This article is contributed. See the original author and article here.
Scientific computing has long relied on HPC systems to accelerate scientific discovery. What constitutes an HPC system has continued to evolve. Access to computing keeps getting democratized and HPC is no longer limited to multi-billion dollar government laboratories and industries who can afford the infrastructure. Anyone with access to the Internet can now easily leverage the ubiquitous cloud for their computing task du jour! Azure natively supports HPC by providing hardware suitable for high performance computing needs together with software infrastructure to make it easy to harness these resources. In this post, we focus on one such Azure infrastructure component, Azure Batch, and see how we can be used to support a common use-case: data browser with interactive 3D visualization support.
Use-Case: the problem statement
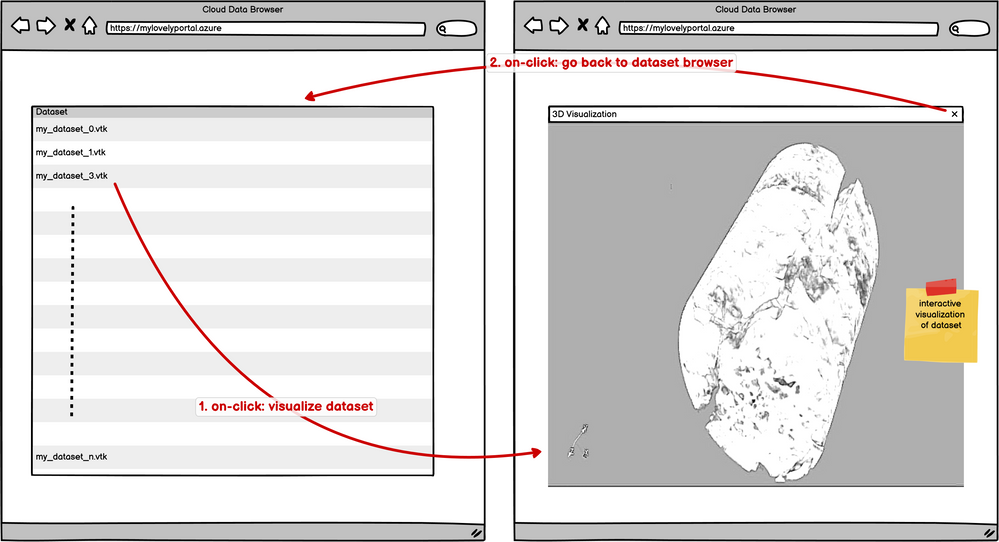
Recently, a customer came to us with an interesting use-case. They wanted to provide their users with an interactive data browser. The datasets are HPC simulation and analysis results which can easily be several gigabytes in size. They wanted to present their users with a web app where users can browse the datasets and then select any of the datasets to interactively visualize it with some canned visualizations.
Variations of this use-case are a very common request in the scientific computing world so let’s generalize (and perhaps simplify) the problem. We want to develop the following web application:
Design Considerations
A few things to qualify the problem and help guide our design choices.
- We want to a scalable solution. Of course, we can set all of this up on a workstation and expose that to the world wide web, however not only is that scary (for security reasons) but also not scalable. We want this to scale no matter how many users are accessing the portal at the same time.
- The datasets are large and require processing before they can be visualized. Hence, we want a remote rendering capable system where the rendering can happen on remote computing resources, rather than the browser itself.
These requirements help us make the following design choices:
- Azure Batch provides us with the ability to allocate (and free up) compute resources as and when needed. We can setup the web app to submit jobs on Azure Batch for visualizing datasets and then Batch can allocate those jobs to nodes in a node pool that can be setup to auto-scale using fancy rules, as needed. This frees us from having to do any management of the nodes in the pool such as setting them up, ensuring they have access to appropriate storage to read the datasets, etc. Batch takes care of that in addition to providing us with tools for monitoring, debugging and diagnosing issues.
- For visualization and data processing, we use ParaView. Together with trame, ParaView makes it easy for us to develop a remote-rendering capable custom web applications that offer all the sophistication and flexibility available in the desktop app. Thus we can easily develop complex data analysis pipelines to satisfy the specific user requirements. trame enables use to access the visualization viewport through a web browser using web sockets.
Deploying the resources
One of the first steps when dealing with cloud computing is deploying the resources necessary on the Cloud. Infrastructure as Code (IaC) refers to the ability of deploying the resources needed and configuring them programmatically. As we go about building our HPC environment in the Azure Cloud, there are many ways to do it. We can use the Azure Portal to setup the system interactively. We can use Azure CLI to script the setup. We can also use domain-specific languages like Terraform or Bicep to define and deploy the infrastructure. For this post, we use Bicep which is a language for declaratively defining the Azure resources. For deploying the Bicep specifications and for other operations like populating datasets, we use Azure CLI.
All the resources needed for this demo can be deployed using the bicep code available in this Github repository. The readme goes over the prerequisites and the detailed steps to deploy all necessary resources. The project includes several different applications. The demo we cover this post is referred to as trame. Ensure you pass enableTrame=true to the `az deployment sub create ….` command to deploy the web application.
Demo in action
Once the deployment is successful, follow the steps described here to upload datasets to the storage account deployed. Finally, you should be able to browse to the URL specific to your deployed web app and start visualizing your datasets! Here’s a short video of the demo in action:

Architecture
Let’s dive into the details on how this is put together. Of course, there’s no one way to do this. Discussing the details of the resources and their configuration should help anyone trying to adapt a similar solution for their specific requirements.
Here’s a schematic of the main Azure resources deployed in this demo.

App Service: This the Azure resource that hosts our main web application. As described in the initial sections, we want our web app to let the user browse datasets and then visualize them. Thus, the web application has two major roles: list datasets, and start/stop visualization jobs. For first role, the web app needs to talk with the storage account on which all the datasets are stored to get the list of available datasets. For the second, the web app needs to communicate with the Batch service to submit jobs/stop jobs etc. In this demo, we decided to write this web app using node.js. The source code is available here. The app uses Azure JavaScript SDK to communicate with the storage account and batch service. The web app also has another role that is a little less obvious: it acts as communication proxy to communicate with the visualization web servers running on the compute nodes in the batch pool. This will become clear when we discuss the Batch resource.
Batch: This is the Azure Batch resource that orchestrates the compute node pools, job submission, etc. Batch takes care of managing all the compute nodes that are available for handling all the visualization requests. When the user “clicks” on a dataset, the web app uses Azure Batch JavaScript API to communicate with the Batch service and request it to start a job to visualize the corresponding dataset. Batch takes care on mounting the storage account on all compute nodes in the pool when they are initialized thus any process running on the compute nodes can access the datasets. The visualization job, in our case, is a simple Python application that uses ParaView/trame APIs to visualize the data. The application, named vizer, is available in this Github repository. When launched with a dataset filename passed on the command line, vizer starts up a Python web-server that one can connect to access the visualization. vizer is running on one of the compute nodes in the pool. The compute nodes in the pool are not accessible from the outside network. Thus, there’s no direct way for the user to connect to this internal visualization web-server. This is why we need the web app deployed in our outward facing app service to also act as a proxy. When a visualization web-server is ready, the main web app creates a iframe that proxies to this internal visualization web-server thus making the visualization accessible by the user. Since trame uses websockets, we need to ensure that this proxy supports websocket proxying as well. Luckily, node.js makes this very easy for us. Look at the web app source code for details on ho this can be done. For simplicity, the demo doesn’t add any additional authorization for the proxying. For production, one should consider adding authorization logic to avoid any random user from accessing any other users visualization results.
Container Registry: Azure Container Registry is used to store container images. In this demo, we containerize both the main web app and the visualization application, vizer. It’s not necessary to use containers, of course. Both App Service and Batch can work without containers, if needed. Containers just make it easier to setup the runtime environments for our demo.
Key Vault: Key Vault is generally used to store secrets and other private information. In this demo, we need the Key Vault for the Batch resource. Batch uses the Key Vault to store certificates etc. that is needs for setting up the compute nodes in the pools.
Wrapping up
As we can see, it’s fairly straight forward to get a interactive visualization portal setup using Azure and ParaView. For this demo, we tried to keep things simple and yet follow best practices when it comes to public access to resources in the cloud. Of course, for a production deployment one would want to add authentication to the web app, along with autoscaling for batch pool and add smarts for resource cleanup and fault tolerance to the web application, etc. One thing we have not covered in this post is how to use Azure’s HPC SKUs and ParaView’s distributed rendering capabilities and GPUs for processing massive datasets. We will explore that and more in subsequent posts.
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments