This article is contributed. See the original author and article here.
Welcome to the “March Ahead with Azure Purview” blog series that helps you to maximize your Azure Purview trial/pilot/PoC with best practices, tips and tricks from product experts. In the previous blog post, we covered setting up the appropriate control plane and data plane roles to manage Azure Purview. In this post, we’ll roll up the sleeves and walk through the process of scanning data. Let’s get started!
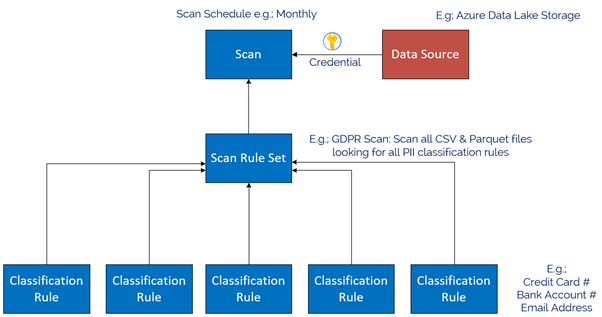
The Azure Purview Data Map enables you to create a holistic knowledge graph of your data residing in on-premises, multicloud and SaaS data stores via automated scanning and classification. The anatomy of an Azure Purview scan involves a number of key components illustrated in this diagram;
Starting at the bottom, we have Classification rules. Out of the box, Purview provides rules for common Personally Identifiable Information (PII) data such as Name, Email Address, Social Security Number and a heap of others. These are known as “System Rules”. We can access the System Rules by clicking Classification Rules in the Management Centre of Purview Studio.

Beyond these, you can create your own custom classification rules using Regular Expressions and Dictionary Lists. Click on the Custom tab and then click + New to add a new Custom Rule. An example below is for Australian Phone Numbers.

Once we have our Classification Rules, we group them together into Scan rule sets, used by a scan to look for certain data points. Out of the box, Purview has default Scan Rule Sets for each Source Type. For example, the default Scan Rule Set for Azure Data Lake Storage Gen 2 will scan all common file types (csv, json, parquet etc) looking for all out of the box System Rules.

You can create your own Scan Rule Sets should you wish to customize how scans are performed. For example, you may only wish to scan certain file types, and include custom classification rules and/or ignore some System rules. This allows you to fine tune the time scans take, and therefore control the cost of Purview. Like Classification Rules, to create a custom Scan Rule Set, click on the Custom tab and then + New.
In the example below, we limit the file types for our custom Scan Rule Set to Parquet and CSV and choose specific classification rules to include in the scan.


Now we have our Classification Rules and Scan Rule Sets, let’s create a data source to scan! On the Sources tab, we click Register, and choose a data source type. Today we natively support a range of Azure data sources such as Azure SQL Database, Power B I and Data Lake Storage, along with preview support for Oracle, SAP and Teradata . This list will expand as we move towards General Availability. Note that for Power BI and 3rd Party data sources such as Oracle, it’s a meta-data only scan. For these sources, we don’t use the classification rules during scanning to detect data such as email addresses.

In my case, I chose Azure Data Lake Storage Gen2, so I’m asked for the account details, such as Subscription, Storage Account Name and what collection on the Data Map I want to register this source into, for example, EnterpriseDataLake.

Once registered, I can now perform a scan of the source by clicking the scan icon.

The first thing I need to do is choose what credentials Purview will use to scan the source. In the example above, I’m using the Purview Managed Service Identity (MSI), so I would need to grant the MSI permissions to read the storage account.
Let’s say my data source was Azure SQL Database, and I wanted to use a username and password, instead of the Purview MSI. In this case, I can choose to create a new credential and use Purview’s integration with Azure Key Vault to securely reference credentials from there.

Depending on the Data Source, the next step asks for the scan scope. In the case of a Data Lake storage account, it might be to select which folders to scan or for a SQL Database, which tables to scan. After this, you choose the Scan Rule Set, as we covered above. In this example I’m choosing my Custom Scan Rule set.

The final step is to choose the scan schedule, which can be either recurring, or a Once-off scan.

And that’s it! The scan is now scheduled to execute per your instructions. You can view the scan status by clicking View details button in the Data Map.

The Details screen shows the scan history and the number of assets scanned and classified.

Once your scan completes, you can browse the assets from the home page, using either the Search bar, or the Browse Assets button.

Depending on the source, the scan setup process varies, for example, On-Premises SQL Server, AWS S3, Teradata, Oracle, SAP S/4HANA and SAP ECC. And be sure to checkout this blog post, which covers additional information on scanning, including Resource sets and scanning scale.
Finally, we’ve encapsulated some important Purview best practices here covering stakeholder management, deployment models and platform hardening.
Happy scanning!
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments