This article is contributed. See the original author and article here.
Hello readers,
Bruno Gabrielli here again and today I want to welcome you on the Making Azure Data Explorer Queries More Efficient – Part 2.
In Making Log Analytics Queries More Efficient – Part 1 I started discussing about one of the most common scenario with customer’s created queries: query performance also referred as query speed or query efficiency. in the same post, I quickly introduced/covered concepts such as:
- Pipelines (like in PowerShell; see Understanding pipelines)
- Query language on the Overview
- Query best practices
Today I would like to go more in depth spreading the word from , Principal Program Manager in the Azure Monitor, about query performance DOs and DONTs.
First and foremost, let me re-emphasize the importance of early filtering out your record by time. This will make your queries faster every time and in any case. As an additional note I would like to underline that with small datasets you might not see such a big performance improvements. Running poor written queries on datasets with more than 100M records is where you hit performance issues.
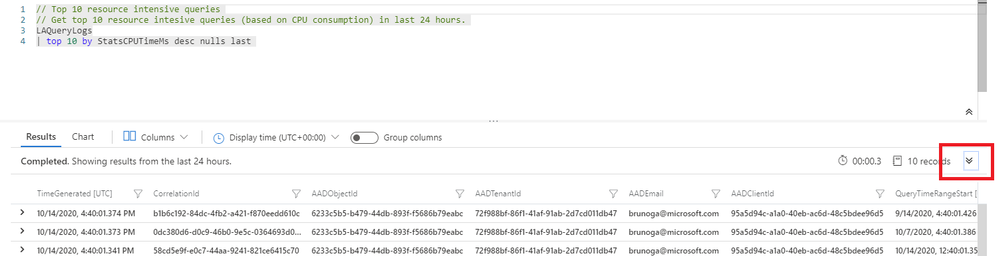
Second, I would like to focus your attention on a built-in feature about query performance awareness: the Query performance pane. This feature is embedded in the Log Analytics portal and it is giving you the statistics for any single query you run from there. You can access it directly from the query result pane by clicking the down arrow:

This expands the corresponding panel containing lots of very useful and important info such as below:

Then, let’s move on with something important about using string operators in your queries. The list of available string operators is huge, but there are a couple of things to remember:
- All operators which use has (has_cs, has_any, hassuffix, etc), search on indexed terms of four or more characters, and not on substring matches. A term is created by breaking up the string into sequences of ASCII alphanumeric characters.
- For better performance, when there are 2 operators that do the same task, DO use the case-sensitive version:
- DO use == instead of =~.
- DO use in instead of in~.
- DO use contains_cs instead of contains.
With all the above said, for faster results, if you’re testing for the presence of a symbol or alphanumeric word that is bound by non-alphanumeric characters, or the start or end of a field, DO use has, has_any or in. has and has_any work faster than contains, startswith, or endswith and can give you much more performance improvements.
If you really need to perform case-insensitive comparisons, DONT use tolower(Col) == “lowercasestring“. DO use the =~ Kusto operator in this case.
The 2 images below, show the same query. The first one is about using the recommendations above:

The second one is about not:

Next one is about using values contained in collected fields. The recommendation here is to materialize the given column at ingestion time whenever possible. Think about the case of custom ingestion using HTTP Data Collector API. Creating the specific field(s) with the necessary value(s), will make you pay only once for the extraction.
The following is a part of a PowerShell script that I created for testing the HTTP Data Collector. You can clearly see that at lines 63 I am parsing the Organizational Unit ($ouResult variable) that I DO later use at line 65 as materialized field value:

Moving on, what about analyzing or manipulating the same data/value(s) more than once in the same query? DO use the materialize() function? Sticking with the public documentation description of this function, it allows caching a subquery result during the time of query execution in a way that other subqueries can reference the partial result. That should clarify enough the way this function works. Using cache has always resulted to be faster than reading data.
In this screenshot there’s the DO approach together with the query performance data and returned data:

Here we have the same concept created using the DONT approach.

Despite the 2 queries returned exactly the same dataset, the latter was more expensive in term of performance for the underlying query engine and it took more time to return you the whispered data. Once again: the bigger your dataset is, the greater performance improvements you’ll get.
When using materialize there are things you should always consider:
- Materialize cache size limit is 5Gb.
- The limit is applied per cluster node and to all the same queries running in parallel.
- Reaching the cache limit will force query execution to be aborted with an error.
Did I make you curious enough?
That is exactly what I wanted  . Now you can read all this and even more about query best practices at Query best practices and Optimize log queries in Azure Monitor official Microsoft documentation pages.
. Now you can read all this and even more about query best practices at Query best practices and Optimize log queries in Azure Monitor official Microsoft documentation pages.
Thanks for reading,
Bruno.
Disclaimer
The sample scripts are not supported under any Microsoft standard support program or service. The sample scripts are provided AS IS without warranty of any kind. Microsoft further disclaims all implied warranties including, without limitation, any implied warranties of merchantability or of fitness for a particular purpose. The entire risk arising out of the use or performance of the sample scripts and documentation remains with you. In no event shall Microsoft, its authors, or anyone else involved in the creation, production, or delivery of the scripts be liable for any damages whatsoever (including, without limitation, damages for loss of business profits, business interruption, loss of business information, or other pecuniary loss) arising out of the use of or inability to use the sample scripts or documentation, even if Microsoft has been advised of the possibility of such damages.
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments