This article is contributed. See the original author and article here.
Hello folks,
Bruno Gabrielli here again.
While there are lots of good resources about writing Log Analytics queries and many blog posts have been written, today I would like to point your attention to something that I am frequently seeing on 99% of my Azure Log Analytics customers.
It is about a very simple, but most often under evaluated, aspect of writing queries: query performance also referred as query speed or query efficiency. I will give you my point of view using a series-of posts. Welcome to part 1  .
.
Let me quickly spend some words on the query language behind Azure Log Analytics. The language was first conceived when a service codenamed Kusto was first launched internally at Microsoft in 2014. This service, now available to everyone as Azure Data Explorer, introduced among its many components the Kusto Query Language (KQL). Eventually, the service kept growing and powering more and more services, including the service today known as Azure Monitor Logs (formerly known as OMS, and Azure Log Analytics). As you can imagine, this journey was not only a simple rename but also included enhancements in the number of commands, functions, operators, etc. as well as performance and scalability improvements. Nowadays, it is a very powerful query language with lots of good features and functionalities.
Among all, the 2 things I appreciate the most in this language are: the use of pipelines (like in PowerShell; see Understanding pipelines) and a set of commands that are instantly familiar to anyone who has used languages such as SQL. This means to me that if you have even a basic understanding of SQL Syntax, you start with an advantage (see SQL to Kusto query translation) . If you wish, you can read more about the query language on the Overview documentation page.
I want to stress that understanding the use of pipelines is fundamental to the creation of “efficient” queries. If you went through the pipelines article above, you are now familiar with the concept that pipelines are used to pass commands’ output, or in this case the dataset, to the next command. With that clear in mind, let me ask you a question and, at the same time, give you food for thought: what happens if you pass a big amount of data to the next command and then to the next and so on? Simple answer: the commands will be taking more time than necessary to complete because they will have to process the entire amount of data passed by the previous command(s) which include useless data.
I think we definitely agree on the fact that probably there is no single correct way of writing queries, but that there are for sure some not optimized ways of doing it. For instance, what do you think about doing a search on all tables or not filtering against time as first thing in your query? I tried myself experimenting these best-practices and found out the huge benefit out of them. In particular the first query was very time consuming and ran longer than expected from a platform like Azure. But it is not Azure fault; it’s actually our fault not following them! Know your data first!!!
That means that we should avoid as much as possible production queries that:
- Use the search command to search the entire workspace.
- Do not filter enough (remember to filter against time first).
in favor of being selective with the data we need and applying filters pipeline after pipeline.
The secret is exactly in the table selection as well as in the filtering since each pipeline will pass a smaller dataset to the next, making the rest of the query more and more efficient. You got it! We can reduce the amount data upfront by selecting the right table(s) and we can reduce even more by cutting useless data by filtering.
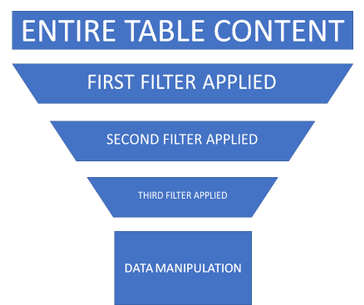
Using the funnel approach represented below, you surely notice that by selecting the right table and by filtering out pipeline after pipeline, the effective data manipulation will happen on a smaller amount of data. This will make the query much more efficient and the underlying engine working faster as we all expect. Remember that, even if scalability is not even a point in Azure, if we all run poor-written queries we all suffer the consequences.

So, coming back to the bad examples:
- Using the search operator searching the entire workspace means that query engine will scan each and every table and column which is very bad.
- Not using good filters will make a dataset bigger than needed/expected to be passed along to the next pipeline.
If what I explained so far makes sense, you’ll discover that the gotcha is: you should know how your data looks like and should, as much as possible, never write a query for production environments using the 2 approaches above.
To prove what I am saying, I am going to give you some examples of what happens when not following the above mentioned best-practices:
- Scenario #1: Searching the entire table:
search “26401”
vs
SecurityEvent | where EventId == “26401”
to search for an event ID with number 26401. The result screenshots below show the 2 queries returning the same number of records but taking a considerable different amount of time. You can easily compare the execution time: ~18 secs compared to ~5 secs.


- Scenario #2: Always filter by time first, either by
- using the built-in Time Range picker:
Event | where EventID == 7036 | where Computer == “SC-DC01.Contoso.Local”

or using the where clause directly in the query:
Event | where TimeGenerated > ago(7d) | where EventID == 7036 | where Computer == “SC-DC01.Contoso.Local”

TIP: Time Range picker and where clause behave the same. The only advantage using the where clause is that you can define more intervals compared to the list offered by the Time Picker. The screenshots above, show the method in in action.
Instead of doing this after other filters
Event | where EventID == 7036 | where Computer == “SC-DC01.Contoso.Local” | where TimeGenerated > ago(7d)

to search for EventID 7036 received from a computer called SC-DC-01.Contoso.Local in the necessary amount of time (i.e. last 7 days).
You can easily notice they are returning the same number of records (I precisely counted them using a different query and they were 272) running for an interesting different amount of time (~0.5 secs compared to ~1.2 secs).
Considering that I am using my lab workspace which contains less than 9GB of data, would you image how much time can you save on a workspace of 1TB? And how much time can we save, and what benefit can we get altogether by running well written queries?
I leave you reflecting on this and making your calculation .
Thanks,
Bruno.
Disclaimer
The sample scripts are not supported under any Microsoft standard support program or service. The sample scripts are provided AS IS without warranty of any kind. Microsoft further disclaims all implied warranties including, without limitation, any implied warranties of merchantability or of fitness for a particular purpose. The entire risk arising out of the use or performance of the sample scripts and documentation remains with you. In no event shall Microsoft, its authors, or anyone else involved in the creation, production, or delivery of the scripts be liable for any damages whatsoever (including, without limitation, damages for loss of business profits, business interruption, loss of business information, or other pecuniary loss) arising out of the use of or inability to use the sample scripts or documentation, even if Microsoft has been advised of the possibility of such damages.
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments