement, and streaming as a source and a sync. These features make the Delta Lake format used in Azure Data Lake Storage an ideal component for the first principle of the lakehouse architecture.
Azure Databricks for Core Lakehouse Use Cases
The 2nd principle discussed above is to have a foundational compute layer built on open standards that can handle all of the core lakehouse use cases. The Photon-powered Delta Engine found in Azure Databricks is an ideal layer for these core use cases. The Delta Engine is rooted in Apache Spark, supporting all of the Spark APIs along with support for SQL, Python, R, and Scala. In addition, Azure Databricks provides other open source frameworks including:

- Always the latest and greatest version of Spark which is ideal for ETL/ELT, stream processing, distributed data science and ML, and SQL analytics on the data lake
- Optimized compute for the Delta Lake file format which includes data skipping and data source caching capabilities for faster queries
- A machine learning runtime with pre-installed, optimized libraries for model development and training. This also includes the open-source Koalas, which provides data scientists the ability to work on big data with a Pandas API that runs on top of Apache Spark
- Tightly integrated MLflow to help develop, train, and operationalize (batch, stream, or API) data science and machine learning models
Azure Databricks also provides a collaborative workspace along with the Delta Engine that includes an integrated notebook environment as well as a SQL Analytics environment designed to make it easier for analysts to write SQL on the data lake, visualize results, build dashboards, and schedule queries and alerts. All of this makes Azure Databricks and the Delta Engine and ideal foundational compute layer for core lakehouse use cases.
Integrated Services for Other/New Use Cases
The final principle focuses on key integrations between the Curated data lake, foundational compute layer, and other services. This is necessary because there will always be specialized or new use cases that are not “core” lakehouse use cases. Also, different business areas may prefer different or additional tools (especially in the SQL analytics and BI space). A lakehouse built on Azure Data Lake Storage, Delta Lake, and Azure Databricks provides easy integrations for these new or specialized use cases.

- Azure Data Lake Storage is a storage service that is supported by all of the data and AI services in Azure.
- Delta Lake is an open source storage format with supported interfaces for Spark, Hive, Presto, Python, Scala, and Java. It also has native connectors in Azure services like Azure Synapse and Data Factory and it can be used with other services like Power BI, HDInsight, and Azure Machine Learning.
- Azure Databricks is tightly integrated into the rest of the Azure ecosystem with optimized, secure connectivity to services like Azure Data Factory, Power BI, and Azure Synapse. The service also includes REST API, Command Line, and JDBC/ODBC interfaces allowing for integrations with just about any tool or service.
To conclude, the lakehouse architecture pattern is one that will continue to be adopted because of its flexibility, cost efficiency, and open standards. Building an architecture with Azure Databricks, Delta Lake, and Azure Data Lake Storage provides the foundation for lakehouse use cases that is open, extensible, and future proof.
To learn more about Lakehouse architecture, check out this research paper and blog from Databricks and join an Azure Databricks event.
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments