This article is contributed. See the original author and article here.
It’s been a year since Microsoft acquired Citus Data, and while there have been strange changes such as my team now officially being called “Ninjas”, we still often get unusual and interesting Postgres “puzzles” to solve. If you’re not familiar, Citus is an open source Postgres extension that scales out Postgres horizontally that is now available as Hyperscale (Citus) as part of our managed Postgres service on Azure.
Recently, our friends at ConvertFlow, a long-time Citus customer approached our team with a particularly interesting Postgres challenge. ConvertFlow has what we call a “HTAP” workload, featuring an application that gives marketers a personalized way to guide website visitors to become leads, customers, and repeat buyers. For those of you that are curious, HTAP means that they have a mixed multi-tenant SaaS and also real-time analytics workload multi-tenant SaaS.
The problem: 2 billion rows & ongoing growth meant ConvertFlow would soon face an integer overflow issue
ConvertFlow has a pair of Postgres tracking tables sharded across multiple servers in a Citus database cluster at the heart of their application. A good chunk of their SaaS application workflow either updates or reads from these Postgres tables. ConvertFlow’s usage has shot up over the past few years, so as you can imagine these tables got really big over time. Today, there are two billion rows across the two tracking tables, those tables alone get 40,000 reads a minute, and the number of reads is climbing.
This type of growth, unfortunately, often leads to a problem: integer overflow.
Each of ConvertFlow’s Postgres tracking tables had a bit over 1 billion rows, and each table used an integer primary key that was set to autoincrement. This meant that each table had a row with an integer that was increasing with every row added. Unfortunately, Postgres limits the maximum size of the integer type to 2,147,483,647. This meant that the primary key columns were already roughly half full, and with ConvertFlow’s continued growth, integer overflow would soon become an issue.
Fortunately, Postgres has another numeric data type called bigint, with a limit of 9,223,372,036,854,775,807, or roughly 9 quintillion. While Citus database clusters can get extremely large, we’ve never encountered anything close to hitting the bigint limit.
This realization led us to our solution: if we switch from the integer data type to bigint in our customer’s Postgres tables, we’d be all set. Sounds easy, right?
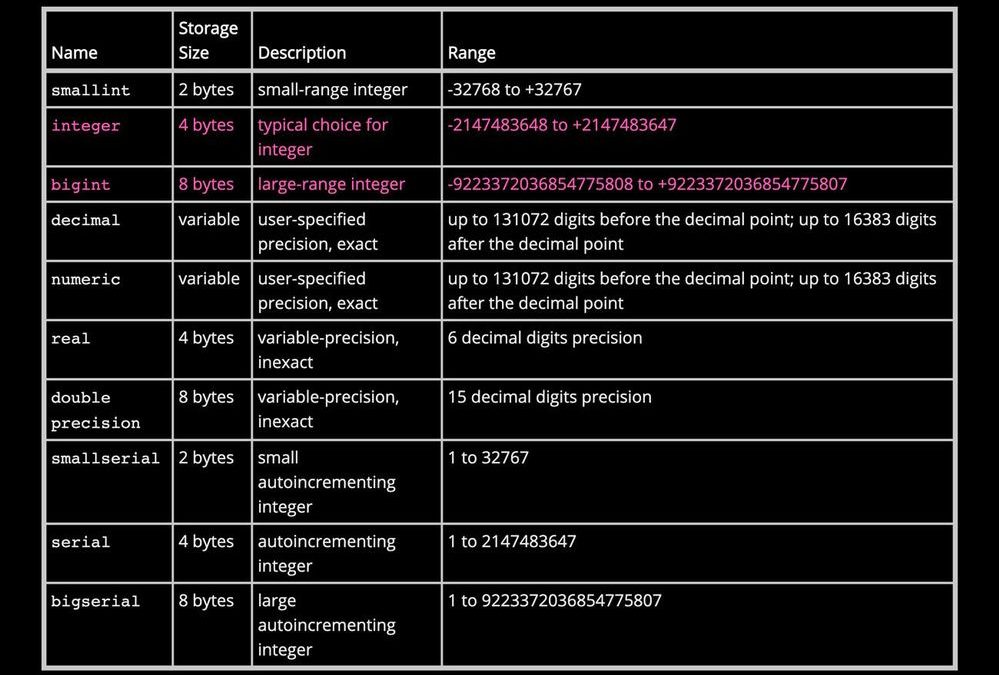
Numeric Types available in Postgres
 From the PostgreSQL documentation chapter on Data Types, the table of built-in Numeric Types
From the PostgreSQL documentation chapter on Data Types, the table of built-in Numeric Types
Numeric Types available in Postgres
More challenges: aggressive Postgres locking might cause too much downtime
Well, one minor detail got in the way here: Postgres locks when changing the type of a column. Specifically, Postgres gets an ACCESS EXCLUSIVE lock, a very aggressive type of lock, when changing types. In Postgres, ACCESS EXCLUSIVE locks prevent updates, inserts, and even reads from going through for the duration of the update. As a result, for all practical purposes changing the Postgres data type would take the application down.
Some quick tests showed that there would be approximately 10 hours of downtime for the change to persist across 2 billion rows. While this is relatively quick given the amount of data, 10 hours was definitely way too long of a maintenance window. So, we devised a plan to address this concern.
The plan: make new BIGINT columns, copy the data to them, and switch over later
The plan started out simply enough. We’d make a new BIGINT column in each of the Postgres tables in the Citus cluster, mirror the data from the existing columns to the new ones, and switch over the application to use the new columns.
This seemed to be a great idea—we could set up a Postgres trigger for new or updated values and slowly do batch updates to copy over the existing values as they came in. To make it even better, we could schedule the batch updates using the open source pg_cron extension, which let us do those batch updates overnight without having to stay up late.
The only maintenance window would occur when we later switched over to using our new Postgres bigint columns. It would definitely be a bit slower, but we’d also have far less locking. In addition, we could avoid periods of high activity by doing batch updates of existing rows. We still had a few months of runway left before we ran out of usable integers, so the time to finish wasn’t an urgent factor yet.
The twist: how to maintain existence of primary keys at all times?
We quickly realized that we’d overlooked a surprising twist. The integer columns were part of the primary keys on the tables in question, and ConvertFlow uses a Rails app, so we had to maintain the existence of primary keys at all times to keep the app happy.
We could drop the primary key in a transaction and make a new one, but with 2 billion rows in the distributed Postgres tables, that was still likely to take an hour or two, and we wanted a shorter maintenance window.
The fix: Postgres’s wonderful ADD table_constraint_using_index
Fortunately, Postgres has another cool feature we could use in this case: ADD table_constraint_using_index. You can use this argument when creating a constraint to promote a unique index to a primary key, which lets Postgres know that the unique constraint is valid. That means that Postgres doesn’t need to do a full table scan to check validity of the primary key. As a result, we could drop the existing primary key and very quickly make a new one using that BIGINT column. While this would still involve a brief lock for the ALTER TABLE to complete, this approach would be much faster. We discussed the idea with ConvertFlow, wrote some Rails migrations, tested everything, and then scheduled a maintenance window.
With everything now figured out, we started. We ended up doing everything in a Rails migration instead of raw SQL, but in the interest of making this more generally applicable, here’s the pure SQL version of what we ran:
-- First, make basic modifications to get the new column added. We've got a composite primary key, so the new constraint has 2 columns in it to match the original.
ALTER TABLE target_table ADD COLUMN column_bigint BIGINT;
ALTER TABLE target_table ADD CONSTRAINT future_primary_key UNIQUE (column_bigint, other_column);
-- Next, ensure that all incoming updates and inserts populate that column:
CREATE OR REPLACE FUNCTION populate_bigint
RETURNS trigger AS
$BODY$
UPDATE target_table SET new.column_bigint=new.original_column;
$BODY$;
CREATE TRIGGER populate_bigint_trigger BEFORE INSERT OR UPDATE ON target_table
FOR EACH ROW
EXECUTE populate_bigint();
-- Now, populate the column for all existing rows. We’re doing this in chunks so we can pause and resume more easily.
UPDATE target_table SET column_bigint = original_column WHERE column_bigint IS NULL LIMIT 10000;
--Repeat last line as needed. We scheduled this using pg_cron so we didn't have to keep running different commands.
-- Now that everything’s caught up, take a few minutes of downtime, and switch over. We’re doing this in a transaction, just in case.
BEGIN;
ALTER TABLE target_table DROP CONSTRAINT original_pkey;
ALTER TABLE target_table ADD CONSTRAINT new_pkey PRIMARY KEY USING INDEX future_primary_key;
END;
tl;dr: Taking it slow meant only 20 minutes of downtime for 2 billion rows.
We ran this, and it worked! It ended up requiring about 20 minutes of downtime, most of which was waiting for long-running transactions to finish and doing testing to make sure we got it all right. This fit very nicely into the maintenance window the ConvertFlow team had planned. What a fantastic improvement over the 10+ hours we had originally estimated, and at every single point in the process we had an easy way to back out if we had missed any details. Success!
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments