This article is contributed. See the original author and article here.
Fabric Multi-Tenant Architecture
ISVs often face challenges in managing data for multiple tenants in a secure manner while keeping costs low. Traditional solutions may prove costly for scenarios with more than 100 tenants, especially with the common ISV scenario where the volume of trial and free tenants is much larger than the volume of paying tenants.
The motivation for ISVs to use Fabric is that it brings together experiences such as Data Engineering, Data Factory, Data Science, Data Warehouse, Real-Time Analytics, and Power BI onto a shared SaaS foundation.
In this article, we will explore the Workspace per tenant-based architecture, which is a cost-effective solution for managing data for all tenants in Microsoft Fabric, including ETL and reporting.
Challenges of Multi-Tenant Data Solutions
Let us start with the questions that this article will answer:
- What are my options to isolate data between tenants?
- What are the security requirements/regulation that I should consider?
- What are the implications of the various solutions?
Note: You should explore the cost/performance/maintenance aspects of each solution and balance them according to well defined policy that is suited to you as an ISV in specific industry, under specific regulations and upon understanding the sensitivity of the data.
ISVs are reporting that their customers demand solutions that are “fully isolated” in the meaning of data separation between tenants. However, the industry (as well as the regulation) has not defined yet what is “fully isolated.”
The possibility of querying data from multiple tenants is quite common even though it is against the isolated concept. Fabric implementation concepts will be discussed in this article.
Application scenarios:
Microsoft Fabric is designed for multiple application scenarios as defined here.
This article will focus on the typical following two:
1. Data analytics and workflow processing
2. Data gathering, processing, and IoT.
OLTP applications are a native source for Fabric but are not recommended to be the data platform for such systems.
Typical ISVs projects need to ensure that the architecture will support:
- Multi-tenants that need data isolation between different tenants. We will discuss briefly what is data isolation in this document.
- Power BI reporting.
- Performance and cost challenges with relational engine.
- Easy migration to Fabric.
The Workspace approach is well-suited to support all those scenarios.
Terminology
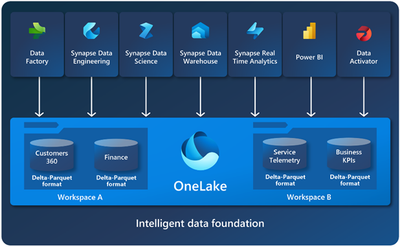
OneLake:
OneLake is a single, unified, logical data lake for your whole organization. For our discussions, all the ISV’s tenants’ data will be hosted on the same OneLake. As you can see from the diagram below, Fabric supports multiple services that can connect to OneLake.
Capacity:
A Microsoft Fabric capacity resides on a tenant. Each capacity that sits under a specific tenant is a distinct pool of resources allocated to Microsoft Fabric. The size of the capacity determines the amount of computation power available.
Workspace:
Workspaces reside within capacities and are used as containers for Microsoft Fabric items. Workspace is the place in OneLake that holds the data.
Within a tenant, you can create any number of workspaces. Workspaces enable various parts of the organization to distribute ownership and access policies. Each workspace is part of a capacity that is tied to a specific region and is billed separately.
Within a workspace, you can create data items and you access all data in OneLake through data items. Fabric stores are like lakehouses, warehouses, and other items in OneLake.
Of course. License considerations must take place. Our assumption is that most ISVs will utilize Capacity License.
Data Storage:
The assumption of this article is that a typical ISV wants to store all the data for all his tenants in a central location (multi-region provisioning might be needed due to end-customer location) in a secure and cost-effective way. This is a repeatable demand that we hear from our ISVs. Fabric can offer a new way to achieve this goal by four concepts (more details provided) in this article:
- One OneLake for all your data
- Tenants’ separation/isolation by workspace
- Affordable storage – Parquet files is the storage format. The price per GB is similar the price of Blob storage in the hot tier..
- Serverless oriented – no need to pay for unused compute resources.
Data acquiring (ETL and/or IoT) and hybrid scenarios will not be discussed in this article.
Fabric Direct Lake
One of the key components is Fabric Direct Lake, which includes a semantic model capability for analyzing large data volumes in Power BI. Direct Lake is based on loading parquet-formatted files directly from a data lake without having to query a Lakehouse endpoint, and without having to import or duplicate data into a Power BI model.
In other words, Direct Lake eliminates the need to load the data to a relational database or to Power BI and uses Direct Lake as a one-step solution to query the data instead of multiple steps. The following figure (not a replacement for reading the full article here) can help us understand the solution:

As shown in the diagram, Direct Lake streamlines the user’s path by eliminating the need to create, maintain, and pay for a separate lakehouse or warehouse, as well as the need to use import or direct query processes. This results in a more efficient and cost-effective solution for analyzing large data volumes in Power BI.
Workspace based Multi-Tenant Architecture
One of the ground building blocks of Fabric is a workspace. Workspaces are containers that are places to collaborate with colleagues to create collections of items such as lakehouses, warehouses, and reports. You can grant permission per workspace (see the security part later), which can be extremely helpful to associate the tenant’s login with the tenant’s workspace and to his workspace only.

As you can see from the diagram, OneLake can utilize the workspaces for tenant isolation.
Advantages of using workspace per tenant approach:
Security | Avoiding the need to manage security between workspaces |
Manageability | The ability to move/delete/archive tenants without any impact on other tenants |
Simplicity | One OneLake per ISV; One workspace per tenant; No service to manage and patch |
Monitoring | Monitor resource usage per tenant easily |
SLA | Ability to give different SLAs to different tenants by provisioning different services according to the tenants’ needs and or budget |
Cost per Tenant | Ability to know (and bill) each tenant’s data size according to usage |
More reading:
- Architect multitenant solutions on Azure
- Architecting multitenant solutions on Azure
- Resources for architects and developers of multitenant solutions
- Better together: the lakehouse and warehouse
Isolation models
Tenant Data Isolation
Due to business, regulation and security considerations, any multi-tenant should ensure that each tenant can access only his data. From a high-level perspective, the solutions that enable us to achieve this granularity are divided into two types:
- Physical separation of the data to separate locations.
- Ensuring that the application will filter the data from the relevant tenants by mechanisms like Row Level Security.
This document discusses the physical separation type only since this type is aligned with Fabric’s architecture.
Shared data
For shared data the suggested usage is to have a separate workspace that will be shared by a shortcut to all the tenants’ environments. If the shared data is managed by a database, you might be able to use mirroring to sync the database to the shared data workspace. Mirroring is in preview now for Cosmos DB, Azure SQL DB and Snowflake. However, SQL Server, Azure PostgreSQL, Azure MySQL, MongoDB and other databases and data warehouses will be coming in CY24.
Features of Fabric that support multitenancy
Capacities and multi-Region
In Fabric you will have only OneLake per the ISV’s tenant. However, you can deploy your system in multiple regions by having capacity defined in each region.
- There is only one OneLake per tenant.
- A tenant can have multiple capacities in one or more regions.
- Any capacity is attached to a specific region.
- A workspace can be assigned to only one capacity.
- Every item stored in a lakehouse/warehouse of a workspace will be stored in the region of the tied capacity.
Multitenancy friendly cost structure
Storage
Delta-Parquet files which are the basic building block in Fabric. Those files charged per volume so the number of workspaces will not affect the cost.
Serverless Service
Fabric is a serverless solution which means that there is separation between storage and compute resources payments.
As you expect, you are paying for the storage you are using and you should try to optimize the size of the storage. Since storage costs are low, the storage cost will not be a significant percentage of your total cloud bill.
For compute, you will pay according to the usage. In the BI environment, the user load is expected to vary and such models will save money.
With classic Fabric implementation, you can skip the need for relational database which usually can be one of the main cloud expenses.
ETL
Most ISVs run ETL per tenant, therefore the cost will be the same.
In rare cases where one ETL process can deal with multiple tenants, a single workspace for all tenants might run with less pipelines and save costs.
Power BI
In Power BI, a workspace per tenant is the best practice. Please read the Develop scalable multitenancy applications with Power BI embedding article for deep discussion. From the Power BI perspective, the limitations are based on the largest workspace size (and not on the total workspace size) as defined here.
Capacity and Chargeback Management
The recommended approach for segregating tenants through distinct workspaces facilitates a frequently requested feature: chargeback support. By allocating separate capacities to each tenant’s workspace (or multiple workspaces), monitoring and accessing data regarding each tenant’s usage becomes straightforward.
Microsoft Fabric concepts and licensing article provides essential guidance for creating a deployment that enables ISVs to implement chargeback mechanisms. This allows for precise billing of end customers based on their actual consumption, streamlining the process and ensuring transparency in usage and cost allocation.
Workspace Security
Granular permissions per tenant
As written above, you can use permission per workspace to ensure tenant’s isolation per workspace. The same mechanism is used to give more granular permissions to specific items inside the users of the tenants (good description can be found here).
Note, the same concept is true for permissions inside a lakehouse or warehouse inside a workspace.
For example, the user Mark-CustomerA might be associated with the CustomerA tenant to see only the data related to his tenant. If you want to give him read access to the Orders data you will define a role named OrdersRead-CustomerA and associate Mark with this role. To define a global role OrdersRead instead is possible but will not be a satisfactory solution.
In Fabric you can give permissions by sharing – see here and here. Detail granular permission discussion is beyond the scope of this document – this document is discussing only the security aspects of the multi-tenant scenario.
Multi-tenants Network security
There is no IP separation nor any other network isolation between workspaces. The good news is that a solution is coming. As stated in What’s new and planned for Administration and governance in Microsoft Fabric, Private Link support is planned for Q2 24 (it is not available now and plans might be changed). The Private Link capability will expand from Power BI to other workloads in phases, including workspace-level support. Once Azure Private Link is configured and public internet access is restricted, all the supported scenarios for that workspace will be routed through private links.
Identity Management
- We strongly recommend using different users per tenant and not letting an application-based security mechanism to be the only authorization gate.
- Please read our Architectural considerations for identity in a multitenant solution.
- In these days, you can even utilize multitenant organization in Microsoft Entra ID which is in preview. Detail discussion of this option is beyond the scope of this article. Some highlights can be found in multitenant organization scenario and Microsoft Entra ID capabilities.
- The importance of those practices us crucial in ensuring robust security.
More reading:
- Security in Microsoft Fabric
- Microsoft Fabric: Workspace access, Item level access, SQL policy and object level security
Cross-workspace
Cross-workspace queries
While the demand to have cross-tenant queries looks like opening the system for a security breach, in real life this demand is quite common.
Here are the typical scenarios:
- ISV level reporting.
- ETL to a data warehouse/data lake.
- Using metadata info and/or external data that is relevant to all tenants without the need to duplicate them to all tenants.
To achieve this ability, you should leverage the SQL analytics endpoint that enables querying of any table and easy sharing.
You will need to create a shortcut pointing to the required databases or tables from the other workspace. More details can be found in Cross workspace sharing and querying.
To avoid potential overriding privacy and regulation policies, you should allow cross-tenant queries only in specific cases. You should design such implementation carefully from both security and architecture aspects.
More reading:
- Tutorial: Create cross-warehouse queries with the SQL query editor
- Querying Lakehouse data from Warehouse in Microsoft Fabric.
Cross-workspace Pipelines
Organizations might separate their data into multi workspaces due to internal security reasons (Separating Gold from Silver/Bronze, according to the data sensitivity).
For other ISVs, the need is even more complex. The data (or at least part of it) comes in a multi-tenant stream and this data should be divided into different single-tenant streams with a minimal effort.
Currently, Fabric does not support this functionality but the ability to enable Cross-workspace Pipelines is in the roadmap.
However, you can clone your data pipelines across workspaces by using the “Save as” button (see here). This makes it easier to develop pipelines collaboratively inside Fabric workspaces without having to redesign your pipelines from scratch. Another solution, based on dynamic content is described here.
Using Cross Workspace Pipelines might simplify the ETL code as well as reduce the expected costs. With proper design, the expected running time of the processes will be better.
Conclusion
If you are an ISV that has multiple tenants, you can use the new Fabric platform to host those tenants. Fabric will help you host the data received from those customers on an isolated basis, paying only for the actual storage that you are using while being able to load the data will all the transformations needed and build a reporting layer for your customers.
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments