This article is contributed. See the original author and article here.
It is our pleasure to announce the release of version 1.0 of .NET for Apache® Spark™, an open source package that brings .NET development to the Apache® Spark™ platform.
The new 1.0 release of .NET for Apache® Spark™ includes the following:
- Support for .NET applications targeting .NET Standard 2.0 (.NET Core 3.1 or later recommended).
- Support for Apache® Spark™ 2.4/3.0 DataFrame APIs including the ability to write Spark SQL. For example:
var spark = SparkSession.Builder().GetOrCreate(); var tweets = spark.Read().Schema("date STRING, time STRING, author STRING, tweet STRING").Format("csv").Load(inputfile); tweets = tweets.GroupBy(Lower(Col("author")).As("author")) .Agg(Count("tweet").As("tweetcount")) .OrderBy(Desc("tweetcount")); tweets.Write().SaveAsTable("tweetcount"); spark.Sql(@"SELECT * FROM tweetcount").show(); - Ability to write Apache® Spark™ applications using .NET user-defined functions (UDFs.) For example:
// Define and register UDF var concat = Udf<int?, string, string>((age, name)=>name+age); // Use UDF df.Filter(df["age"] > 21).Select(concat(df["age"], df["name"]).Show(); - Provides an API extension framework to add support for additional Spark libraries. Currently this includes Linux foundation Delta Lake, Microsoft OSS Hyperspace, ML.NET, and support for Apache Spark’s MLLib functionality
- Performance work and improving both pickling interop and support of Apache® Arrow for moving data between Spark runtime and .NET UDFs. The following are just a few of the contributions we made to the Open Source projects:
- Apache® Arrow: ARROW-4997, ARROW-5019, ARROW-4839, ARROW-4502, ARROW-4737, ARROW-4543, ARROW-4435, ARROW-4503, ARROW-4717, ARROW-4337, ARROW-5034, ARROW-5887, ARROW-5908, ARROW-6314, ARROW-6972, ARROW-6682, ARROW-7516, ARROW-8505, ARROW-8882, ARROW-10238
- Pyrolite (Pickling Library): Improve pickling/unpickling performance, Add a Strong Name to Pyrolite, Improve Pickling Performance, Hash set handling, Improve unpickling performance
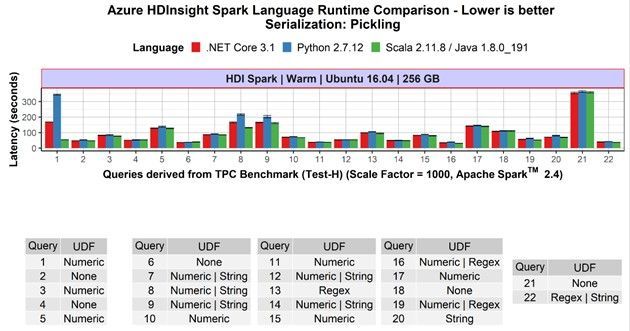
- Competitive performance: .NET for Apache® Spark™ programs that are not using UDFs show the same speed as Scala and PySpark-based non-UDF Spark applications. If the applications include UDFs, the .NET for Apache® Spark™ programs are at least as fast as PySpark programs, often faster. This previous blog post contains more details.

Availability
.NET for Apache® Spark™ is available as an OSS project on the .NET Foundation’s GitHub and can be downloaded from NuGet.
It is built into Azure Synapse Analytics and Azure HDInsight where you can enjoy an out-of-the-box experience. Version 1.0 will be released in these products in the next major release.
.NET for Apache® Spark™ can also be used in other Apache Spark cloud offerings including Azure Databricks and as well as AWS EMR Spark. For on-prem deployments, it offers is multi-platform support for Windows, MacOS, and Linux.
Historical background and how we developed it
About two years ago, we heard an increasing demand from the .NET community for an easier way to build big data applications with .NET instead of having to learn Scala or Python. Thus, we built a team based on members from the Azure Data engineering team (including members of the previous Mobius team) and members from the .NET team and started the “.NET for Apache Spark” open-source project. While we operate the project under the .NET Foundation, we did file Spark Project Improvement Proposals (SPIPs) SPARK-26257 and SPARK-27006 to have the work included in the Apache Spark project directly, if the community decides that is the right way to move forward.
We announced the first public version in April 2019 during the Databricks Spark+AI Summit 2019 and at Microsoft Build 2019, and since then have regularly released updates to the package. In fact we have shipped 12 pre-releases, included 318 pull requests by the time of version 1.0, addressed 286 issues filed on GitHub, included it in several of our own Spark offerings (Azure HDInsight and Azure Synapse Analytics) as well as integrated it with the .NET Interactive notebook experiences.
In addition, we encouraged community participation in the project and have seen a steady increase in both interest in the project and thus the use of .NET with Apache Spark (88 watchers, over 210 forks, and over 180k NuGet downloads) as well as contributions to the project itself, ranging from documentations and samples to providing sophisticated additional capabilities such as Spark’s MLLib integration and Docker images. .
We are deeply grateful to everyone who is helping in making .NET for Apache Spark a success and looking forward to our ongoing collaboration!
Looking into the Future
Of course, shipping version 1.0 is not the end but only the beginning for .NET for Apache® Spark™.
We recently reached out to .NET developers to understand how they use big data and what challenges they face. Most .NET developers want to use languages they are familiar with like C# and F# to build big data projects. It’s clear that support for features like Language Integrated Query (LINQ) is important. The largest obstacles faced include setting up prerequisites and dependencies and finding quality documentation. We’re addressing both, with examples like our community-contributed “ready-to-run” Docker images and a recent wave of updates to the .NET for Spark documentation. We also heard loud and clear that a top priority is supporting deployment options, including integration with CI/CD DevOps pipelines and publishing or submitting jobs directly from Visual Studio. We are continuously updating the project to keep pace with .NET developments, Spark releases, and feature requests such as GroupMap.
What the community is saying
A version 1.0 release would not be complete without some customer testimonials 
I have been working with data and the traditional Microsoft stack for about fifteen years and, over the last three years, have been working with Apache Spark, which meant moving away from C# and towards Scala and Python.
In 2019 when I found out about the .NET for Apache Spark project, I was pretty excited by the thought of bringing the power of Apache Spark to .NET. The project team has welcomed outside contributions to the project, both the documentation, and code from the very start. Due to the way the project team review pull requests and offer guidance, it has been a pleasure to contribute to what I believe will be an exciting project that will help many organizations work effectively with Apache Spark without having to adopt new languages and tooling.
Using functionality from a library like .NET for Apache Spark that you implemented yourself, in a project you are working on always brings a smile to my face. Using .NET for Apache Spark with the full .NET ecosystem and especially unit testing frameworks mean the where I use .NET in a project I can get going faster and concentrate on the actual data processing rather than having to learn Python or Scala and their associated testing and packaging systems.
The rate of change has been really exciting to watch and I am really looking forward to the upcoming v1.0 milestone which is going to help drive adoption of big data within the .NET community, interesting times!
Ed Elliot, Lead Cloud Data Engineer at GFT Group and .NET for Apache® Spark™ contributor
Overall, we enjoy working with Spark.Net. It is easy to learn and new developers do not feel like they are learning yet another new language. We got to write UDF efficiently with our existing .Net library, especially useful when we had to parse and pre-process JSON data. We also modeled our .NET for Spark project with C# programming model such as dependency injection, extension methods and inheritance, making our code much more structured and extensible.
Microsoft Dynamics 365 Commerce, uses .NET for Apache Spark in production to process terabytes worth of data per day
We build ML/Deep models on top of substrate data to infuse intelligence to Office 365 products. Our data resides in Azure Data Lake Storage, which we cook/featurize and in turn feed into our ML models. Given that our business logic e.g., featurizers, tokenizers for normalizing text, are written in C#, .NET for Apache Spark is an ideal candidate for our workloads. We leverage .NET for Spark to run those libraries at scale. Our experiences with .NET for Apache Spark have been very promising and stable. The highly vibrant community helps us iterate at the agility we want.
Microsoft Office 365 Search, Assistant & Intelligence, uses .NET for Apache® Spark™ in production to process ~10s of terabytes worth of data per day
Call to Action
We are looking forward to seeing you develop your Apache Spark programs with .NET on your favorite Spark platform.
Start out with browsing our online .NET for Apache Spark documentation, take the tutorial Get started with .NET for Apache Spark, and submit jobs to run on Azure and analyze data in real-time notebooks using .NET for Apache Spark with Azure Synapse Analytics.
Then let us know about your experience with .NET for Apache® Spark™: If you have feedback and requests or questions you can file them as a Github issue at https://github.com/dotnet/spark/issues. You can also reach out to us on twitter with the hashtag #DotNetForSpark. If you would like your favorite Spark cloud provider to include .NET for Apache® Spark™ out of the box, please point them to the project. We are happy to engage and help them to include it.
Finally, don’t miss our presentation describing this major release in the upcoming .NET Conf 2020: “The Missing Piece – Diving into the World of Big Data with .NET for Apache Spark”!
Acknowledgements
The team responsible for the major release consisted of the following members:
Engineering: Terry Kim, Steve Suh, Niharika Dutta, Andrew Fogarty, Elva Liu, Jon Sequeira, Diego Colombo, Kevin Ransom, Stephen Toub, Eric Erhardt, Prashanth Govindarajan, Rahul Potharaju
Program Managers: Michael Rys, Jeremy Likness, Maria Nagagga, Brigit Murtaugh
Samples & Documentation: Luis Quintanilla
Marketing: Beth Massi, Sarah Cook, Kaiser Larsen
In addition to this, we also had tremendous help from two external community members: Ed Elliot, Martin Kandlebinder.
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments