This article is contributed. See the original author and article here.
This is the final part of my blog series on looking at performance metrics and tuning for ADF Data Flows. I collected the complete set of slides here to download. These are the previous 2 blog posts, which focused on tuning and performance for data flows with the Azure IR and sources & sinks. In this post, I’ll focus on performance profiles for data flow transformations.
Schema Modifiers
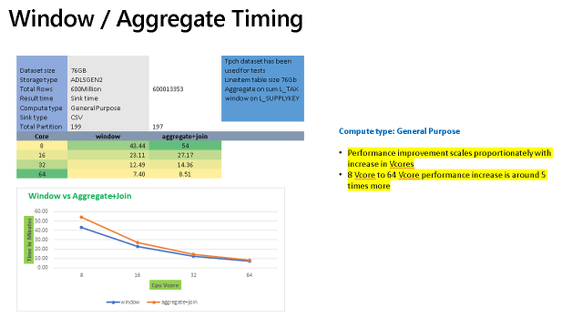
Some of the more “expensive” transformation operations in ADF will be those that require large portions of your data to be grouped together. Schema modified like the Aggregate transformation and Window transformation group data into groups or windows for analytics and aggregations that require the merging of data.

The chart above shows sample timings when using the Aggregate transformation vs. the Window transformation. In both cases, you’ll see similar performance profiles that both gain processing speed as you add more cores to the Azure IR compute settings for data flows. They will also perform better using Memory Optimized or General Purpose options since the VMs for those Spark clusters will have a higher RAM-per-core ratio.
In many situations, you may just need to generate unique keys across all source data or rank an entire data set. If you are performing those common operations in Aggregate or Windows and you are not grouping or generating windows across all of the data using functions such as rowNumber(), rank(), or denseRank(), then you will see better performance to instead use the Surrogate Key transform for unique keys and row numbers, and the Rank transformation for rank or dense rank across the entire data set.
Multiple Inputs/Outputs

The chart above shows that Joins, Lookups, and Exists can all generally scale proportionally as you add more cores to your data flow compute IRs. In many cases, you will need to use transformations that require multiple inputs such as Join, Exists, Lookup. Lookup is essentially a left outer join with a number of additional features for choosing single row or multiple row outputs. Exists is similar to a SQL exists operator that looks for the existence, or non-existence, of values in another data stream. In ADF Data Flows, you’ll see from the chart above, that lookup contains a bit more overhead than the other similar transformations.
When deduping data it is recommended to use Aggregate instead of Join and use Lookups when you need to reduce left outer joins with a single operation, choosing “Any Row” as the fastest operation.

Row Modifiers
Row modifiers like Filter, Alter Row, and Sort, have very different performance profiles. Data flows execute on Spark big data compute clusters, so it is not recommended in most cases to use Sort because it can be an expensive compute operation that can force Spark to shuffle data and reduces the benefit of a distributed data environment.
Alter Row is used to simply tag rows for different database profiles (update, insert, upsert, delete) and Filter will reduce the number of rows coming out of the transformation. Both are very low-cost transformations.
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments