This article is contributed. See the original author and article here.
I needed to go through this subject this week so I thought that would be a good opportunity to share SQL Serverless Architecture concepts.
1) What is the difference between SQLOD and the former SQLDW?
SQL Serverless or SQL On-demand
- Grow or shrink compute power, within a dedicated SQL pool, without moving data.
- Pause compute capacity while leaving data intact, so you only pay for storage.
- Resume compute capacity during operational hours.
SQL DW you can actually pause and resume. You insert, update and delete. You have storage with your data which SQLDW is held responsible.
What is SQLOD?
SQLOD is a query service over the data in your data lake. You do not need to pause or resume. It is a service per comsumption or per demand. The service is resilient to failure and elastic.
Note: Serverless SQL pool has no local storage, only metadata objects are stored in databases. Basically is for reading, only.
What it means resilient to failures and elastic?
It means it auto-scale the node’s resources if required by the engine while querying your file and it means also if there is any failure in any node it recovers without any user intervention.
What is supported on Serverless?
Supported T-SQL:
- Full SELECT surface area is supported, including a majority of SQL functions
- CETAS – CREATE EXTERNAL TABLE AS SELECT
- DDL statements related to views and security only
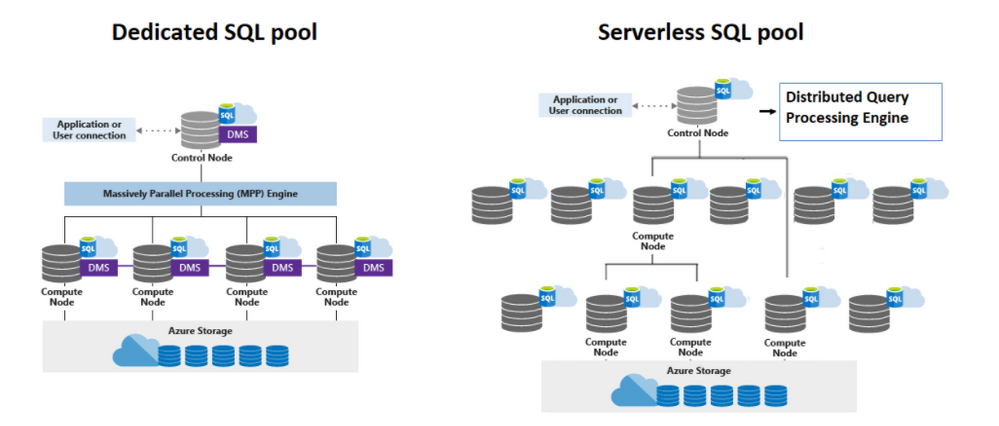
How does it work?
- DQP or Distributed Query Processing.
- Compute Node
DQP is responsible per optimize and orchestrate distributed execution of user queries by splitting them into smaller queries that will be executed on Compute nodes.
The Compute Nodes will execute the tasks creates by the DQP. The tasks are pretty much the query logic break in chunks of data to be processed. Those chunks of data are the files organized in data cells. How many data cells and tasks will be executed depends on the plan optimization.
Plan optimization also depends on the stats. The more serverless the SQL pool knows about your data, the faster it can execute queries against it and in the end, the plan chosen is based on cost, lowest cost. Note: Automatic creation of statistics is turned on for Parquet files. For CSV files, you need to create statistics manually.
Ref: Synapse SQL architecture – Azure Synapse Analytics | Microsoft Docs
Serverless SQL pool – Azure Synapse Analytics | Microsoft Docs
That is it!
Liliam Leme
UK Engineer.
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments