This article is contributed. See the original author and article here.
IoT with Azure SQL
IoT solutions are generally producing large data volumes, from device to cloud messages in telemetry scenarios to device twins or commands that need to be persisted and retrieved from users and applications. Whether we need to store data in “raw” formats (like JSON messages emitted by different devices), to preserve and process the original information, or we can shred attributes in messages into more schematized and relational table structures, it is not uncommon that these solutions will have to deal with billions of events/messages and terabytes of data to manage, and you may be looking for options to optimize your storage tier for costs, data volume and performance.
Depending on your requirements, you can certainly think about persisting less-frequently accessed, raw data fragments into a less expensive storage layer like Azure Blob Storage and process them through an analytical engine like Spark in Azure Synapse Analytics (in a canonical modern data warehouse or lambda architecture scenario). That works well for data transformations or non-interactive, batch analytics scenarios but, in case you instead need to frequently access and query both raw and structured data, you can definitely leverage some of the capabilities offered by Azure SQL Database as a serving layer to simplify your solution architecture and persist both warm and cold data in the same store.
Raw JSON in the database
Azure SQL supports storing raw JSON messages in the database as NVARCHAR(MAX) data types that can be inserted into tables or provided as an argument in stored procedures using standard Transact-SQL. Any client-side language or library that works with string data in Azure SQL will also work with JSON data. JSON can be stored in any table that supports the NVARCHAR type, such as Memory-optimized or Columnstore-based tables and does not introduce any constraint either in the client-side code or in the database layer.
To optimize storage for large volumes of IoT data, we can leverage clustered columnstore indexes and their intrinsic data compression benefits to dramatically reduce storage needs. On text-based data, it’s not uncommon to get more than 20x compression ratio, depending on your data shape and form.
In a benchmarking exercise on real world IoT solution data, we’ve been able to achieve ~25x reduction in storage usage by storing 3 million, 1.6KB messages (around 5GB total amount) in a ~200MB columnstore-based table.
Optimize data retrieval
Storing large amount of data efficiently may not be enough, if then we’re struggling to extract great insights and analysis from that. One of the major benefits of having battle-tested query processor and storage engine is to have several options to optimize our data access path.
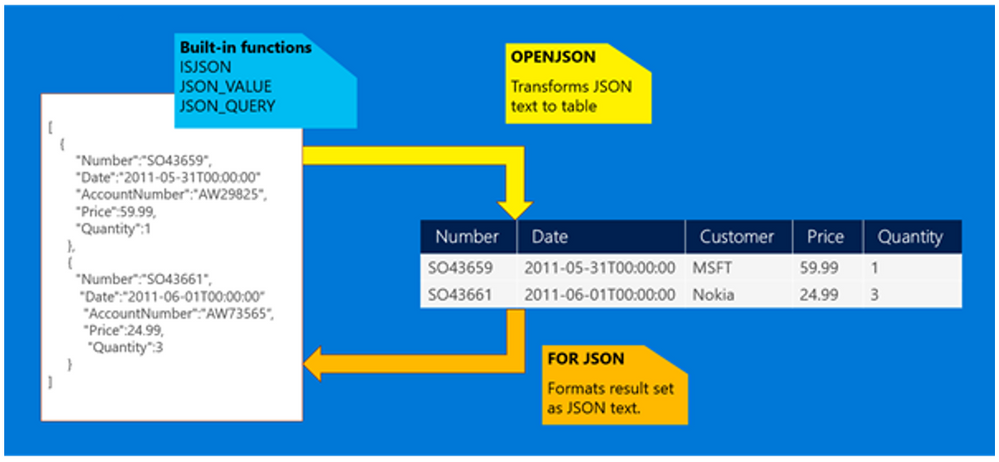
By leveraging JSON functions in Transact-SQL, we can treat data formatted as JSON as any other SQL data type, and extract values from the JSON text to use JSON data in the SELECT list or in a search predicate. As Columnstore-based tables are optimized for scans and aggregations rather than key lookup queries, we can also create computed columns based on JSON functions that will then expose as regular relational columns specific attributes within the original JSON column, simplifying query design and development. We can further optimize data retrieval by creating regular (row-based) non clustered indexes on computed columns to support critical queries and access paths. While these will slightly increase overall storage needs, they will help query processor to filter rows on key lookups and range scans, and can also help on other operations like aggregations and such. Notice that you can add computed columns and related indexes at any time, to find the right tradeoff for your own solution requirements.
Best of both world
In case your JSON structure is stable and known upfront, the best option would be to design our relational schema to accommodate the most relevant attributes from JSON data, and leverage the OPENJSON function to transform these attributes to row fields when inserting new data.

These will be fully relational columns (with optimized SQL data types) that can be used for all sort of retrieval and analytical purposes, from complex filtering to aggregations, and that will be properly indexes to support various access paths. We can still decide to keep the entire JSON fragment and store it in a VARCHAR(max) field in the same table if further processing may be needed.
For other articles in this series see:
- Build your full-PaaS IoT solution with Azure SQL Database
- Ingest millions of events per second on Azure SQL leveraging Shock Absorber pattern
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments