This article is contributed. See the original author and article here.
HDInsight Realtime Inference
In this example, we can see how to Perform ML modeling on Spark and perform real time inference on streaming data from Kafka on HDInsight. We are deploying HDInsight 4.0 with Spark 2.4 to implement Spark Streaming and HDInsight 3.6 with Kafka
NOTE: Apache Kafka and Spark are available as two different cluster types. HDInsight cluster types are tuned for the performance of a specific technology; in this case, Kafka and Spark. To use both together, you must create an Azure Virtual network and then create both a Kafka and Spark cluster on the virtual network. For an example of how to do this using an Azure Resource Manager template, see modular-template.json file in the ARM-Template folder of this GitHub project.
Understanding the Usecase
Insurance companies use multiple inputs including individual/enterprise history, market conditions, competitor analysis, previous claims, local demographics, weather conditions, regional traffic data and other external/internal sources to identify the risk category of a potential customer. These inputs can come from multiple sources at very different intervals.
Let’s deploy a scenario in which we use historic data to create ML models on Spark. Then, we use Kafka to stream real-time requests from Insurance users or the agents. As new requests come in, we evaluate the users and predict in real time whether they are likely to be in a crash and how much would their next claim be, if they’re likely to be in a crash.
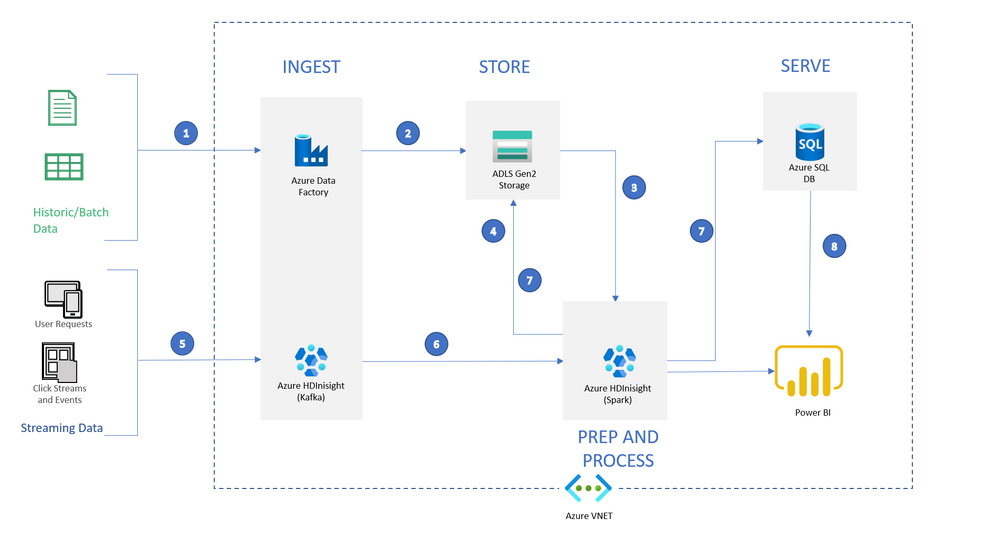
Architecture
The architecture we’re deploying today is

Data Flow:
1: Setup ADF to transfer historic data from Blob and other sources to ADLS
2: Load historic data into ADLS storage that is associated with Spark HDInsight cluster using Azure Data Factory (In this example, we will simulate this step by transferring a csv file from a Blob Storage )
3: Use Spark HDInsight cluster (HDI 4.0, Spark 2.4.0) to create ML models
4: Save the models back in ADLS Gen2
5: Kafka HDInsight will receive streaming requests for predictions (In this example, we are simulating streaming data in Kafka using a static file)
6: Spark HDInsight cluster will receive the streaming records and infer predictions during runtime using models saved in ADLS Storage
7: Once inference is done, Spark HDInsight cluster will write the files to both ADLS Storage in JSON format and SQL database into a pre-defined table
8: Power BI can now access data from both SQL table and Spark Cluster into a dashboard for further analysis (NOTE: In this example, we only have SQL setup)
Let’s get into it:
To complete the exercise, you’ll need:
- A Microsoft Azure subscription. If you don’t already have one, you can sign up for a free trial at https://azure.microsoft.com/free
- A contributor or an owner access on the subscription to create services
Step 1: Use the following button to sign in to Azure and open the template in the Azure portal:
[!CAUTION] Known Issue: Creating resources in West US, East Asia can fail while deploying SQL Database
This template will deploy all the resources seen in the architecture above
(Note: This deployment may take about 10-15 minutes. Wait until all the resources are deployed before moving to the next step)
Log into the Azure Portal and go into the resource group to make sure all the resources are deployed correctly. It should look like this:

Step 2: Go to Azure Cloud Shell (either azure.shell.com or click on cloud shell 
If you’re in a different subscription, set the subscription using the following command:
az account set <your-subscription-name>
Step 3: Clone the repository to your cloudshell and give execute permissions:
git clone https://github.com/SindhuRaghvan/HDInsight-Insurance-RealtimeML.git
chmod 777 -R HDInsight-Insurance-RealtimeML/
Step 4: Move into the first directory and run the DataUpload script. This script will update files with your unique resource names and upload all the required files to the newly deployed resources
[!NOTE] Before running this, note the resource names and passwords deployed through the ARM Template
cd HDInsight-Insurance-RealtimeML/
./Scripts/DataUpload.sh
Step 5: Take time to look through the ADF pipeline created, and then let’s run the ADF pilpeline through Azure PowerShell (Open and new session and toggle shell in the cloudshell)


If required, set subscription using the following command after replacing with your SubscriptionId and TenanntId:
Get-AzureRmSubscription
Get-AzureRmSubscription -SubscriptionId "xxxx-xxxx-xxxx-xxxx" -TenantId "yyyy-yyyy-yyyy-yyyy" | Set-AzureRmContext
This will copy the car_insurance_claim.csv file from Azure Blob storage to ADLS Storage associated with the Spark cluster. Then, it will run the spark job to create and store the ML models on the transferred data.
$resourceGroup="<your-resource-group>"
$dataFactory="<your-data-factory-name>"
$pipeline =Invoke-AzDataFactoryV2Pipeline `
-ResourceGroupName $resourceGroup `
-DataFactory $dataFactory `
-PipelineName "LoadAndModel"
Get-AzDataFactoryV2PipelineRun `
-ResourceGroupName $resourceGroup `
-DataFactoryName $dataFactory `
-PipelineRunId $pipeline
[!NOTE] This job might take about 8-10 minutes to run
Run the second command as required to monitor the pipeline run. Alternatively, you can monitor the run through the ADF portal by clicking on the resource –> “Author and Monitor” –> “Monitor” on the left menu
If you would like to see what is going on in the spark job, go to the Spark cluster on Azure Portal and click on “Jupyter Notebook” in the Overview page. Once you login, click on Upload, and upload the CarInsuranceProcessing.ipynb file from the Notebook folder. You can run through the notebook step by step.


Step 6: Go to the Predictions database resource (NOT SQL server) deployed in the portal. Click on Query editor. Login with the credentials (SQL server Authentication) used during creation of ARM Template.
[!TIP] It is possible you might see an error while logging in because of firewall settings. Update firewall settings by clicking on “Set server firewall” in the error message and add your IP to the firewall (Reference)


In the query editor, execute the following query to create a table the holds final predictions:
IF OBJECT_ID('UserData', 'U') IS NOT NULL
DROP TABLE UserData
GO
-- Create the table in the specified schema
CREATE TABLE UserData
(
ID INT, -- primary key column
BIRTH DATE,
AGE INT,
HOMEKIDS INT,
YearsOnJob INT,
INCOME INT,
MSTATUS NVARCHAR(3),
GENDER NVARCHAR(10),
EDUCATION NVARCHAR(20),
OCCUPATION NVARCHAR(20),
Travel_Time INT,
BLUEBOOK INT,
Time_In_Force INT,
CAR_TYPE NVARCHAR(20),
OLDCLAIM_AMT INT,
CLAIM_FREQ INT,
MVR_PTS INT,
CAR_AGE INT,
time_p DATETIME NOT NULL,
CLAIM_PRED FLOAT,
CRASH_PRED VARCHAR(4)
);
GO
Step 7: Go back to cloudshell bash and log into Kafka server via ssh and run the kafkaprocess.sh file inside the files/ directory. This will install all the required libraries to run our example.
ssh sshuser@<your-kafka-server>-ssh.azurehdinsight.net
./files/kafkaprocess.sh
Copy the output of the file (last line of the output) to use in a little bit

Step 8: Open another cloud shell session simultaneously and log into the spark cluster via ssh
ssh sshuser@<your-spark-clustername>-ssh.azurehdinsight.netStep 9: Open the consumer.py file and edit the “KafkaBserver” variable. Paste the output of the file you copied on the kafka server and paste it here. It will enable the Spark cluster to listen to kafka stream.

[!NOTE] If you changed the SQL User name during deployment, you need to change the username as well.
Step 10: Now let’s run the sparkinstall script file to install all required libraries on Spark cluster
./sparkinstall.sh
Step 11: Now let’s run the producer-simulator file on kafka server to simulate a stream of records. This should print a set of records as they are streaming. (Ending this would end stop streaming also)
python files/producer-simulator.py
Simultaneously, let’s run the consumer file on Spark server to receive the stream from kafka server
python consumer.py
This file will use Spark streaming to retrieve the kafka data, transform it, run it against the models previously created and saved, then save it to the SQL table we just created. (Ending this would end stop processing the stream also)
Step 12: In a bit (after you see “Collecting final predictions…” and stage progression on the console), the table on SQL database should populate. Check on the SQL Query Editor with query:
select * from UserData
Step 13: Now Let’s setup PowerBI to view this new data. Download the FinalPBI file from the PBI folder. Open the file using PowerBI Desktop.
Now click on the model on the left as shown in the picture below, click on the UserData table and delete from the model.

Click on Get Data from the top ribbon, and choose Azure SQL Database.
Parameters:
servername: <your-server-name>.database.windows.net (full server name)
Database name: Predictions,
“Direct Query”
choose the “UserData” table and click on Load.
You can setup by clicking on change detection in the Modeling pane. Once setup, your report will update every 5 seconds to get fresh data, and should look like this:

Related:
- Read more documentation
- Analyze Data with Interactive Query
- Migrate HDInsight 3.6 to 4.0
- Building Open Source Software (OSS) Analytical Solutions with Azure HDInsight
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments