This article is contributed. See the original author and article here.
Polyglot Persistence is the concept of using different storage technologies by the same application or solution, leveraging the best capabilities of each component. Azure Data Services support all possible data types and its usages.
In this blog post you will learn more about Polyglot Persistence, the trade-offs of its implementation, and available Azure Data Services to implement it.
The Old Reality
Until the 1990s most companies used a single version of a single database product. No matter the use case or the technical requirements, what prevailed was the company standard and all applications had to adapt to the official database vendor. How many times have you heard that “here in the company we use Oracle (or any other)? Yes, this not distant past is still a reality in many companies, where all the functions of all applications use the same RDMS.
In the following decade, we began to see some diversification, with the emergence of analytical databases, to support BI workloads. But usually it was still tied to a single vendor and to relational databases. Which made a lot of sense, since the data was always structured and “small” if we compare with today’s times. Storage was very expensive, and data normalization was decisive for efficient applications.
The CWMBO Revolution – “Cloud – Web – Mobile – Big Data – Open Source”
The public cloud as we know it today was born in 2006 and revolutionized the IT world. Now it was easy to scale your infrastructure and use software as a service. The licensing mode began to lose space for the subscription model. It was easy to use multi-vendor databases, taking advantage of the product’s best capabilities.
At the same time, the web and mobile popularization was generating gigantic volumes of semi-structured or unstructured data. It was named as Big Data and created the necessity for technologies like Hadoop and NoSQL databases. The relational database was no longer a solution for everything. We just understood another factor of the revolution.
The last factor was the exponential growth of Open Source Software, allowing cheap access to innovative and quality products. And the cloud providers embraced this idea, offering the products in multiple modes and adding valuable support in some cases.
Cloud Native Applications and Polyglot Persistence on Azure
At this point we started to see some Polyglot Persistence in architecture level. Modern Data Warehouses were created using multiple products and services, with the data flowing from the data sources until the best storage option for that data type. We also started to see cloud native applications using principals like server-less, containers, complex event processing (on top of event-based architectures), REST APIs, etc.
That’s when companies to finally break down their monolith systems. Some of them were still running on-prem, some of them were lifted and shifted to IaaS servers running in the cloud. Distributed services were developed by different teams, using the best persistence option for that data type or workload.
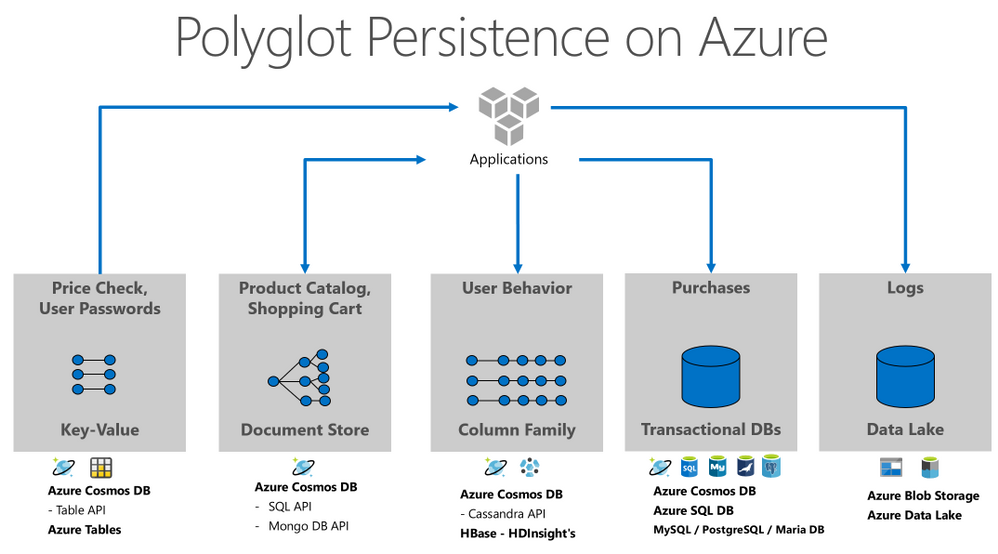
Let us see the example below. The application was sliced in 5 main persistence activities, but we could include more areas like graphs, events, or cache. For each activity we have the typical datatype and the related Azure’s storage options.

The modern data professional needs tools to handle and manage all this data, the trade-offs of polyglot persistence are orchestration and governance. Buck Woody wrote a great blog post about Azure Data Studio, a great tool to support the challenges of this new era.
The Future
Right now, we are seen the growth of concepts that extend the ideas presented in this post, like Data Mesh and micro-frontends. Also, Azure’s teams just released a data product called Azure Synapse Link, that enable HTAP scenarios in your Data Architecture. It allows NoETL analytical solutions, avoiding complexity of ETL jobs and all other data integration activities.
We can say that Big Data is too big to be moved around your environment, what created this in-place analytics, or NoETL solution. Azure Cosmos DB was the first Azure PaaS database to offer this automatically integration, but we can predict that other services will follow the same path.
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments